Merge branch 'master' of github.com:influxdata/docs-v2 into clustered/pull-secrets
commit
9e70ff5757
|
|
@ -0,0 +1,25 @@
|
|||
FROM registry.gitlab.com/pipeline-components/remark-lint:latest
|
||||
|
||||
|
||||
WORKDIR /app/
|
||||
|
||||
# Generic
|
||||
#RUN apk add --no-cache
|
||||
COPY /.ci/remark-lint /app/
|
||||
|
||||
# Node
|
||||
ENV PATH "$PATH:/app/node_modules/.bin/"
|
||||
RUN yarn install && yarn cache clean
|
||||
ENV NODE_PATH=/app/node_modules/
|
||||
RUN ln -nfs /app/node_modules /node_modules
|
||||
|
||||
# Build arguments
|
||||
ARG BUILD_DATE
|
||||
ARG BUILD_REF
|
||||
|
||||
# Labels
|
||||
LABEL \
|
||||
org.label-schema.build-date=${BUILD_DATE} \
|
||||
org.label-schema.name="Remark-lint" \
|
||||
org.label-schema.schema-version="1.0" \
|
||||
org.label-schema.url="https://pipeline-components.gitlab.io/"
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
{
|
||||
"name": "remark-lint",
|
||||
"license": "MIT",
|
||||
"devDependencies": {
|
||||
"remark-cli": "12.0.1",
|
||||
"remark-preset-lint-consistent": "6.0.0",
|
||||
"remark-preset-lint-markdown-style-guide": "6.0.0",
|
||||
"remark-preset-lint-recommended": "7.0.0",
|
||||
"remark-frontmatter": "5.0.0",
|
||||
"remark-lint-frontmatter-schema": "3.15.4",
|
||||
"remark-lint-no-shell-dollars": "4.0.0"
|
||||
}
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,11 @@
|
|||
extends: substitution
|
||||
message: Did you mean '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
'cloud-serverless|clustered': cloud-dedicated
|
||||
'Cloud Serverless|Clustered': Cloud Dedicated
|
||||
'API token': database token
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
extends: substitution
|
||||
message: Did you mean '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
'(?i)bucket': database
|
||||
'(?i)measurement': table
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
extends: substitution
|
||||
message: Did you mean '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
'cloud-dedicated|clustered': cloud-serverless
|
||||
'Cloud Dedicated|Clustered': Cloud Serverless
|
||||
'(?i)database token': API token
|
||||
'(?i)management token': API token
|
||||
'(?i)database': bucket
|
||||
'(?i)table': measurement
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
extends: substitution
|
||||
message: Did you mean '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
'cloud-serverless|cloud-dedicated': clustered
|
||||
'Cloud Serverless|Cloud Dedicated': Clustered
|
||||
'API token': database token
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
extends: substitution
|
||||
message: Did you mean '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
'(?i)bucket': database
|
||||
'(?i)measurement': table
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
extends: spelling
|
||||
message: "Did you really mean '%s'?"
|
||||
level: warning
|
||||
ignore:
|
||||
# Ignore the following words. All words are case-insensitive.
|
||||
# To use case-sensitive matching, use the filters section or vocabulary Terms.
|
||||
- InfluxDBv2/Terms/query-functions.txt
|
||||
- InfluxDBv2/Terms/server-config-options.txt
|
||||
filters:
|
||||
- '(\[|`)ui-disabled(`|\])'
|
||||
|
|
@ -0,0 +1,76 @@
|
|||
|
||||
|
||||
# InfluxQL
|
||||
# is_scalar_math_function
|
||||
# Source: https://github.com/influxdata/influxdb_iox/blob/4f9c901dcfece5fcc4d17cfecb6ec45a0dccda5a/influxdb_influxql_parser/src/functions.rs
|
||||
abs
|
||||
sin
|
||||
cos
|
||||
tan
|
||||
asin
|
||||
acos
|
||||
acosh
|
||||
asinh
|
||||
atan
|
||||
atanh
|
||||
atan2
|
||||
cbrt
|
||||
exp
|
||||
gcd
|
||||
isnan
|
||||
iszero
|
||||
lcm
|
||||
log
|
||||
ln
|
||||
log2
|
||||
log10
|
||||
nanvl
|
||||
sqrt
|
||||
pow
|
||||
floor
|
||||
ceil
|
||||
round
|
||||
|
||||
# InfluxQL operators
|
||||
bitfield
|
||||
|
||||
# is_aggregate_function
|
||||
# Source: https://github.com/influxdata/influxdb_iox/blob/4f9c901dcfece5fcc4d17cfecb6ec45a0dccda5a/influxdb_influxql_parser/src/functions.rs
|
||||
approx_distinct
|
||||
approx_median
|
||||
approx_percentile_cont
|
||||
approx_percentile_cont_with_weight
|
||||
covar
|
||||
cumulative_sum
|
||||
derivative
|
||||
difference
|
||||
elapsed
|
||||
moving_average
|
||||
non_negative_derivative
|
||||
non_negative_difference
|
||||
bottom
|
||||
first
|
||||
last
|
||||
max
|
||||
min
|
||||
percentile
|
||||
sample
|
||||
top
|
||||
count
|
||||
integral
|
||||
mean
|
||||
median
|
||||
mode
|
||||
spread
|
||||
stddev
|
||||
sum
|
||||
holt_winters
|
||||
holt_winters_with_fit
|
||||
chande_momentum_oscillator
|
||||
exponential_moving_average
|
||||
double_exponential_moving_average
|
||||
kaufmans_efficiency_ratio
|
||||
kaufmans_adaptive_moving_average
|
||||
triple_exponential_moving_average
|
||||
triple_exponential_derivative
|
||||
relative_strength_index
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
assets-path
|
||||
bolt-path
|
||||
e2e-testing
|
||||
engine-path
|
||||
feature-flags
|
||||
flux-log-enabled
|
||||
hardening-enabled
|
||||
http-bind-address
|
||||
http-idle-timeout
|
||||
http-read-header-timeout
|
||||
http-read-timeout
|
||||
http-write-timeout
|
||||
influxql-max-select-buckets
|
||||
influxql-max-select-point
|
||||
influxql-max-select-series
|
||||
instance-id
|
||||
log-level
|
||||
metrics-disabled
|
||||
nats-max-payload-bytes
|
||||
nats-port
|
||||
no-tasks
|
||||
pprof-disabled
|
||||
query-concurrency
|
||||
query-initial-memory-bytes
|
||||
query-max-memory-bytes
|
||||
query-memory-bytes
|
||||
query-queue-size
|
||||
reporting-disabled
|
||||
secret-store
|
||||
session-length
|
||||
session-renew-disabled
|
||||
sqlite-path
|
||||
storage-cache-max-memory-size
|
||||
storage-cache-snapshot-memory-size
|
||||
storage-cache-snapshot-write-cold-duration
|
||||
storage-compact-full-write-cold-duration
|
||||
storage-compact-throughput-burst
|
||||
storage-max-concurrent-compactions
|
||||
storage-max-index-log-file-size
|
||||
storage-no-validate-field-size
|
||||
storage-retention-check-interval
|
||||
storage-series-file-max-concurrent-snapshot-compactions
|
||||
storage-series-id-set-cache-size
|
||||
storage-shard-precreator-advance-period
|
||||
storage-shard-precreator-check-interval
|
||||
storage-tsm-use-madv-willneed
|
||||
storage-validate-keys
|
||||
storage-wal-fsync-delay
|
||||
storage-wal-max-concurrent-writes
|
||||
storage-wal-max-write-delay
|
||||
storage-write-timeout
|
||||
store
|
||||
strong-passwords
|
||||
testing-always-allow-setup
|
||||
tls-cert
|
||||
tls-key
|
||||
tls-min-version
|
||||
tls-strict-ciphers
|
||||
tracing-type
|
||||
ui-disabled
|
||||
vault-addr
|
||||
vault-cacert
|
||||
vault-capath
|
||||
vault-client-cert
|
||||
vault-client-key
|
||||
vault-client-timeout
|
||||
vault-max-retries
|
||||
vault-skip-verify
|
||||
vault-tls-server-name
|
||||
vault-token
|
||||
|
|
@ -0,0 +1,65 @@
|
|||
extends: conditional
|
||||
message: "Spell out '%s', if it's unfamiliar to the audience."
|
||||
link: 'https://developers.google.com/style/abbreviations'
|
||||
level: suggestion
|
||||
ignorecase: false
|
||||
# Ensures that the existence of 'first' implies the existence of 'second'.
|
||||
first: '\b([A-Z]{3,5})\b'
|
||||
second: '(?:\b[A-Z][a-z]+ )+\(([A-Z]{3,5})\)'
|
||||
# ... with the exception of these:
|
||||
exceptions:
|
||||
- \b(\[[A-Z]{3,5})\]\(.*\)\b
|
||||
- API
|
||||
- ASP
|
||||
- CLI
|
||||
- CPU
|
||||
- CSS
|
||||
- CSV
|
||||
- DEBUG
|
||||
- DOM
|
||||
- DPI
|
||||
- FAQ
|
||||
- GCC
|
||||
- GDB
|
||||
- GET
|
||||
- GPU
|
||||
- GTK
|
||||
- GUI
|
||||
- HTML
|
||||
- HTTP
|
||||
- HTTPS
|
||||
- IDE
|
||||
- JAR
|
||||
- JSON
|
||||
- JSX
|
||||
- LESS
|
||||
- LLDB
|
||||
- NET
|
||||
- NOTE
|
||||
- NVDA
|
||||
- OSS
|
||||
- PATH
|
||||
- PDF
|
||||
- PHP
|
||||
- POST
|
||||
- RAM
|
||||
- REPL
|
||||
- RSA
|
||||
- SCM
|
||||
- SCSS
|
||||
- SDK
|
||||
- SQL
|
||||
- SSH
|
||||
- SSL
|
||||
- SVG
|
||||
- TBD
|
||||
- TCP
|
||||
- TODO
|
||||
- URI
|
||||
- URL
|
||||
- USB
|
||||
- UTF
|
||||
- XML
|
||||
- XSS
|
||||
- YAML
|
||||
- ZIP
|
||||
|
|
@ -1,45 +1,20 @@
|
|||
extends: substitution
|
||||
message: Use '%s' instead of '%s'
|
||||
level: warning
|
||||
ignorecase: true
|
||||
ignorecase: false
|
||||
# swap maps tokens in form of bad: good
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side;
|
||||
# Vale ignores alerts that match the intended form.
|
||||
swap:
