mirror of https://github.com/MycroftAI/mimic2.git
Merge pull request #45 from thorstenMueller/master
Added script createljspeech.py for easy dataset creationpull/50/head
commit
04562d4f4d
13
README.md
13
README.md
|
|
@ -97,6 +97,11 @@ Contributions are accepted! We'd love the communities help in building a better
|
|||
```
|
||||
python3 preprocess.py --dataset ljspeech
|
||||
```
|
||||
If recorded with mimic-recording-studio
|
||||
````
|
||||
python3 preprocess.py --dataset mrs --mrs_dir=<path_to>/mimic-recording-studio/
|
||||
````
|
||||
|
||||
* other datasets can be used, i.e. `--dataset blizzard` for Blizzard data
|
||||
* for the mailabs dataset, do `preprocess.py --help` for options. Also, note that mailabs uses sample_size of 16000
|
||||
* you may want to create your own preprocessing script that works for your dataset. You can follow examples from preprocess.py and ./datasets
|
||||
|
|
@ -186,6 +191,14 @@ Contributions are accepted! We'd love the communities help in building a better
|
|||
* Here is the expected loss curve when training on LJ Speech with the default hyperparameters:
|
||||
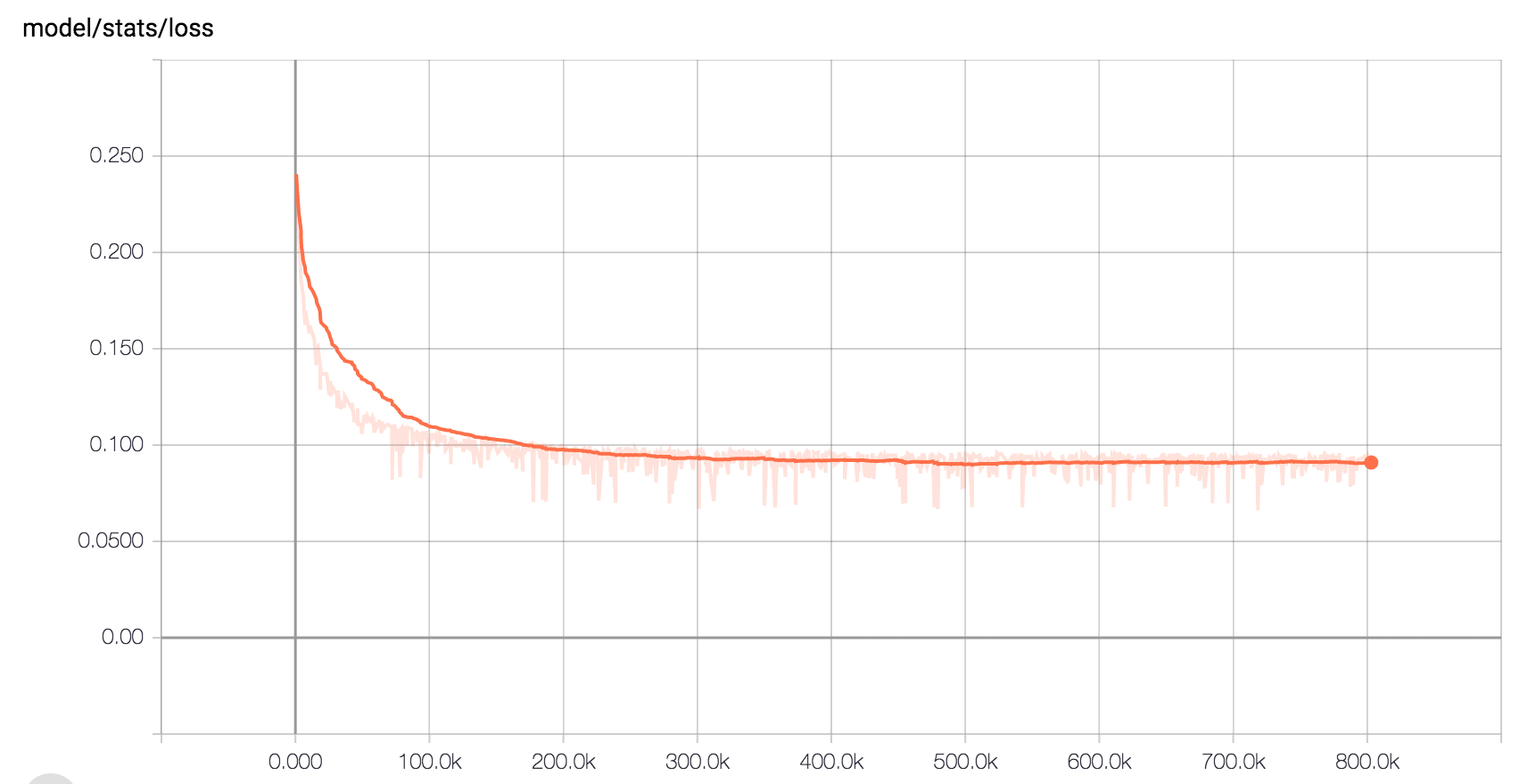
|
||||
|
||||
* If you used mimic-recording-studio and want to create an ljspeech dataset syntax out of it you can use the following command
|
||||
````
|
||||
python3 ./datasets/createljspeech.py --mrs_dir=<path_to>/mimic-recording-studio/
|
||||
````
|
||||
This generates an tacotron/LJSpeech-1.1 folder under your user home.
