1.22 feature blog for api server tracing (#28991)
* 1.22 feature blog for API server tracing * Add initial draft of descriptive tracing portions * demo demo * Apply suggestions from code review Co-authored-by: Chris Negus <cnegus@redhat.com> * address comments * address comments and grammar * Add more explanation to the Demo section; add conclusion * Update content/en/blog/_posts/2021-08-06-api-server-tracing.md Co-authored-by: Punya Biswal <punya@google.com> * address comments * address feedback * update alt text * Update content/en/blog/_posts/2021-08-06-api-server-tracing.md Co-authored-by: Rey Lejano <rlejano@gmail.com> * Rename 2021-08-06-api-server-tracing.md to 2021-09-03-api-server-tracing.md * update alt text on first image * better alt text. Co-authored-by: David Ashpole <dashpole@google.com> Co-authored-by: Chris Negus <cnegus@redhat.com> Co-authored-by: Punya Biswal <punya@google.com> Co-authored-by: Rey Lejano <rlejano@gmail.com>pull/29539/head
parent
0e4cdf227a
commit
6dd696487a
|
|
@ -0,0 +1,67 @@
|
|||
---
|
||||
layout: blog
|
||||
title: 'Alpha in Kubernetes v1.22: API Server Tracing'
|
||||
date: 2021-09-03
|
||||
slug: api-server-tracing
|
||||
---
|
||||
|
||||
**Authors:** David Ashpole (Google)
|
||||
|
||||
In distributed systems, it can be hard to figure out where problems are. You grep through one component's logs just to discover that the source of your problem is in another component. You search there only to discover that you need to enable debug logs to figure out what really went wrong... And it goes on. The more complex the path your request takes, the harder it is to answer questions about where it went. I've personally spent many hours doing this dance with a variety of Kubernetes components. Distributed tracing is a tool which is designed to help in these situations, and the Kubernetes API Server is, perhaps, the most important Kubernetes component to be able to debug. At Kubernetes' Sig Instrumentation, our mission is to make it easier to understand what's going on in your cluster, and we are happy to announce that distributed tracing in the Kubernetes API Server reached alpha in 1.22.
|
||||
|
||||
## What is Tracing?
|
||||
|
||||
Distributed tracing links together a bunch of super-detailed information from multiple different sources, and structures that telemetry into a single tree for that request. Unlike logging, which limits the quantity of data ingested by using log levels, tracing collects all of the details and uses sampling to collect only a small percentage of requests. This means that once you have a trace which demonstrates an issue, you should have all the information you need to root-cause the problem--no grepping for object UID required! My favorite aspect, though, is how useful the visualizations of traces are. Even if you don't understand the inner workings of the API Server, or don't have a clue what an etcd "Transaction" is, I'd wager you (yes, you!) could tell me roughly what the order of events was, and which components were involved in the request. If some step takes a long time, it is easy to tell where the problem is.
|
||||
|
||||
## Why OpenTelemetry?
|
||||
|
||||
It's important that Kubernetes works well for everyone, regardless of who manages your infrastructure, or which vendors you choose to integrate with. That is particularly true for Kubernetes' integrations with telemetry solutions. OpenTelemetry, being a CNCF project, shares these core values, and is creating exactly what we need in Kubernetes: A set of open standards for Tracing client library APIs and a standard trace format. By using OpenTelemetry, we can ensure users have the freedom to choose their backend, and ensure vendors have a level playing field. The timing couldn't be better: the OpenTelemetry golang API and SDK are very close to their 1.0 release, and will soon offer backwards-compatibility for these open standards.
|
||||
|
||||
## Why instrument the API Server?
|
||||
|
||||
The Kubernetes API Server is a great candidate for tracing for a few reasons:
|
||||
|
||||
* It follows the standard "RPC" model (serve a request by making requests to downstream components), which makes it easy to instrument.
|
||||
* Users are latency-sensitive: If a request takes more than 10 seconds to complete, many clients will time-out.
|
||||
* It has a complex service topology: A single request could require consulting a dozen webhooks, or involve multiple requests to etcd.
|
||||
|
||||
## Trying out APIServer Tracing with a webhook
|
||||
|
||||
### Enabling API Server Tracing
|
||||
|
||||
1. Enable the APIServerTracing [feature-gate](https://kubernetes.io/docs/reference/command-line-tools-reference/feature-gates/).
|
||||
|
||||
2. Set our configuration for tracing by pointing the `--tracing-config-file` flag on the kube-apiserver at our config file, which contains:
|
||||
|
||||
```yaml
|
||||
apiVersion: apiserver.config.k8s.io/v1alpha1
|
||||
kind: TracingConfiguration
|
||||
# 1% sampling rate
|
||||
samplingRatePerMillion: 10000
|
||||
```
|
||||
|
||||
### Enabling Etcd Tracing
|
||||
|
||||
Add `--experimental-enable-distributed-tracing`, `--experimental-distributed-tracing-address=0.0.0.0:4317`, `--experimental-distributed-tracing-service-name=etcd` flags to etcd to enable tracing. Note that this traces every request, so it will probably generate a lot of traces if you enable it.