|
||||
# NOTE: The left-hand (bad) side can match the right-hand (good) side; Vale
|
||||
# will ignore any alerts that match the intended form.
|
||||
"anaconda": Anaconda
|
||||
"(?i)api": API
|
||||
"arrow": Arrow
|
||||
"authtoken": authToken
|
||||
"Authtoken": AuthToken
|
||||
"chronograf": Chronograf
|
||||
"cli": CLI
|
||||
"(?i)clockface": Clockface
|
||||
"the compactor": the Compactor
|
||||
"data explorer": Data Explorer
|
||||
"datetime": dateTime
|
||||
"dedupe": deduplicate
|
||||
"(?i)executionplan": ExecutionPlan
|
||||
"fieldkey": fieldKey
|
||||
"fieldtype": fieldType
|
||||
"flight": Flight
|
||||
"(?i)flightquery": FlightQuery
|
||||
"(?i)FlightSQL": Flight SQL
|
||||
"/b(?i)influxdata/b": InfluxData
|
||||
"/w*/b(?i)influxdb": InfluxDB
|
||||
"(?i)influxql": InfluxQL
|
||||
"influxer": Influxer
|
||||
"the ingester": the Ingester
|
||||
"(?i)iox": v3
|
||||
"java[ -]?scripts?": JavaScript
|
||||
"kapa": Kapacitor
|
||||
"logicalplan": LogicalPlan
|
||||
"the object store": the Object store
|
||||
"a {{% product-name %}}": an {{% product-name %}}
|
||||
"Pandas": pandas
|
||||
" parquet": Parquet
|
||||
"the querier": the Querier
|
||||
"SQL Alchemy": SQLAlchemy
|
||||
"superset": Superset
|
||||
"tagkey": tagKey
|
||||
"telegraf": Telegraf
|
||||
"telegraph": Telegraf
|
||||
'the compactor': the Compactor
|
||||
'dedupe': deduplicate
|
||||
'/b(?i)influxdata/b': InfluxData
|
||||
'/w*/b(?i)influxdb': InfluxDB
|
||||
'the ingester': the Ingester
|
||||
'(?i)iox': v3
|
||||
'the object store': the Object store
|
||||
'a {{% product-name %}}': an {{% product-name %}}
|
||||
'the querier': the Querier
|
||||
'SQL Alchemy': SQLAlchemy
|
||||
'telegraph': Telegraf
|
||||
'(?i)vscode': VSCode
|
||||
|
|
|
|||
|
|
@ -376,4 +376,8 @@ exceptions:
|
|||
- kaufmans_adaptive_moving_average
|
||||
- triple_exponential_moving_average
|
||||
- triple_exponential_derivative
|
||||
- relative_strength_index
|
||||
- relative_strength_index
|
||||
# Telegraf config
|
||||
- agent
|
||||
- token
|
||||
- urls
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
extends: existence
|
||||
message: "Use 'July 31, 2016' format, not '%s'."
|
||||
link: 'https://developers.google.com/style/dates-times'
|
||||
ignorecase: true
|
||||
level: error
|
||||
nonword: true
|
||||
scope:
|
||||
- ~table.cell
|
||||
tokens:
|
||||
- '\d{1,2}(?:\.|/)\d{1,2}(?:\.|/)\d{4}'
|
||||
- '\d{1,2} (?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)|May|Jun(?:e)|Jul(?:y)|Aug(?:ust)|Sep(?:tember)?|Oct(?:ober)|Nov(?:ember)?|Dec(?:ember)?) \d{4}'
|
||||
|
|
@ -1,36 +1,15 @@
|
|||
extends: spelling
|
||||
message: "Did you really mean '%s'?"
|
||||
level: error
|
||||
level: warning
|
||||
scope:
|
||||
- ~table.header
|
||||
- ~table.cell
|
||||
ignore:
|
||||
# Located at StylesPath/ignore1.txt
|
||||
- InfluxDataDocs/Terms/influxdb.txt
|
||||
- InfluxDataDocs/Terms/configuration-terms.txt
|
||||
# Ignore the following words. All words are case-insensitive.
|
||||
# To use case-sensitive matching, use the filters section or vocabulary Terms.
|
||||
- InfluxDataDocs/Terms/ignore.txt
|
||||
- InfluxDataDocs/Terms/query-functions.txt
|
||||
- InfluxDataDocs/Terms/telegraf.txt
|
||||
filters:
|
||||
# Ignore Hugo, layout, and design words.
|
||||
- 'Flexbox'
|
||||
- '(?i)frontmatter'
|
||||
- '(?i)shortcode(s?)'
|
||||
- '(?i)tooltip(s?)'
|
||||
# Ignore all words starting with 'py'.
|
||||
# e.g., 'PyYAML'.
|
||||
- '[pP]y.*\b'
|
||||
# Ignore underscore-delimited words.
|
||||
# e.g., avg_temp
|
||||
- '\b\w+_\w+\b'
|
||||
- '\b_\w+\b'
|
||||
# Ignore SQL variables.
|
||||
- '(?i)AS \w+'
|
||||
# Ignore custom words
|
||||
- '(?i)deduplicat(ion|e|ed|es|ing)'
|
||||
- '(?i)downsampl(e|ing|ed|es)'
|
||||
- 'InfluxDB-specific'
|
||||
- '(?i)repartition(ed|s|ing)'
|
||||
- '(?i)subcommand(s?)'
|
||||
- '(?i)union(ing|ed|s)?'
|
||||
- 'unsignedLong'
|
||||
- 'US (East|West|Central|North|South|Northeast|Northwest|Southeast|Southwest)'
|
||||
# Allow product-specific Branding.yml configurations to handle [Ss]erverless while also allowing serverless as a valid dictionary word.
|
||||
- '[Ss]erverless'
|
||||
|
||||
|
|
|
|||
|
|
@ -1,12 +0,0 @@
|
|||
autogen
|
||||
batchBucket
|
||||
batchInterval
|
||||
commentPrefix
|
||||
destinationBucket
|
||||
destinationHost
|
||||
destinationOrg
|
||||
destinationToken
|
||||
quoteChar
|
||||
retentionRules
|
||||
sourceBucket
|
||||
src
|
||||
|
|
@ -1,126 +1,96 @@
|
|||
api
|
||||
apis
|
||||
autogen
|
||||
boolean
|
||||
bundler
|
||||
chronograf
|
||||
clockface
|
||||
flexbox
|
||||
flight
|
||||
frontmatter
|
||||
kapacitor
|
||||
telegraf
|
||||
unix
|
||||
args
|
||||
authtoken
|
||||
authz
|
||||
boolean
|
||||
booleans
|
||||
bundler
|
||||
bundlers
|
||||
chronograf
|
||||
cli
|
||||
clockface
|
||||
cloud
|
||||
callout
|
||||
codeblock
|
||||
compactor
|
||||
conda
|
||||
csv
|
||||
config
|
||||
crypto
|
||||
dashboarding
|
||||
datagram
|
||||
datasource
|
||||
datetime
|
||||
deduplicate
|
||||
deserialize
|
||||
downsample
|
||||
dotenv
|
||||
enum
|
||||
executionplan
|
||||
fieldkey
|
||||
fieldtype
|
||||
file_groups
|
||||
flighquery
|
||||
Grafana
|
||||
groupId
|
||||
fullscreen
|
||||
gzip
|
||||
gzipped
|
||||
homogenous
|
||||
hostname
|
||||
hostUrl
|
||||
hostURL
|
||||
HostURL
|
||||
implementor
|
||||
implementors
|
||||
influxctl
|
||||
influxd
|
||||
influxdata.com
|
||||
influx3
|
||||
ingester
|
||||
ingesters
|
||||
iox
|
||||
kapacitor
|
||||
lat
|
||||
locf
|
||||
logicalplan
|
||||
logstash
|
||||
lon
|
||||
lookahead
|
||||
lookbehind
|
||||
metaquery
|
||||
metaqueries
|
||||
metaquery
|
||||
middleware
|
||||
namespace
|
||||
noaa
|
||||
npm
|
||||
oauth
|
||||
output_ordering
|
||||
pandas
|
||||
param
|
||||
performant
|
||||
projection
|
||||
protofiles
|
||||
pushdown
|
||||
querier
|
||||
queryable
|
||||
quoteChar
|
||||
rearchitect
|
||||
rearchitected
|
||||
redoc
|
||||
remediations
|
||||
repartition
|
||||
retentionRules
|
||||
retention_policy
|
||||
retryable
|
||||
rp
|
||||
serializable
|
||||
serializer
|
||||
serverless
|
||||
shortcode
|
||||
signout
|
||||
Splunk
|
||||
SQLAlchemy
|
||||
src
|
||||
stderr
|
||||
stdin
|
||||
stdout
|
||||
subcommand
|
||||
subcommands
|
||||
subnet
|
||||
subnets
|
||||
subprocessor
|
||||
subprocessors
|
||||
subquery
|
||||
subqueries
|
||||
subquery
|
||||
substring
|
||||
substrings
|
||||
superset
|
||||
svg
|
||||
syntaxes
|
||||
tagkey
|
||||
tagKey
|
||||
tagset
|
||||
telegraf
|
||||
telegraf's
|
||||
tombstoned
|
||||
tsm
|
||||
tooltip
|
||||
uint
|
||||
uinteger
|
||||
unescaped
|
||||
ungroup
|
||||
ungrouped
|
||||
unprocessable
|
||||
unix
|
||||
unioned
|
||||
unioning
|
||||
unions
|
||||
unmarshal
|
||||
unmarshalled
|
||||
unpackage
|
||||
unprocessable
|
||||
unsignedLong
|
||||
upsample
|
||||
upsert
|
||||
urls
|
||||
venv
|
||||
VSCode
|
||||
WALs
|
||||
Webpack
|
||||
xpath
|
||||
XPath
|
||||
|
|
@ -1 +0,0 @@
|
|||
[Tt]elegraf
|
||||
|
|
@ -55,6 +55,7 @@ swap:
|
|||
fewer data: less data
|
||||
file name: filename
|
||||
firewalls: firewall rules
|
||||
fully qualified: fully-qualified
|
||||
functionality: capability|feature
|
||||
Google account: Google Account
|
||||
Google accounts: Google Accounts
|
||||
|
|
@ -81,6 +82,5 @@ swap:
|
|||
tablename: table name
|
||||
tablet: device
|
||||
touch: tap
|
||||
url: URL
|
||||
vs\.: versus
|
||||
World Wide Web: web
|
||||
|
|
|
|||
|
|
@ -1,2 +0,0 @@
|
|||
cloud-dedicated
|
||||
Cloud Dedicated
|
||||
|
|
@ -1,6 +0,0 @@
|
|||
API token
|
||||
bucket name
|
||||
Cloud Serverless
|
||||
cloud-serverless
|
||||
Clustered
|
||||
clustered
|
||||
|
|
@ -1,2 +0,0 @@
|
|||
cloud-serverless
|
||||
Cloud Serverless
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
Cloud Dedicated
|
||||
cloud-dedicated
|
||||
Clustered
|
||||
clustered
|
||||
database name
|
||||
database token
|
||||
management token
|
||||
|
|
@ -1 +0,0 @@
|
|||
clustered
|
||||
|
|
@ -1,6 +0,0 @@
|
|||
API token
|
||||
bucket name
|
||||
Cloud Dedicated
|
||||
cloud-dedicated
|
||||
Cloud Serverless
|
||||
cloud-serverless
|
||||
|
|
@ -0,0 +1,88 @@
|
|||
(?i)AS \w+
|
||||
(InfluxQL|influxql)
|
||||
(tsm|TSM)
|
||||
(xpath|XPath)
|
||||
APIs?