|
||||
|
||||
|
||||
|
||||
## Other Implementations
|
||||
* By Alex Barron: https://github.com/barronalex/Tacotron
|
||||
* By Kyubyong Park: https://github.com/Kyubyong/tacotron
|
||||
|
|
|
|||
|
|
@ -0,0 +1,47 @@
|
|||
# This script generates a folder structure for ljspeech-1.1 processing from mimic-recording-studio database
|
||||
# Written by Thorsten Mueller (MrThorstenM@gmx.net) on november 2019 without any warranty
|
||||
|
||||
import argparse
|
||||
import sqlite3
|
||||
import os
|
||||
from shutil import copyfile
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--out_dir', default=os.path.expanduser('~/tacotron'))
|
||||
parser.add_argument('--mrs_dir', required=True)
|
||||
args = parser.parse_args()
|
||||
|
||||
dir_base_ljspeech = os.path.join(args.out_dir,"LJSpeech-1.1")
|
||||
dir_base_ljspeech_wav = os.path.join(dir_base_ljspeech,"wavs")
|
||||
dir_base_mrs = args.mrs_dir
|
||||
os.makedirs(dir_base_ljspeech_wav, exist_ok=True)
|
||||
|
||||
conn = sqlite3.connect(os.path.join(dir_base_mrs,"backend","db","mimicstudio.db"))
|
||||
c = conn.cursor()
|
||||
|
||||
# Get user id from sqlite to find recordings in directory structure
|
||||
# TODO: Currently just works with one user
|
||||
for row in c.execute('SELECT uuid FROM usermodel LIMIT 1;'):
|
||||
uid = row[0]
|
||||
|
||||
print("Found speaker user guid in sqlite: " + uid)
|
||||
|
||||
# Create new metadata.csv for ljspeech
|
||||
metadata = open(os.path.join(dir_base_ljspeech,"metadata.csv"),mode="w", encoding="utf8")
|
||||
|
||||
for row in c.execute('SELECT DISTINCT audio_id, prompt, lower(prompt) FROM audiomodel ORDER BY length(prompt)'):
|
||||
audio_file_source = os.path.join(dir_base_mrs,"backend","audio_files", uid, row[0] + ".wav")
|
||||
if os.path.isfile(audio_file_source):
|
||||
metadata.write(row[0] + "|" + row[1] + "|" + row[2] + "\n")
|
||||
audio_file_dest = os.path.join(dir_base_ljspeech_wav,row[0] + ".wav")
|
||||
copyfile(audio_file_source,audio_file_dest)
|
||||
else:
|
||||
print("File " + audio_file_source + " no found. Skipping.")
|
||||
|
||||
|
||||
metadata.close()
|
||||
conn.close()
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
from concurrent.futures import ProcessPoolExecutor
|
||||
from functools import partial
|
||||
import numpy as np
|
||||
import os
|
||||
from util import audio
|
||||
import sqlite3
|
||||
import sys
|
||||
|
||||
|
||||
def build_from_path(in_dir, out_dir, username, num_workers=1, tqdm=lambda x: x):
|
||||
'''Preprocesses the recordings from mimic-recording-studio (based on sqlite db) into a given output directory.
|
||||
|
||||
Args:
|
||||
in_dir: The root directory of mimic-recording-studio
|
||||
out_dir: The directory to write the output into
|
||||
num_workers: Optional number of worker processes to parallelize across
|
||||
tqdm: You can optionally pass tqdm to get a nice progress bar
|
||||
|
||||
Returns:
|
||||
A list of tuples describing the training examples. This should be written to train.txt
|
||||
'''
|
||||
|
||||
# We use ProcessPoolExecutor to parallize across processes. This is just an optimization and you
|
||||
# can omit it and just call _process_utterance on each input if you want.
|
||||
executor = ProcessPoolExecutor(max_workers=num_workers)
|
||||
futures = []
|
||||
index = 1
|
||||
|
||||
# Query sqlite db of mimic-recording-studio
|
||||
dbfile = os.path.join(in_dir,"backend","db","mimicstudio.db")
|
||||
print("Reading data from mimic-recording-studio sqlite db file: " + dbfile)
|
||||
conn = sqlite3.connect(dbfile)
|
||||
c = conn.cursor()
|
||||
|
||||
uid = ''
|
||||
sql_get_guid = "SELECT uuid FROM usermodel LIMIT 1;"
|
||||
if username:
|
||||
print("Query user guid for " + username + " in sqlite db")
|
||||
sql_get_guid = "SELECT uuid FROM usermodel WHERE UPPER(user_name) = '" + username.upper() + "' LIMIT 1;"
|
||||
|
||||
for row in c.execute(sql_get_guid):
|
||||
uid = row[0]
|
||||
|
||||
if uid == '':
|
||||
print("No userid could be found in sqlite db.")