|
||||
|
||||
### Example Trace: List Nodes
|
||||
|
||||
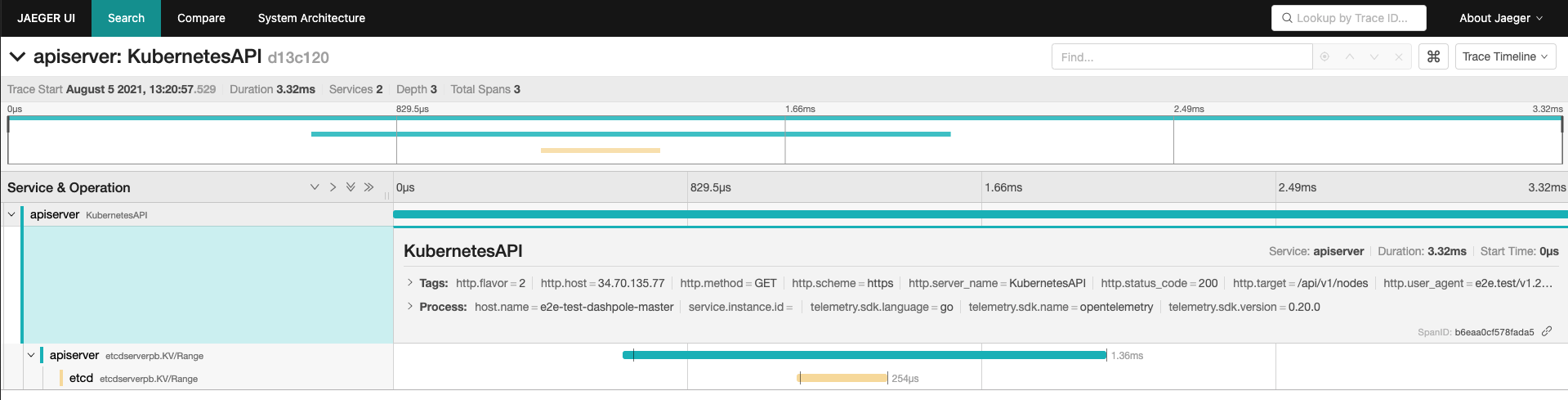
I could've used any trace backend, but decided to use Jaeger, since it is one of the most popular open-source tracing projects. I deployed [the Jaeger All-in-one container](https://hub.docker.com/r/jaegertracing/all-in-one) in my cluster, deployed [the OpenTelemetry collector](https://github.com/open-telemetry/opentelemetry-collector) on my control-plane node ([example](https://github.com/dashpole/dashpole_demos/tree/master/otel/controlplane)), and captured traces like this one:
|
||||
|
||||
|
||||
|
||||
The teal lines are from the API Server, and includes it serving a request to `/api/v1/nodes`, and issuing a grpc `Range` RPC to ETCD. The yellow-ish line is from ETCD handling the `Range` RPC.
|
||||
|
||||
### Example Trace: Create Pod with Mutating Webhook
|
||||
|
||||
I instrumented the [example webhook](https://github.com/kubernetes-sigs/controller-runtime/tree/master/examples/builtins) with OpenTelemetry (I had to [patch](https://github.com/dashpole/controller-runtime/commit/85fdda7ba03dd2c22ef62c1a3dbdf5aa651f90da) controller-runtime, but it makes a neat demo), and routed traces to Jaeger as well. I collected traces like this one:
|
||||
|
||||
<img width="1440" alt="Jaeger screenshot showing API server, admission webhook, and etcd trace" src="https://user-images.githubusercontent.com/3262098/128613167-e7a14cdf-5635-422f-9fd8-f32744ce639d.png">
|
||||
|
||||
Compared with the previous trace, there are two new spans: A teal span from the API Server making a request to the admission webhook, and a brown span from the admission webhook serving the request. Even if you didn't instrument your webhook, you would still get the span from the API Server making the request to the webhook.
|
||||
|
||||
## Get involved!
|
||||
|
||||
As this is our first attempt at adding distributed tracing to a Kubernetes component, there is probably a lot we can improve! If my struggles resonated with you, or if you just want to try out the latest Kubernetes has to offer, please give the feature a try and open issues with any problem you encountered and ways you think the feature could be improved.
|
||||
|
||||
This is just the very beginning of what we can do with distributed tracing in Kubernetes. If there are other components you think would benefit from distributed tracing, or want to help bring API Server Tracing to GA, join sig-instrumentation at our [regular meetings](https://github.com/kubernetes/community/tree/master/sig-instrumentation#instrumentation-special-interest-group) and get involved!
|
||||
Loading…
Reference in New Issue