|
||||
Anaconda
|
||||
Apache Superset
|
||||
Arrow
|
||||
AuthToken
|
||||
CLI|\/cli\/
|
||||
CSV
|
||||
Data Explorer
|
||||
Dedup
|
||||
[Dd]ownsampl(e|ed|es|ing)
|
||||
Execd
|
||||
ExecutionPlan
|
||||
Flight SQL
|
||||
FlightQuery
|
||||
GBs?
|
||||
Grafana|\{\{.*grafana.*\}\}
|
||||
HostURL
|
||||
InfluxDB Cloud
|
||||
InfluxDB OSS
|
||||
InfluxDB-specific
|
||||
Influxer
|
||||
JavaScript
|
||||
KBs?
|
||||
LogicalPlan
|
||||
[Mm]axim(ize|um)
|
||||
[Mm]inim(ize|um)
|
||||
[Mm]onitor
|
||||
MBs?
|
||||
PBs?
|
||||
Parquet
|
||||
Redoc
|
||||
SQLAlchemy
|
||||
SQLAlchemy
|
||||
Splunk
|
||||
[Ss]uperset
|
||||
TBs?
|
||||
\bUI\b
|
||||
URL
|
||||
US (East|West|Central|North|South|Northeast|Northwest|Southeast|Southwest)
|
||||
Unix
|
||||
WALs?
|
||||
Webpack
|
||||
[pP]y.*\b
|
||||
\b\w+_\w+\b
|
||||
\b_\w+\b
|
||||
airSensors
|
||||
api-endpoint
|
||||
batchBucket
|
||||
batchInterval
|
||||
commentPrefix
|
||||
destinationBucket
|
||||
destinationHost
|
||||
destinationOrg
|
||||
destinationToken
|
||||
docs-v2
|
||||
exampleTag
|
||||
fieldKey
|
||||
fieldType
|
||||
gotType
|
||||
groupId
|
||||
hostURL
|
||||
hostUrl
|
||||
influx3
|
||||
influxctl
|
||||
influxd
|
||||
influxdata.com
|
||||
iox
|
||||
keep-url
|
||||
lat
|
||||
locf
|
||||
logicalplan
|
||||
noaa|NOAA
|
||||
npm|NPM
|
||||
oauth|OAuth
|
||||
pandas
|
||||
quoteChar
|
||||
retentionRules
|
||||
sourceBucket
|
||||
tagKey
|
||||
url[s]?
|
||||
v2
|
||||
v3
|
||||
venv
|
||||
wantType
|
||||
|
|
@ -3,205 +3,27 @@ message: "'%s' is a weasel word!"
|
|||
ignorecase: true
|
||||
level: warning
|
||||
tokens:
|
||||
- absolutely
|
||||
- accidentally
|
||||
- additionally
|
||||
- allegedly
|
||||
- alternatively
|
||||
- angrily
|
||||
- anxiously
|
||||
- approximately
|
||||
- awkwardly
|
||||
- badly
|
||||
- barely
|
||||
- beautifully
|
||||
- blindly
|
||||
- boldly
|
||||
- bravely
|
||||
- brightly
|
||||
- briskly
|
||||
- bristly
|
||||
- bubbly
|
||||
- busily
|
||||
- calmly
|
||||
- carefully
|
||||
- carelessly
|
||||
- cautiously
|
||||
- cheerfully
|
||||
- clearly
|
||||
- closely
|
||||
- coldly
|
||||
- completely
|
||||
- consequently
|
||||
- correctly
|
||||
- courageously
|
||||
- crinkly
|
||||
- cruelly
|
||||
- crumbly
|
||||
- cuddly
|
||||
- currently
|
||||
- daily
|
||||
- daringly
|
||||
- deadly
|
||||
- definitely
|
||||
- deliberately
|
||||
- doubtfully
|
||||
- dumbly
|
||||
- eagerly
|
||||
- early
|
||||
- easily
|
||||
- elegantly
|
||||
- enormously
|
||||
- enthusiastically
|
||||
- equally
|
||||
- especially
|
||||
- eventually
|
||||
- exactly
|
||||
- exceedingly
|
||||
- exclusively
|
||||
- excellent
|
||||
- extremely
|
||||
- fairly
|
||||
- faithfully
|
||||
- fatally
|
||||
- fiercely
|
||||
- finally
|
||||
- fondly
|
||||
- few
|
||||
- foolishly
|
||||
- fortunately
|
||||
- frankly
|
||||
- frantically
|
||||
- generously
|
||||
- gently
|
||||
- giggly
|
||||
- gladly
|
||||
- gracefully
|
||||
- greedily
|
||||
- happily
|
||||
- hardly
|
||||
- hastily
|
||||
- healthily
|
||||
- heartily
|
||||
- helpfully
|
||||
- honestly
|
||||
- hourly
|
||||
- hungrily
|
||||
- hurriedly
|
||||
- immediately
|
||||
- impatiently
|
||||
- inadequately
|
||||
- ingeniously
|
||||
- innocently
|
||||
- inquisitively
|
||||
- huge
|
||||
- interestingly
|
||||
- irritably
|
||||
- jiggly
|
||||
- joyously
|
||||
- justly
|
||||
- kindly
|
||||
- is a number
|
||||
- largely
|
||||
- lately
|
||||
- lazily
|
||||
- likely
|
||||
- literally
|
||||
- lonely
|
||||
- loosely
|
||||
- loudly
|
||||
- loudly
|
||||
- luckily
|
||||
- madly
|
||||
- many
|
||||
- mentally
|
||||
- mildly
|
||||
- monthly
|
||||
- mortally
|
||||
- mostly
|
||||
- mysteriously
|
||||
- neatly
|
||||
- nervously
|
||||
- nightly
|
||||
- noisily
|
||||
- normally
|
||||
- obediently
|
||||
- occasionally
|
||||
- only
|
||||
- openly
|
||||
- painfully
|
||||
- particularly
|
||||
- patiently
|
||||
- perfectly
|
||||
- politely
|
||||
- poorly
|
||||
- powerfully
|
||||
- presumably
|
||||
- previously
|
||||
- promptly
|
||||
- punctually
|
||||
- quarterly
|
||||
- quickly
|
||||
- quietly
|
||||
- rapidly
|
||||
- rarely
|
||||
- really
|
||||
- recently
|
||||
- recklessly
|
||||
- regularly
|
||||
- remarkably
|
||||
- obviously
|
||||
- quite
|
||||
- relatively
|
||||
- reluctantly
|
||||
- repeatedly
|
||||
- rightfully
|
||||
- roughly
|
||||
- rudely
|
||||
- sadly
|
||||
- safely
|
||||
- selfishly
|
||||
- sensibly
|
||||
- seriously
|
||||
- sharply
|
||||
- shortly
|
||||
- shyly
|
||||
- remarkably
|
||||
- several
|
||||
- significantly
|
||||
- silently
|
||||
- simply
|
||||
- sleepily
|
||||
- slowly
|
||||
- smartly
|
||||
- smelly
|
||||
- smoothly
|
||||
- softly
|
||||
- solemnly
|
||||
- sparkly
|
||||
- speedily
|
||||
- stealthily
|
||||
- sternly
|
||||
- stupidly
|
||||
- substantially
|
||||
- successfully
|
||||
- suddenly
|
||||
- surprisingly
|
||||
- suspiciously
|
||||
- swiftly
|
||||
- tenderly
|
||||
- tensely
|
||||
- thoughtfully
|
||||
- tightly
|
||||
- timely
|
||||
- truthfully
|
||||
- unexpectedly
|
||||
- unfortunately
|
||||
- tiny
|
||||
- usually
|
||||
- various
|
||||
- vast
|
||||
- very
|
||||
- victoriously
|
||||
- violently
|
||||
- vivaciously
|
||||
- warmly
|
||||
- waverly
|
||||
- weakly
|
||||
- wearily
|
||||
- weekly
|
||||
- wildly
|
||||
- wisely
|
||||
- worldly
|
||||
- wrinkly
|
||||
- yearly
|
||||
|
|
|
|||
|
|
@ -1,16 +1,20 @@
|
|||
# Lint cloud-dedicated
|
||||
docspath=.
|
||||
contentpath=$docspath/content
|
||||
#!/bin/bash
|
||||
|
||||
# Vale searches for a configuration file (.vale.ini) in the directory of the file being linted, and then in each of its parent directories.
|
||||
# Lint cloud-dedicated
|
||||
npx vale --output=line --relative --minAlertLevel=error $contentpath/influxdb/cloud-dedicated
|
||||
# Run Vale to lint files for writing style and consistency
|
||||
|
||||
# Lint cloud-serverless
|
||||
npx vale --config=$contentpath/influxdb/cloud-serverless/.vale.ini --output=line --relative --minAlertLevel=error $contentpath/influxdb/cloud-serverless
|
||||
# Example usage:
|
||||
|
||||
# Lint clustered
|
||||
npx vale --config=$contentpath/influxdb/clustered/.vale.ini --output=line --relative --minAlertLevel=error $contentpath/influxdb/clustered