|
||||
sys.exit()
|
||||
|
||||
print("Found speaker user guid in sqlite: " + uid)
|
||||
|
||||
wav_dir = os.path.join(in_dir,"backend","audio_files",uid)
|
||||
print("Search for wav files in " + wav_dir)
|
||||
|
||||
for row in c.execute('SELECT DISTINCT audio_id, lower(prompt) FROM audiomodel ORDER BY length(prompt)'):
|
||||
wav_path = os.path.join(wav_dir, '%s.wav' % row[0])
|
||||
if os.path.isfile(wav_path):
|
||||
text = row[1]
|
||||
futures.append(executor.submit(partial(_process_utterance, out_dir, index, wav_path, text)))
|
||||
index += 1
|
||||
else:
|
||||
print("File " + wav_path + " no found. Skipping.")
|
||||
return [future.result() for future in tqdm(futures)]
|
||||
|
||||
|
||||
def _process_utterance(out_dir, index, wav_path, text):
|
||||
'''Preprocesses a single utterance audio/text pair.
|
||||
|
||||
This writes the mel and linear scale spectrograms to disk and returns a tuple to write
|
||||
to the train.txt file.
|
||||
|
||||
Args:
|
||||
out_dir: The directory to write the spectrograms into
|
||||
index: The numeric index to use in the spectrogram filenames.
|
||||
wav_path: Path to the audio file containing the speech input
|
||||
text: The text spoken in the input audio file
|
||||
|
||||
Returns:
|
||||
A (spectrogram_filename, mel_filename, n_frames, text) tuple to write to train.txt
|
||||
'''
|
||||
|
||||
# Load the audio to a numpy array:
|
||||
wav = audio.load_wav(wav_path)
|
||||
|
||||
# Compute the linear-scale spectrogram from the wav:
|
||||
spectrogram = audio.spectrogram(wav).astype(np.float32)
|
||||
n_frames = spectrogram.shape[1]
|
||||
|
||||
# Compute a mel-scale spectrogram from the wav:
|
||||
mel_spectrogram = audio.melspectrogram(wav).astype(np.float32)
|
||||
|
||||
# Write the spectrograms to disk:
|
||||
spectrogram_filename = 'mrs-spec-%05d.npy' % index
|
||||
mel_filename = 'mrs-mel-%05d.npy' % index
|
||||
np.save(os.path.join(out_dir, spectrogram_filename), spectrogram.T, allow_pickle=False)
|
||||
np.save(os.path.join(out_dir, mel_filename), mel_spectrogram.T, allow_pickle=False)
|
||||
|
||||
# Return a tuple describing this training example:
|
||||
return (spectrogram_filename, mel_filename, n_frames, text)
|
||||
|
|
@ -3,7 +3,9 @@ import os
|
|||
from multiprocessing import cpu_count
|
||||
from tqdm import tqdm
|
||||
from datasets import amy, blizzard, ljspeech, kusal, mailabs
|
||||
from datasets import mrs
|
||||
from hparams import hparams, hparams_debug_string
|
||||
import sys
|
||||
|
||||
|
||||
def preprocess_blizzard(args):
|
||||
|
|
@ -23,6 +25,14 @@ def preprocess_ljspeech(args):
|
|||
in_dir, out_dir, args.num_workers, tqdm=tqdm)
|
||||
write_metadata(metadata, out_dir)
|
||||
|
||||
def preprocess_mrs(args):
|
||||
in_dir = args.mrs_dir
|
||||
out_dir = os.path.join(args.base_dir, args.output)
|
||||
username = args.mrs_username
|
||||
os.makedirs(out_dir, exist_ok=True)
|
||||
metadata = mrs.build_from_path(
|
||||
in_dir, out_dir, username, args.num_workers, tqdm=tqdm)
|
||||
write_metadata(metadata, out_dir)
|
||||
|
||||
def preprocess_amy(args):
|
||||
in_dir = os.path.join(args.base_dir, 'amy')
|
||||
|
|
@ -77,9 +87,11 @@ def write_metadata(metadata, out_dir):
|
|||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--base_dir', default=os.path.expanduser('~/tacotron'))
|
||||
parser.add_argument('--mrs_dir', required=False)
|
||||
parser.add_argument('--mrs_username', required=False)
|
||||
parser.add_argument('--output', default='training')
|
||||
parser.add_argument(
|
||||
'--dataset', required=True, choices=['amy', 'blizzard', 'ljspeech', 'kusal', 'mailabs']
|
||||
'--dataset', required=True, choices=['amy', 'blizzard', 'ljspeech', 'kusal', 'mailabs','mrs']
|
||||
)
|
||||
parser.add_argument('--mailabs_books_dir',
|
||||
help='absolute directory to the books for the mlailabs')
|
||||
|
|
@ -109,6 +121,8 @@ def main():
|
|||
preprocess_kusal(args)
|
||||
elif args.dataset == 'mailabs':
|
||||
preprocess_mailabs(args)
|
||||
elif args.dataset == 'mrs':
|
||||
preprocess_mrs(args)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
|
|
|||
Loading…
Reference in New Issue