|
||||
# Lint all added and modified files in the cloud-dedicated directory and report suggestions, warnings, and errors.
|
||||
|
||||
# Lint telegraf
|
||||
# npx vale --config=$docspath/.vale.ini --output=line --relative --minAlertLevel=error $contentpath/telegraf
|
||||
# git diff --name-only --diff-filter=d HEAD | grep "content/influxdb/cloud-dedicated" | xargs .ci/vale/vale.sh --minAlertLevel=suggestion --config=content/influxdb/cloud-dedicated/.vale.ini
|
||||
|
||||
# Lint files provided as arguments
|
||||
docker run \
|
||||
--rm \
|
||||
--label tag=influxdata-docs \
|
||||
--label stage=lint \
|
||||
--mount type=bind,src=$(pwd),dst=/workdir \
|
||||
-w /workdir \
|
||||
--entrypoint /bin/vale \
|
||||
jdkato/vale:latest \
|
||||
"$@"
|
||||
|
|
@ -12,6 +12,6 @@ node_modules
|
|||
/api-docs/redoc-static.html*
|
||||
.vscode/*
|
||||
.idea
|
||||
config.toml
|
||||
**/config.toml
|
||||
package-lock.json
|
||||
tmp
|
||||
|
|
@ -1 +0,0 @@
|
|||
_
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "$LEFTHOOK_VERBOSE" = "1" -o "$LEFTHOOK_VERBOSE" = "true" ]; then
|
||||
set -x
|
||||
fi
|
||||
|
||||
if [ "$LEFTHOOK" = "0" ]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
call_lefthook()
|
||||
{
|
||||
if test -n "$LEFTHOOK_BIN"
|
||||
then
|
||||
"$LEFTHOOK_BIN" "$@"
|
||||
elif lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
lefthook "$@"
|
||||
else
|
||||
dir="$(git rev-parse --show-toplevel)"
|
||||
osArch=$(uname | tr '[:upper:]' '[:lower:]')
|
||||
cpuArch=$(uname -m | sed 's/aarch64/arm64/;s/x86_64/x64/')
|
||||
if test -f "$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/lefthook/bin/index.js"
|
||||
then
|
||||
"$dir/node_modules/lefthook/bin/index.js" "$@"
|
||||
|
||||
elif bundle exec lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
bundle exec lefthook "$@"
|
||||
elif yarn lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
yarn lefthook "$@"
|
||||
elif pnpm lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
pnpm lefthook "$@"
|
||||
elif swift package plugin lefthook >/dev/null 2>&1
|
||||
then
|
||||
swift package --disable-sandbox plugin lefthook "$@"
|
||||
elif command -v mint >/dev/null 2>&1
|
||||
then
|
||||
mint run csjones/lefthook-plugin "$@"
|
||||
elif command -v npx >/dev/null 2>&1
|
||||
then
|
||||
npx lefthook "$@"
|
||||
else
|
||||
echo "Can't find lefthook in PATH"
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
call_lefthook run "build" "$@"
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "$LEFTHOOK_VERBOSE" = "1" -o "$LEFTHOOK_VERBOSE" = "true" ]; then
|
||||
set -x
|
||||
fi
|
||||
|
||||
if [ "$LEFTHOOK" = "0" ]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
call_lefthook()
|
||||
{
|
||||
if test -n "$LEFTHOOK_BIN"
|
||||
then
|
||||
"$LEFTHOOK_BIN" "$@"
|
||||
elif lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
lefthook "$@"
|
||||
else
|
||||
dir="$(git rev-parse --show-toplevel)"
|
||||
osArch=$(uname | tr '[:upper:]' '[:lower:]')
|
||||
cpuArch=$(uname -m | sed 's/aarch64/arm64/;s/x86_64/x64/')
|
||||
if test -f "$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/lefthook/bin/index.js"
|
||||
then
|
||||
"$dir/node_modules/lefthook/bin/index.js" "$@"
|
||||
|
||||
elif bundle exec lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
bundle exec lefthook "$@"
|
||||
elif yarn lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
yarn lefthook "$@"
|
||||
elif pnpm lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
pnpm lefthook "$@"
|
||||
elif swift package plugin lefthook >/dev/null 2>&1
|
||||
then
|
||||
swift package --disable-sandbox plugin lefthook "$@"
|
||||
elif command -v mint >/dev/null 2>&1
|
||||
then
|
||||
mint run csjones/lefthook-plugin "$@"
|
||||
elif command -v npx >/dev/null 2>&1
|
||||
then
|
||||
npx lefthook "$@"
|
||||
else
|
||||
echo "Can't find lefthook in PATH"
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
call_lefthook run "pre-commit" "$@"
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "$LEFTHOOK_VERBOSE" = "1" -o "$LEFTHOOK_VERBOSE" = "true" ]; then
|
||||
set -x
|
||||
fi
|
||||
|
||||
if [ "$LEFTHOOK" = "0" ]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
call_lefthook()
|
||||
{
|
||||
if test -n "$LEFTHOOK_BIN"
|
||||
then
|
||||
"$LEFTHOOK_BIN" "$@"
|
||||
elif lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
lefthook "$@"
|
||||
else
|
||||
dir="$(git rev-parse --show-toplevel)"
|
||||
osArch=$(uname | tr '[:upper:]' '[:lower:]')
|
||||
cpuArch=$(uname -m | sed 's/aarch64/arm64/;s/x86_64/x64/')
|
||||
if test -f "$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/lefthook/bin/index.js"
|
||||
then
|
||||
"$dir/node_modules/lefthook/bin/index.js" "$@"
|
||||
|
||||
elif bundle exec lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
bundle exec lefthook "$@"
|
||||
elif yarn lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
yarn lefthook "$@"
|
||||
elif pnpm lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
pnpm lefthook "$@"
|
||||
elif swift package plugin lefthook >/dev/null 2>&1
|
||||
then
|
||||
swift package --disable-sandbox plugin lefthook "$@"
|
||||
elif command -v mint >/dev/null 2>&1
|
||||
then
|
||||
mint run csjones/lefthook-plugin "$@"
|
||||
elif command -v npx >/dev/null 2>&1
|
||||
then
|
||||
npx lefthook "$@"
|
||||
else
|
||||
echo "Can't find lefthook in PATH"
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
call_lefthook run "pre-push" "$@"
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "$LEFTHOOK_VERBOSE" = "1" -o "$LEFTHOOK_VERBOSE" = "true" ]; then
|
||||
set -x
|
||||
fi
|
||||
|
||||
if [ "$LEFTHOOK" = "0" ]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
call_lefthook()
|
||||
{
|
||||
if test -n "$LEFTHOOK_BIN"
|
||||
then
|
||||
"$LEFTHOOK_BIN" "$@"
|
||||
elif lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
lefthook "$@"
|
||||
else
|
||||
dir="$(git rev-parse --show-toplevel)"
|
||||
osArch=$(uname | tr '[:upper:]' '[:lower:]')
|
||||
cpuArch=$(uname -m | sed 's/aarch64/arm64/;s/x86_64/x64/')
|
||||
if test -f "$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/lefthook/bin/index.js"
|
||||
then
|
||||
"$dir/node_modules/lefthook/bin/index.js" "$@"
|
||||
|
||||
elif bundle exec lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
bundle exec lefthook "$@"
|
||||
elif yarn lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
yarn lefthook "$@"
|
||||
elif pnpm lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
pnpm lefthook "$@"
|
||||
elif swift package plugin lefthook >/dev/null 2>&1
|
||||
then
|
||||
swift package --disable-sandbox plugin lefthook "$@"
|
||||
elif command -v mint >/dev/null 2>&1
|
||||
then
|
||||
mint run csjones/lefthook-plugin "$@"
|
||||
elif command -v npx >/dev/null 2>&1
|
||||
then
|
||||
npx lefthook "$@"
|
||||
else
|
||||
echo "Can't find lefthook in PATH"
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
call_lefthook run "prepare-commit-msg" "$@"
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "$LEFTHOOK_VERBOSE" = "1" -o "$LEFTHOOK_VERBOSE" = "true" ]; then
|
||||
set -x
|
||||
fi
|
||||
|
||||
if [ "$LEFTHOOK" = "0" ]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
call_lefthook()
|
||||
{
|
||||
if test -n "$LEFTHOOK_BIN"
|
||||
then
|
||||
"$LEFTHOOK_BIN" "$@"
|
||||
elif lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
lefthook "$@"
|
||||
else
|
||||
dir="$(git rev-parse --show-toplevel)"
|
||||
osArch=$(uname | tr '[:upper:]' '[:lower:]')
|
||||
cpuArch=$(uname -m | sed 's/aarch64/arm64/;s/x86_64/x64/')
|
||||
if test -f "$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/lefthook-${osArch}-${cpuArch}/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook/bin/lefthook-${osArch}-${cpuArch}/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook"
|
||||
then
|
||||
"$dir/node_modules/@evilmartians/lefthook-installer/bin/lefthook" "$@"
|
||||
elif test -f "$dir/node_modules/lefthook/bin/index.js"
|
||||
then
|
||||
"$dir/node_modules/lefthook/bin/index.js" "$@"
|
||||
|
||||
elif bundle exec lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
bundle exec lefthook "$@"
|
||||
elif yarn lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
yarn lefthook "$@"
|
||||
elif pnpm lefthook -h >/dev/null 2>&1
|
||||
then
|
||||
pnpm lefthook "$@"
|
||||
elif swift package plugin lefthook >/dev/null 2>&1
|
||||
then
|
||||
swift package --disable-sandbox plugin lefthook "$@"
|
||||
elif command -v mint >/dev/null 2>&1
|
||||
then
|
||||
mint run csjones/lefthook-plugin "$@"
|
||||
elif command -v npx >/dev/null 2>&1
|
||||
then
|
||||
npx lefthook "$@"
|
||||
else
|
||||
echo "Can't find lefthook in PATH"
|
||||
fi
|
||||
fi
|
||||
}
|
||||
|
||||
call_lefthook run "scripts" "$@"
|
||||
|
|
@ -1 +0,0 @@
|
|||
npx lint-staged --relative
|
||||
|
|
@ -1,68 +0,0 @@
|
|||
// Lint-staged configuration. This file must export a lint-staged configuration object.
|
||||
|
||||
function testStagedContent(paths, productPath) {
|
||||
const productName = productPath.replace(/\//g, '-');
|
||||
const CONTENT = `staged-${productName}`;
|
||||
const TEST = `pytest-${productName}`;
|
||||
|
||||
return [
|
||||
// Remove any existing test container and volume
|
||||
`sh -c "docker rm -f ${CONTENT} || true"`,
|
||||
`sh -c "docker rm -f ${TEST} || true"`,
|
||||
|
||||
`docker build . -f Dockerfile.tests -t influxdata-docs/tests:latest`,
|
||||
|
||||
// Copy staged content to a volume and run the prepare script
|
||||
`docker run --name ${CONTENT}
|
||||
--mount type=volume,source=staged-content,target=/app/content
|
||||
--mount type=bind,src=./content,dst=/src/content
|
||||
--mount type=bind,src=./static/downloads,dst=/app/data
|
||||
influxdata-docs/tests --files "${paths.join(' ')}"`,
|
||||
|
||||
`docker build .
|
||||
-f Dockerfile.pytest
|
||||
-t influxdata-docs/pytest:latest`,
|
||||
|
||||
// Run test runners.
|
||||
// This script first checks if there are any tests to run using `pytest --collect-only`.
|
||||
// If there are tests, it runs them; otherwise, it exits with a success code.
|
||||
// Whether tests pass or fail, the container is removed,
|
||||
// but the CONTENT container will remain until the next run.
|
||||
`sh -c "docker run --rm --name ${TEST}-collector \
|
||||
--env-file ${productPath}/.env.test \
|
||||
--volumes-from ${CONTENT} \
|
||||
influxdata-docs/pytest --codeblocks --collect-only \
|
||||
${productPath}/ > /dev/null 2>&1; \
|
||||
TEST_COLLECT_EXIT_CODE=$?; \
|
||||
if [ $TEST_COLLECT_EXIT_CODE -eq 5 ]; then \
|
||||
echo 'No tests to run.'; \
|
||||
exit 0; \
|
||||
else \
|
||||
docker run --rm --name ${TEST} \
|
||||
--env-file ${productPath}/.env.test \
|
||||
--volumes-from ${CONTENT} \
|
||||
influxdata-docs/pytest --codeblocks --exitfirst ${productPath}/;
|
||||
fi"`
|
||||
];
|
||||
}
|
||||
|
||||
export default {
|
||||
"*.{js,css}": paths => `prettier --write ${paths.join(' ')}`,
|
||||
|
||||
// Don't let prettier check or write Markdown files for now;
|
||||
// it indents code blocks within list items, which breaks Hugo's rendering.
|
||||
// "*.md": paths => `prettier --check ${paths.join(' ')}`,
|
||||
|
||||
"content/influxdb/cloud-dedicated/**/*.md":
|
||||
paths => [...testStagedContent(paths, 'content/influxdb/cloud-dedicated')],
|
||||
"content/influxdb/cloud-serverless/**/*.md":
|
||||
paths => [...testStagedContent(paths, 'content/influxdb/cloud-serverless')],
|
||||
"content/influxdb/clustered/**/*.md":
|
||||
paths => [...testStagedContent(paths, 'content/influxdb/clustered')],
|
||||
|
||||
// "content/influxdb/cloud-serverless/**/*.md": "docker compose run -T lint --config=content/influxdb/cloud-serverless/.vale.ini --minAlertLevel=error",
|
||||
|
||||
// "content/influxdb/clustered/**/*.md": "docker compose run -T lint --config=content/influxdb/clustered/.vale.ini --minAlertLevel=error",
|
||||
|
||||
// "content/influxdb/{cloud,v2,telegraf}/**/*.md": "docker compose run -T lint --config=.vale.ini --minAlertLevel=error"
|
||||
}
|
||||
11
.vale.ini
11
.vale.ini
|
|
@ -1,12 +1,17 @@
|
|||
StylesPath = ".ci/vale/styles"
|
||||
StylesPath = .ci/vale/styles
|
||||
|
||||
MinAlertLevel = warning
|
||||
|
||||
Packages = Google, Hugo, write-good
|
||||
Vocab = InfluxDataDocs
|
||||
|
||||
Packages = Google, write-good, Hugo
|
||||
|
||||
[*.md]
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Google, write-good
|
||||
|
||||
Google.Acronyms = NO
|
||||
Google.DateFormat = NO
|
||||
Google.Ellipses = NO
|
||||
Google.Headings = NO
|
||||
Google.WordList = NO
|
||||
Google.WordList = NO
|
||||
Vale.Spelling = NO
|
||||
180
CONTRIBUTING.md
180
CONTRIBUTING.md
|
|
@ -77,48 +77,192 @@ scripts configured in `.husky/pre-commit`, including linting and tests for your
|
|||
|
||||
**We strongly recommend running linting and tests**, but you can skip them
|
||||
(and avoid installing dependencies)
|
||||
by including the `--no-verify` flag with your commit--for example, enter the following command in your terminal:
|
||||
by including the `HUSKY=0` environment variable or the `--no-verify` flag with
|
||||
your commit--for example:
|
||||
|
||||
```sh
|
||||
git commit -m "<COMMIT_MESSAGE>" --no-verify
|
||||
```
|
||||
|
||||
```sh
|
||||
HUSKY=0 git commit
|
||||
```
|
||||
|
||||
For more options, see the [Husky documentation](https://typicode.github.io/husky/how-to.html#skipping-git-hooks).
|
||||
|
||||
### Configure test credentials
|
||||
### Set up test scripts and credentials
|
||||
|
||||
To configure credentials for tests, set the usual InfluxDB environment variables
|
||||
for each product inside a `content/influxdb/<PRODUCT_DIRECTORY>/.env.test` file.
|
||||
To set up your docs-v2 instance to run tests locally, do the following:
|
||||
|
||||
The Docker commands in the `.lintstagedrc.mjs` lint-staged configuration load
|
||||
the `.env.test` as product-specific environment variables.
|
||||
1. **Set executable permissions on test scripts** in `./test/src`:
|
||||
|
||||
**Warning**: To prevent accidentally adding credentials to the docs-v2 repo,
|
||||
```sh
|
||||
chmod +x ./test/src/*.sh
|
||||
```
|
||||
|
||||
2. **Create credentials for tests**:
|
||||
|
||||
- Create databases, buckets, and tokens for the product(s) you're testing.
|
||||
- If you don't have access to a Clustered instance, you can use your
|
||||
Cloud Dedicated instance for testing in most cases. To avoid conflicts when
|
||||
running tests, create separate Cloud Dedicated and Clustered databases.
|
||||
|
||||
3. **Create .env.test**: Copy the `./test/env.test.example` file into each
|
||||
product directory to test and rename the file as `.env.test`--for example:
|
||||
|
||||
```sh
|
||||
./content/influxdb/cloud-dedicated/.env.test
|
||||
```
|
||||
|
||||
4. Inside each product's `.env.test` file, assign your InfluxDB credentials to
|
||||
environment variables.
|
||||
|
||||
In addition to the usual `INFLUX_` environment variables, in your
|
||||
`cloud-dedicated/.env.test` and `clustered/.env.test` files define the
|
||||
following variables:
|
||||
|
||||
- `ACCOUNT_ID`, `CLUSTER_ID`: You can find these values in your `influxctl`
|
||||
`config.toml` configuration file.
|
||||
- `MANAGEMENT_TOKEN`: Use the `influxctl management create` command to generate
|
||||
a long-lived management token to authenticate Management API requests
|
||||
|
||||
For the full list of variables you'll need to include, see the substitution
|
||||
patterns in `./test/src/prepare-content.sh`.
|
||||
|
||||
**Warning**: The database you configure in `.env.test` and any written data may
|
||||
be deleted during test runs.
|
||||
|
||||
**Warning**: To prevent accidentally adding credentials to the docs-v2 repo,
|
||||
Git is configured to ignore `.env*` files. Don't add your `.env.test` files to Git.
|
||||
Consider backing them up on your local machine in case of accidental deletion.
|
||||
|
||||
5. For influxctl commands to run in tests, move or copy your `config.toml` file
|
||||
to the `./test` directory.
|
||||
|
||||
### Pre-commit linting and testing
|
||||
|
||||
When you try to commit your changes using `git commit` or your editor,
|
||||
the project automatically runs pre-commit checks for spelling, punctuation,
|
||||
and style on your staged files.
|
||||
|
||||
The pre-commit hook calls [`lint-staged`](https://github.com/lint-staged/lint-staged) using the configuration in `.lintstagedrc.mjs`.
|
||||
`.husky/pre-commit` script runs Git pre-commit hook commands, including
|
||||
[`lint-staged`](https://github.com/lint-staged/lint-staged).
|
||||
|
||||
To run `lint-staged` scripts manually (without committing), enter the following
|
||||
command in your terminal:
|
||||
The `.lintstagedrc.mjs` lint-staged configuration maps product-specific glob
|
||||
patterns to lint and test commands and passes a product-specific
|
||||
`.env.test` file to a test runner Docker container.
|
||||
The container then loads the `.env` file into the container's environment variables.
|
||||
|
||||
```sh
|
||||
npx lint-staged --relative --verbose
|
||||
```
|
||||
To test or troubleshoot testing and linting scripts and configurations before
|
||||
committing, choose from the following:
|
||||
|
||||
- To run pre-commit scripts without actually committing, append `exit 1` to the
|
||||
`.husky/pre-commit` script--for example:
|
||||
|
||||
```sh
|
||||
./test/src/monitor-tests.sh start
|
||||
npx lint-staged --relative
|
||||
./test/src/monitor-tests.sh kill
|
||||
exit 1
|
||||
```
|
||||
|
||||
And then run `git commit`.
|
||||
|
||||
The `exit 1` status fails the commit, even if all the tasks succeed.
|
||||
|
||||
- Use `yarn` to run one of the lint or test scripts configured in
|
||||
`package.json`--for example:
|
||||
|
||||
```sh
|
||||
yarn run test
|
||||
```
|
||||
|
||||
- Run `lint-staged` directly and specify options:
|
||||
|
||||
```sh
|
||||
npx lint-staged --relative --verbose
|
||||
```
|
||||
|
||||
The pre-commit linting configuration checks for _error-level_ problems.
|
||||
An error-level rule violation fails the commit and you must
|
||||
fix the problems before you can commit your changes.
|
||||
An error-level rule violation fails the commit and you must do one of the following before you can commit your changes:
|
||||
|
||||
If an error doesn't warrant a fix (for example, a term that should be allowed),
|
||||
you can override the check and try the commit again or you can edit the linter
|
||||
style rules to permanently allow the content. See **Configure style rules**.
|
||||
- fix the reported problem in the content
|
||||
|
||||
- edit the linter rules to permanently allow the content.
|
||||
See **Configure style rules**.
|
||||
|
||||
- temporarily override the hook (using `git commit --no-verify`)
|
||||
|
||||
#### Test shell and python code blocks
|
||||
|
||||
[pytest-codeblocks](https://github.com/nschloe/pytest-codeblocks/tree/main) extracts code from python and shell Markdown code blocks and executes assertions for the code.
|
||||
If you don't assert a value (using a Python `assert` statement), `--codeblocks` considers a non-zero exit code to be a failure.
|
||||
|
||||
**Note**: `pytest --codeblocks` uses Python's `subprocess.run()` to execute shell code.
|
||||
|
||||
You can use this to test CLI and interpreter commands, regardless of programming
|
||||
language, as long as they return standard exit codes.
|
||||
|
||||
To make the documented output of a code block testable, precede it with the
|
||||
`<!--pytest-codeblocks:expected-output-->` tag and **omit the code block language
|
||||
descriptor**--for example, in your Markdown file:
|
||||
|
||||
##### Example markdown
|
||||
|
||||
```python
|
||||
print("Hello, world!")
|
||||
```
|
||||
|
||||
<!--pytest-codeblocks:expected-output-->
|
||||
|
||||
The next code block is treated as an assertion.
|
||||
If successful, the output is the following:
|
||||
|
||||
```
|
||||
Hello, world!
|
||||
```
|
||||
|
||||
For commands, such as `influxctl` CLI commands, that require launching an
|
||||
OAuth URL in a browser, wrap the command in a subshell and redirect the output
|
||||
to `/shared/urls.txt` in the container--for example:
|
||||
|
||||
```sh
|
||||
# Test the preceding command outside of the code block.
|
||||
# influxctl authentication requires TTY interaction--
|
||||
# output the auth URL to a file that the host can open.
|
||||
script -c "influxctl user list " \
|
||||
/dev/null > /shared/urls.txt
|
||||
```
|
||||
|
||||
You probably don't want to display this syntax in the docs, which unfortunately
|
||||
means you'd need to include the test block separately from the displayed code
|
||||
block.
|
||||
To hide it from users, wrap the code block inside an HTML comment.
|
||||
Pytest-codeblocks will still collect and run the code block.
|
||||
|
||||
##### Mark tests to skip
|
||||
|
||||
pytest-codeblocks has features for skipping tests and marking blocks as failed.
|
||||
To learn more, see the pytest-codeblocks README and tests.
|
||||
|
||||
#### Troubleshoot tests
|
||||
|
||||
### Pytest collected 0 items
|
||||
|
||||
Potential reasons:
|
||||
|
||||
- See the test discovery options in `pytest.ini`.
|
||||
- For Python code blocks, use the following delimiter:
|
||||
|
||||
```python
|
||||
# Codeblocks runs this block.
|
||||
```
|
||||
|
||||
`pytest --codeblocks` ignores code blocks that use the following:
|
||||
|
||||
```py
|
||||
# Codeblocks ignores this block.
|
||||
```
|
||||
|
||||
### Vale style linting
|
||||
|
||||
|
|
|
|||
|
|
@ -1,9 +1,23 @@
|
|||
FROM golang:latest
|
||||
|
||||
### Install InfluxDB clients for testing
|
||||
# Install InfluxDB keys to verify client installs.
|
||||
# Follow the install instructions (https://docs.influxdata.com/telegraf/v1/install/?t=curl), except for sudo (which isn't available in Docker).
|
||||
# influxdata-archive_compat.key GPG fingerprint:
|
||||
# 9D53 9D90 D332 8DC7 D6C8 D3B9 D8FF 8E1F 7DF8 B07E
|
||||
ADD https://repos.influxdata.com/influxdata-archive_compat.key ./influxdata-archive_compat.key
|
||||
RUN echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null
|
||||
|
||||
RUN echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | tee /etc/apt/sources.list.d/influxdata.list
|
||||
|
||||
# Install InfluxDB clients to use in tests.
|
||||
RUN apt-get update && apt-get upgrade -y && apt-get install -y \
|
||||
curl \
|
||||
git \
|
||||
gpg \
|
||||
influxdb2 \
|
||||
influxdb2-cli \
|
||||
influxctl \
|
||||
jq \
|
||||
maven \
|
||||
nodejs \
|
||||
|
|
@ -11,6 +25,8 @@ RUN apt-get update && apt-get upgrade -y && apt-get install -y \
|
|||
python3 \
|
||||
python3-pip \
|
||||
python3-venv \
|
||||
rsync \
|
||||
telegraf \
|
||||
wget
|
||||
|
||||
RUN ln -s /usr/bin/python3 /usr/bin/python
|
||||
|
|
@ -26,29 +42,38 @@ ENV PYTHONUNBUFFERED=1
|
|||
|
||||
WORKDIR /app
|
||||
|
||||
RUN mkdir -p /app/log && chmod +w /app/log
|
||||
RUN mkdir -p /app/assets && chmod +w /app/assets
|
||||
|
||||
# Some Python test dependencies (pytest-dotenv and pytest-codeblocks) aren't
|
||||
# available as packages in apt-cache, so use pip to download dependencies in a # separate step and use Docker's caching.
|
||||
COPY ./test/src/pytest.ini pytest.ini
|
||||
COPY ./test/src/requirements.txt requirements.txt
|
||||
# Pytest configuration file.
|
||||
COPY ./test/pytest/pytest.ini pytest.ini
|
||||
# Python and Pytest dependencies.
|
||||
COPY ./test/pytest/requirements.txt requirements.txt
|
||||
# Pytest fixtures.
|
||||
COPY ./test/pytest/conftest.py conftest.py
|
||||
RUN pip install -Ur requirements.txt
|
||||
|
||||
# Activate the Python virtual environment configured in the Dockerfile.
|
||||
# Activate the Python virtual environment configured in the Dockerfile.
|
||||
RUN . /opt/venv/bin/activate
|
||||
|
||||
### Install InfluxDB clients for testing
|
||||
# Install InfluxDB keys to verify client installs.
|
||||
# Follow the install instructions (https://docs.influxdata.com/telegraf/v1/install/?t=curl), except for sudo (which isn't available in Docker).
|
||||
# influxdata-archive_compat.key GPG fingerprint:
|
||||
# 9D53 9D90 D332 8DC7 D6C8 D3B9 D8FF 8E1F 7DF8 B07E
|
||||
ADD https://repos.influxdata.com/influxdata-archive_compat.key ./influxdata-archive_compat.key
|
||||
RUN echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null
|
||||
ARG CONTENT_PATH
|
||||
ENV CONTENT_PATH="${CONTENT_PATH}"
|
||||
|
||||
RUN echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | tee /etc/apt/sources.list.d/influxdata.list
|
||||
# Create a mock xdg-open script` to prevent the test suite from attempting to open a browser (for example, during influxctl OAuth2 authentication).
|
||||
RUN echo '#!/bin/bash' > /usr/local/bin/xdg-open \
|
||||
&& echo 'echo "$1" > /shared/urls.txt' >> /usr/local/bin/xdg-open \
|
||||
&& chmod +x /usr/local/bin/xdg-open
|
||||
|
||||
# Install InfluxDB clients to use in tests.
|
||||
RUN apt-get update && apt-get -y install telegraf influxdb2-cli influxctl
|
||||
COPY --chmod=755 ./test/config.toml /root/.config/influxctl/config.toml
|
||||
### End InfluxDB client installs
|
||||
RUN service influxdb start
|
||||
|
||||
# Copy test scripts and make them executable.
|
||||
COPY --chmod=755 ./test/scripts/parse_yaml.sh /usr/local/bin/parse_yaml
|
||||
|
||||
ENTRYPOINT [ "pytest" ]
|
||||
CMD [ "" ]
|
||||
|
||||
# Specify command arguments:
|
||||
# --env-file to pass environment variables to the test suite.
|
||||
# the test directory to run the test suite.
|
||||
CMD [ "--codeblocks", "" ]
|
||||
|
|
@ -1,7 +1,6 @@
|
|||
# Use the Dockerfile 1.2 syntax to leverage BuildKit features like cache mounts and inline mounts--temporary mounts that are only available during the build step, not at runtime.
|
||||
# syntax=docker/dockerfile:1.2
|
||||
|
||||
# Starting from a Go base image is easier than setting up the Go environment later.
|
||||
FROM python:3.9-slim
|
||||
|
||||
# Install the necessary packages for the test environment.
|
||||
|
|
@ -13,6 +12,7 @@ COPY --chmod=755 ./test/src/prepare-content.sh /usr/local/bin/prepare-content
|
|||
COPY ./data/products.yml /app/appdata/products.yml
|
||||
|
||||
WORKDIR /src
|
||||
# In your docker run or exec command, you can set the prepare-content script as your entrypoint or command.
|
||||
ENTRYPOINT [ "prepare-content" ]
|
||||
# The default command is an empty string to pass all command line arguments to the entrypoint and allow the entrypoint to run.
|
||||
CMD [ "" ]
|
||||
|
|
@ -3,6 +3,6 @@
|
|||
variables:
|
||||
baseurl:
|
||||
enum:
|
||||
- 'cluster-id.influxdb.io'
|
||||
default: 'cluster-id.influxdb.io'
|
||||
- 'cluster-id.a.influxdb.io'
|
||||
default: 'cluster-id.a.influxdb.io'
|
||||
description: InfluxDB Cloud Dedicated URL
|
||||
|
|
|
|||
|
|
@ -17,8 +17,8 @@ servers:
|
|||
variables:
|
||||
baseurl:
|
||||
enum:
|
||||
- cluster-id.influxdb.io
|
||||
default: cluster-id.influxdb.io
|
||||
- cluster-id.a.influxdb.io
|
||||
default: cluster-id.a.influxdb.io
|
||||
description: InfluxDB Cloud Dedicated URL
|
||||
security:
|
||||
- BearerAuthentication: []
|
||||
|
|
@ -703,6 +703,13 @@ paths:
|
|||
schema:
|
||||
$ref: '#/components/schemas/LineProtocolLengthError'
|
||||
description: Write has been rejected because the payload is too large. Error message returns max size supported. All data in body was rejected and not written.
|
||||
'422':
|
||||
description: |
|
||||
Unprocessable Entity.
|
||||
|
||||
The request contained data outside the database’s retention period. InfluxDB rejected the batch and wrote no data.
|
||||
|
||||
The response body contains details about the [rejected points](/influxdb/cloud-dedicated/write-data/troubleshoot/#troubleshoot-rejected-points).
|
||||
'429':
|
||||
description: Token is temporarily over quota. The Retry-After header describes when to try the write again.
|
||||
headers:
|
||||
|
|
@ -1996,7 +2003,7 @@ components:
|
|||
# Use the --user option with `--user username:DATABASE_TOKEN` syntax
|
||||
#######################################
|
||||
|
||||
curl --get "http://cluster-id.influxdb.io/query" \
|
||||
curl --get "http://cluster-id.a.influxdb.io/query" \
|
||||
--user "":"DATABASE_TOKEN" \
|
||||
--data-urlencode "db=DATABASE_NAME" \
|
||||
--data-urlencode "q=SELECT * FROM MEASUREMENT"
|
||||
|
|
@ -2024,8 +2031,8 @@ components:
|
|||
### Syntax
|
||||
|
||||
```http
|
||||
https://cluster-id.influxdb.io/query/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.influxdb.io/write/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.a.influxdb.io/query/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.a.influxdb.io/write/?[u=any]&p=DATABASE_TOKEN
|
||||
```
|
||||
|
||||
### Example
|
||||
|
|
@ -2041,7 +2048,7 @@ components:
|
|||
# ?p=DATABASE_TOKEN
|
||||
#######################################
|
||||
|
||||
curl --get "https://cluster-id.influxdb.io/query" \
|
||||
curl --get "https://cluster-id.a.influxdb.io/query" \
|
||||
--data-urlencode "p=DATABASE_TOKEN" \
|
||||
--data-urlencode "db=DATABASE_NAME" \
|
||||
--data-urlencode "q=SELECT * FROM MEASUREMENT"
|
||||
|
|
@ -2078,7 +2085,7 @@ components:
|
|||
# to write data.
|
||||
########################################################
|
||||
|
||||
curl --request post "https://cluster-id.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
curl --request post "https://cluster-id.a.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--data-binary 'home,room=kitchen temp=72 1463683075'
|
||||
```
|
||||
|
|
@ -2109,7 +2116,7 @@ components:
|
|||
# to write data.
|
||||
########################################################
|
||||
|
||||
curl --request post "https://cluster-id.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
curl --request post "https://cluster-id.a.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
--header "Authorization: Token DATABASE_TOKEN" \
|
||||
--data-binary 'home,room=kitchen temp=72 1463683075'
|
||||
```
|
||||
|
|
|
|||
|
|
@ -262,8 +262,8 @@ tags:
|
|||
| Code | Status | Description |
|
||||
|:-----------:|:------------------------ |:--------------------- |
|
||||
| `200` | Success | |
|
||||
| `201` | Created | Successfully created a resource. The response body may contain details. |
|
||||
| `204` | No content | The request succeeded. InfluxDB doesn't typically return a response body for the operation. The [`/write`](#operation/PostLegacyWrite) and [`/api/v2/write`](#operation/PostWrite) endpoints return a response body if some points are written and some are rejected. |
|
||||
| `201` | Created | Successfully created a resource. The response body may contain details, for example [`/write`](#operation/PostLegacyWrite) and [`/api/v2/write`](#operation/PostWrite) response bodies contain details of partial write failures. |
|
||||
| `204` | No content | The request succeeded. |
|
||||
| `400` | Bad request | InfluxDB can't parse the request due to an incorrect parameter or bad syntax. For _writes_, the error may indicate one of the following problems: <ul><li>Line protocol is malformed. The response body contains the first malformed line in the data and indicates what was expected.</li><li>The batch contains a point with the same series as other points, but one of the field values has a different data type.<li>`Authorization` header is missing or malformed or the API token doesn't have permission for the operation.</li></ul> |
|
||||
| `401` | Unauthorized | May indicate one of the following: <ul><li>`Authorization: Token` header is missing or malformed</li><li>API token value is missing from the header</li><li>API token doesn't have permission. For more information about token types and permissions, see [Manage API tokens](/influxdb/cloud-serverless/security/tokens/)</li></ul> |
|
||||
| `404` | Not found | Requested resource was not found. `message` in the response body provides details about the requested resource. |
|
||||
|
|
@ -7487,14 +7487,17 @@ paths:
|
|||
|
||||
InfluxDB Cloud Serverless does the following when you send a write request:
|
||||
|
||||
1. Validates the request.
|
||||
2. If successful, attempts to [ingest the data](/influxdb/cloud-serverless/reference/internals/durability/#data-ingest); [error](/influxdb/cloud-serverless/write-data/troubleshoot/#review-http-status-codes) otherwise.
|
||||
3. If some or all points in the batch are written, responds with an HTTP `204 "No Content"` status code, acknowledging that data is written and queryable; error otherwise.
|
||||
1. Validates the request.
|
||||
2. If successful, attempts to [ingest data](/influxdb/cloud-serverless/reference/internals/durability/#data-ingest) from the request body; otherwise, responds with an [error status](/influxdb/cloud-serverless/write-data/troubleshoot/#review-http-status-codes).
|
||||
3. Ingests or rejects data in the batch and returns one of the following HTTP status codes:
|
||||
|
||||
- `204 "No Content"`: Data in the batch is written and queryable.
|
||||
- `400 "Bad Request"`: The entire batch is rejected.
|
||||
- `204 No Content`: all data in the batch is ingested
|
||||
- `201 Created`: some points in the batch are ingested and queryable, and some points are rejected
|
||||
- `400 Bad Request`: all data is rejected
|
||||
|
||||
If some points in the batch are rejected, the response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points).
|
||||
The response body contains error details about [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
|
||||
Writes are synchronous--the response status indicates the final status of the write and all ingested data is queryable.
|
||||
|
||||
To ensure that InfluxDB handles writes in the order you request them,
|
||||
wait for the response before you send the next request.
|
||||
|
|
@ -7636,12 +7639,9 @@ paths:
|
|||
- [Best practices for optimizing writes](/influxdb/cloud-serverless/write-data/best-practices/optimize-writes/)
|
||||
required: true
|
||||
responses:
|
||||
'204':
|
||||
'201':
|
||||
description: |
|
||||
Success.
|
||||
Data in the batch is written and queryable.
|
||||
|
||||
If some points in the batch are rejected, the response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
Success ("Created"). Some points in the batch are written and queryable, and some points are rejected. The response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
content:
|
||||
application/json:
|
||||
examples:
|
||||
|
|
@ -7653,6 +7653,8 @@ paths:
|
|||
message: 'failed to parse line protocol: errors encountered on line(s): error message for first rejected point</n> error message for second rejected point</n> error message for Nth rejected point (up to 100 rejected points)'
|
||||
schema:
|
||||
$ref: '#/components/schemas/LineProtocolError'
|
||||
'204':
|
||||
description: Success ("No Content"). All data in the batch is written and queryable.
|
||||
'400':
|
||||
description: |
|
||||
All data in the batch was rejected and not written.
|
||||
|
|
@ -7703,6 +7705,13 @@ paths:
|
|||
InfluxDB rejected the batch and did not write any data.
|
||||
|
||||
InfluxDB returns this error if the payload exceeds the 50MB size limit.
|
||||
'422':
|
||||
description: |
|
||||
Unprocessable Entity.
|
||||
|
||||
The request contained data outside the bucket's retention period. InfluxDB rejected the batch and wrote no data.
|
||||
|
||||
The response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points).
|
||||
'429':
|
||||
description: |
|
||||
Too many requests.
|
||||
|
|
@ -7916,18 +7925,21 @@ paths:
|
|||
description: |
|
||||
Writes data to a bucket.
|
||||
|
||||
Use this endpoint to send data in [line protocol](/influxdb/cloud-serverless/reference/syntax/line-protocol/) format to InfluxDB.
|
||||
Use this endpoint for [InfluxDB v1 parameter compatibility](/influxdb/cloud-serverless/guides/api-compatibility/v1/) when sending data in [line protocol](/influxdb/cloud-serverless/reference/syntax/line-protocol/) format to InfluxDB.
|
||||
|
||||
InfluxDB Cloud Serverless does the following when you send a write request:
|
||||
|
||||
1. Validates the request.
|
||||
2. If successful, attempts to [ingest the data](/influxdb/cloud-serverless/reference/internals/durability/#data-ingest); [error](/influxdb/cloud-serverless/write-data/troubleshoot/#review-http-status-codes) otherwise.
|
||||
3. If some or all points in the batch are written, responds with an HTTP `204 "No Content"` status code, acknowledging that data is written and queryable; error otherwise.
|
||||
1. Validates the request.
|
||||
2. If successful, attempts to [ingest data](/influxdb/cloud-serverless/reference/internals/durability/#data-ingest) from the request body; otherwise, responds with an [error status](/influxdb/cloud-serverless/write-data/troubleshoot/#review-http-status-codes).
|
||||
3. Ingests or rejects data in the batch and returns one of the following HTTP status codes:
|
||||
|
||||
- `204 "No Content"`: Data in the batch is written and queryable.
|
||||
- `400 "Bad Request"`: The entire batch is rejected.
|
||||
- `204 No Content`: all data in the batch is ingested
|
||||
- `201 Created`: some points in the batch are ingested and queryable, and some points are rejected
|
||||
- `400 Bad Request`: all data is rejected
|
||||
|
||||
If some points in the batch are rejected, the response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points).
|
||||
The response body contains error details about [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
|
||||
Writes are synchronous--the response status indicates the final status of the write and all ingested data is queryable.
|
||||
|
||||
To ensure that InfluxDB handles writes in the order you request them,
|
||||
wait for the response before you send the next request.
|
||||
|
|
@ -7995,12 +8007,9 @@ paths:
|
|||
description: Line protocol body
|
||||
required: true
|
||||
responses:
|
||||
'204':
|
||||
'201':
|
||||
description: |
|
||||
Success.
|
||||
Data in the batch is written and queryable.
|
||||
|
||||
If some points in the batch are rejected, the response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
Success ("Created"). Some points in the batch are written and queryable, and some points are rejected. The response body contains details about the [rejected points](/influxdb/cloud-serverless/write-data/troubleshoot/#troubleshoot-rejected-points), up to 100 points.
|
||||
content:
|
||||
application/json:
|
||||
examples:
|
||||
|
|
@ -8012,6 +8021,8 @@ paths:
|
|||
message: 'failed to parse line protocol: errors encountered on line(s): error message for first rejected point</n> error message for second rejected point</n> error message for Nth rejected point (up to 100 rejected points)'
|
||||
schema:
|
||||
$ref: '#/components/schemas/LineProtocolError'
|
||||
'204':
|
||||
description: Success ("No Content"). All data in the batch is written and queryable.
|
||||
'400':
|
||||
description: |
|
||||
All data in the batch is rejected and not written.
|
||||
|
|
|
|||
|
|
@ -1980,7 +1980,7 @@ components:
|
|||
# Use the --user option with `--user username:DATABASE_TOKEN` syntax
|
||||
#######################################
|
||||
|
||||
curl --get "http://cluster-id.influxdb.io/query" \
|
||||
curl --get "http://cluster-id.a.influxdb.io/query" \
|
||||
--user "":"DATABASE_TOKEN" \
|
||||
--data-urlencode "db=DATABASE_NAME" \
|
||||
--data-urlencode "q=SELECT * FROM MEASUREMENT"
|
||||
|
|
@ -2008,8 +2008,8 @@ components:
|
|||
### Syntax
|
||||
|
||||
```http
|
||||
https://cluster-id.influxdb.io/query/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.influxdb.io/write/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.a.influxdb.io/query/?[u=any]&p=DATABASE_TOKEN
|
||||
https://cluster-id.a.influxdb.io/write/?[u=any]&p=DATABASE_TOKEN
|
||||
```
|
||||
|
||||
### Example
|
||||
|
|
@ -2025,7 +2025,7 @@ components:
|
|||
# ?p=DATABASE_TOKEN
|
||||
#######################################
|
||||
|
||||
curl --get "https://cluster-id.influxdb.io/query" \
|
||||
curl --get "https://cluster-id.a.influxdb.io/query" \
|
||||
--data-urlencode "p=DATABASE_TOKEN" \
|
||||
--data-urlencode "db=DATABASE_NAME" \
|
||||
--data-urlencode "q=SELECT * FROM MEASUREMENT"
|
||||
|
|
@ -2062,7 +2062,7 @@ components:
|
|||
# to write data.
|
||||
########################################################
|
||||
|
||||
curl --request post "https://cluster-id.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
curl --request post "https://cluster-id.a.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--data-binary 'home,room=kitchen temp=72 1463683075'
|
||||
```
|
||||
|
|
@ -2093,7 +2093,7 @@ components:
|
|||
# to write data.
|
||||
########################################################
|
||||
|
||||
curl --request post "https://cluster-id.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
curl --request post "https://cluster-id.a.influxdb.io/api/v2/write?bucket=DATABASE_NAME&precision=s" \
|
||||
--header "Authorization: Token DATABASE_TOKEN" \
|
||||
--data-binary 'home,room=kitchen temp=72 1463683075'
|
||||
```
|
||||
|
|
|
|||
|
|
@ -93,7 +93,7 @@ var defaultUrls = {
|
|||
oss: 'http://localhost:8086',
|
||||
cloud: 'https://us-west-2-1.aws.cloud2.influxdata.com',
|
||||
serverless: 'https://us-east-1-1.aws.cloud2.influxdata.com',
|
||||
dedicated: 'cluster-id.influxdb.io',
|
||||
dedicated: 'cluster-id.a.influxdb.io',
|
||||
clustered: 'cluster-host.com',
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ var placeholderUrls = {
|
|||
oss: 'http://localhost:8086',
|
||||
cloud: 'https://cloud2.influxdata.com',
|
||||
serverless: 'https://cloud2.influxdata.com',
|
||||
dedicated: 'cluster-id.influxdb.io',
|
||||
dedicated: 'cluster-id.a.influxdb.io',
|
||||
clustered: 'cluster-host.com',
|
||||
};
|
||||
|
||||
|
|
@ -13,7 +13,7 @@ var placeholderUrls = {
|
|||
var elementSelector = '.article--content pre:not(.preserve)';
|
||||
|
||||
// Return the page context (cloud, serverless, oss/enterprise, dedicated, clustered, other)
|
||||
function context () {
|
||||
function context() {
|
||||
if (/\/influxdb\/cloud\//.test(window.location.pathname)) {
|
||||
return 'cloud';
|
||||
} else if (/\/influxdb\/cloud-serverless/.test(window.location.pathname)) {
|
||||
|
|
@ -37,12 +37,12 @@ function context () {
|
|||
|
||||
// Retrieve the user's InfluxDB preference (cloud or oss) from the influxdb_pref session cookie
|
||||
// Default is cloud.
|
||||
function getURLPreference () {
|
||||
function getURLPreference() {
|
||||
return getPreference('influxdb_url');
|
||||
}
|
||||
|
||||
// Set the user's selected InfluxDB preference (cloud or oss)
|
||||
function setURLPreference (preference) {
|
||||
function setURLPreference(preference) {
|
||||
setPreference('influxdb_url', preference);
|
||||
}
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ function setURLPreference (preference) {
|
|||
*/
|
||||
|
||||
// Store URLs in the urls session cookies
|
||||
function storeUrl (context, newUrl, prevUrl) {
|
||||
function storeUrl(context, newUrl, prevUrl) {
|
||||
urlsObj = {};
|
||||
urlsObj['prev_' + context] = prevUrl;
|
||||
urlsObj[context] = newUrl;
|
||||
|
|
@ -71,20 +71,20 @@ function storeUrl (context, newUrl, prevUrl) {
|
|||
|
||||
// Store custom URL in the url session cookie.
|
||||
// Used to populate the custom URL field
|
||||
function storeCustomUrl (customUrl) {
|
||||
function storeCustomUrl(customUrl) {
|
||||
setInfluxDBUrls({ custom: customUrl });
|
||||
$('input#custom[type=radio]').val(customUrl);
|
||||
}
|
||||
|
||||
// Set a URL in the urls session cookie to an empty string
|
||||
// Used to clear the form when custom url input is left empty
|
||||
function removeCustomUrl () {
|
||||
function removeCustomUrl() {
|
||||
removeInfluxDBUrl('custom');
|
||||
}
|
||||
|
||||
// Store a product URL in the urls session cookie
|
||||
// Used to populate the custom URL field
|
||||
function storeProductUrl (product, productUrl) {
|
||||
function storeProductUrl(product, productUrl) {
|
||||
urlsObj = {};
|
||||
urlsObj[product] = productUrl;
|
||||
|
||||
|
|
@ -94,7 +94,7 @@ function storeProductUrl (product, productUrl) {
|
|||
|
||||
// Set a product URL in the urls session cookie to an empty string
|
||||
// Used to clear the form when dedicated url input is left empty
|
||||
function removeProductUrl (product) {
|
||||
function removeProductUrl(product) {
|
||||
removeInfluxDBUrl(product);
|
||||
}
|
||||
|
||||
|
|
@ -104,7 +104,7 @@ function removeProductUrl (product) {
|
|||
|
||||
// Preserve URLs in codeblocks that come just after or are inside a div
|
||||
// with the class, .keep-url
|
||||
function addPreserve () {
|
||||
function addPreserve() {
|
||||
$('.keep-url').each(function () {
|
||||
// For code blocks with no syntax highlighting
|
||||
$(this).next('pre').addClass('preserve');
|
||||
|
|
@ -119,7 +119,7 @@ function addPreserve () {
|
|||
}
|
||||
|
||||
// Retrieve the currently selected URLs from the urls session cookie.
|
||||
function getUrls () {
|
||||
function getUrls() {
|
||||
var storedUrls = getInfluxDBUrls();
|
||||
var currentCloudUrl = storedUrls.cloud;
|
||||
var currentOSSUrl = storedUrls.oss;
|
||||
|
|
@ -138,7 +138,7 @@ function getUrls () {
|
|||
|
||||
// Retrieve the previously selected URLs from the from the urls session cookie.
|
||||
// This is used to update URLs whenever you switch between browser tabs.
|
||||
function getPrevUrls () {
|
||||
function getPrevUrls() {
|
||||
var storedUrls = getInfluxDBUrls();
|
||||
var prevCloudUrl = storedUrls.prev_cloud;
|
||||
var prevOSSUrl = storedUrls.prev_oss;
|
||||
|
|
@ -156,7 +156,7 @@ function getPrevUrls () {
|
|||
}
|
||||
|
||||
// Iterate through code blocks and update InfluxDB urls
|
||||
function updateUrls (prevUrls, newUrls) {
|
||||
function updateUrls(prevUrls, newUrls) {
|
||||
var preference = getURLPreference();
|
||||
var prevUrlsParsed = {
|
||||
oss: {},
|
||||
|
|
@ -244,7 +244,7 @@ function updateUrls (prevUrls, newUrls) {
|
|||
}
|
||||
});
|
||||
|
||||
function replaceWholename (startStr, endStr, replacement) {
|
||||
function replaceWholename(startStr, endStr, replacement) {
|
||||
var startsWithSeparator = new RegExp('[/.]');
|
||||
var endsWithSeparator = new RegExp('[-.:]');
|
||||
if (
|
||||
|
|
@ -278,7 +278,7 @@ function updateUrls (prevUrls, newUrls) {
|
|||
}
|
||||
|
||||
// Append the URL selector button to each codeblock containing a placeholder URL
|
||||
function appendUrlSelector () {
|
||||
function appendUrlSelector() {
|
||||
var appendToUrls = [
|
||||
placeholderUrls.oss,
|
||||
placeholderUrls.cloud,
|
||||
|
|
@ -290,15 +290,15 @@ function appendUrlSelector () {
|
|||
getBtnText = (context) => {
|
||||
contextText = {
|
||||
'oss/enterprise': 'Change InfluxDB URL',
|
||||
'cloud': 'InfluxDB Cloud Region',
|
||||
'serverless': 'InfluxDB Cloud Region',
|
||||
'dedicated': 'Set Dedicated cluster URL',
|
||||
'clustered': 'Set InfluxDB cluster URL',
|
||||
'other': 'InfluxDB Cloud or OSS?'
|
||||
}
|
||||
|
||||
return contextText[context]
|
||||
}
|
||||
cloud: 'InfluxDB Cloud Region',
|
||||
serverless: 'InfluxDB Cloud Region',
|
||||
dedicated: 'Set Dedicated cluster URL',
|
||||
clustered: 'Set InfluxDB cluster URL',
|
||||
other: 'InfluxDB Cloud or OSS?',
|
||||
};
|
||||
|
||||
return contextText[context];
|
||||
};
|
||||
|
||||
appendToUrls.forEach(function (url) {
|
||||
$(elementSelector).each(function () {
|
||||
|
|
@ -344,7 +344,7 @@ $('.url-trigger').click(function (e) {
|
|||
});
|
||||
|
||||
// Set the selected URL radio buttons to :checked
|
||||
function setRadioButtons () {
|
||||
function setRadioButtons() {
|
||||
currentUrls = getUrls();
|
||||
$('input[name="influxdb-cloud-url"][value="' + currentUrls.cloud + '"]').prop(
|
||||
'checked',
|
||||
|
|
@ -426,7 +426,7 @@ $('input[name="influxdb-clustered-url"]').change(function () {
|
|||
});
|
||||
|
||||
// Toggle preference tabs
|
||||
function togglePrefBtns (el) {
|
||||
function togglePrefBtns(el) {
|
||||
preference = el.length ? el.attr('id').replace('pref-', '') : 'cloud';
|
||||
prefUrls = $('#' + preference + '-urls');
|
||||
|
||||
|
|
@ -443,7 +443,7 @@ $('#pref-tabs .pref-tab').click(function () {
|
|||
});
|
||||
|
||||
// Select preference tab from cookie
|
||||
function showPreference () {
|
||||
function showPreference() {
|
||||
var preference = getPreference('influxdb_url');
|
||||
prefTab = $('#pref-' + preference);
|
||||
togglePrefBtns(prefTab);
|
||||
|
|
@ -457,7 +457,7 @@ showPreference();
|
|||
////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
// Validate custom URLs
|
||||
function validateUrl (url) {
|
||||
function validateUrl(url) {
|
||||
/** validDomain = (Named host | IPv6 host | IPvFuture host)(:Port)? **/
|
||||
var validDomain = new RegExp(
|
||||
`([a-z0-9\-._~%]+` +
|
||||
|
|
@ -505,19 +505,19 @@ function validateUrl (url) {
|
|||
}
|
||||
|
||||
// Show validation errors
|
||||
function showValidationMessage (validation) {
|
||||
function showValidationMessage(validation) {
|
||||
$('#custom-url').addClass('error');
|
||||
$('#custom-url').attr('data-message', validation.error);
|
||||
}
|
||||
|
||||
// Hide validation messages and replace the message attr with empty string
|
||||
function hideValidationMessage () {
|
||||
function hideValidationMessage() {
|
||||
$('#custom-url').removeClass('error').attr('data-message', '');
|
||||
}
|
||||
|
||||
// Set the custom URL cookie and apply the change
|
||||
// If the custom URL field is empty, it defaults to the OSS default
|
||||
function applyCustomUrl () {
|
||||
function applyCustomUrl() {
|
||||
var custUrl = $('#custom-url-field').val();
|
||||
let urlValidation = validateUrl(custUrl);
|
||||
if (custUrl.length > 0) {
|
||||
|
|
@ -540,7 +540,7 @@ function applyCustomUrl () {
|
|||
|
||||
// Set the product URL cookie and apply the change
|
||||
// If the product URL field is empty, it defaults to the product default
|
||||
function applyProductUrl (product) {
|
||||
function applyProductUrl(product) {
|
||||
var productUrl = $(`#${product}-url-field`).val();
|
||||
let urlValidation = validateUrl(productUrl);
|
||||
if (productUrl.length > 0) {
|
||||
|
|
@ -605,7 +605,7 @@ $(urlValueElements).blur(function () {
|
|||
/** Delay execution of a function `fn` for a number of milliseconds `ms`
|
||||
* e.g., delay a validation handler to avoid annoying the user.
|
||||
*/
|
||||
function delay (fn, ms) {
|
||||
function delay(fn, ms) {
|
||||
let timer = 0;
|
||||
return function (...args) {
|
||||
clearTimeout(timer);
|
||||
|
|
@ -613,7 +613,7 @@ function delay (fn, ms) {
|
|||
};
|
||||
}
|
||||
|
||||
function handleUrlValidation () {
|
||||
function handleUrlValidation() {
|
||||
let url = $(urlValueElements).val();
|
||||
let urlValidation = validateUrl(url);
|
||||
if (urlValidation.valid) {
|
||||
|
|
@ -658,3 +658,13 @@ if (cloudUrls.includes(referrerHost)) {
|
|||
setURLPreference('cloud');
|
||||
showPreference();
|
||||
}
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////
|
||||
//////////////////////////// Dedicated URL Migration ///////////////////////////
|
||||
///////////////////////// REMOVE AFTER AUGUST 22, 2024 /////////////////////////
|
||||
////////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
if (getUrls().dedicated == 'cluster-id.influxdb.io') {
|
||||
storeUrl('dedicated', 'cluster-id.a.influxdb.io', getUrls().dedicated);
|
||||
updateUrls(getPrevUrls(), getUrls());
|
||||
}
|
||||
|
|
|
|||
|
|
@ -6,16 +6,16 @@
|
|||
*/
|
||||
|
||||
// Get notification ID
|
||||
function notificationID (el) {
|
||||
function notificationID(el) {
|
||||
return $(el).attr('id');
|
||||
}
|
||||
|
||||
// Show notifications that are within scope and haven't been read
|
||||
function showNotifications () {
|
||||
function showNotifications() {
|
||||
$('#docs-notifications > .notification').each(function () {
|
||||
// Check if the path includes paths defined in the data-scope attribute
|
||||
// of the notification html element
|
||||
function inScope (path, scope) {
|
||||
function inScope(path, scope) {
|
||||
for (let i = 0; i < scope.length; i++) {
|
||||
if (path.includes(scope[i])) {
|
||||
return true;
|
||||
|
|
@ -24,14 +24,14 @@ function showNotifications () {
|
|||
return false;
|
||||
}
|
||||
|
||||
function excludePage (path, exclude) {
|
||||
function excludePage(path, exclude) {
|
||||
if (exclude[0].length > 0) {
|
||||
for (let i = 0; i < exclude.length; i++) {
|
||||
if (path.includes(exclude[i])) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
|
|
@ -41,8 +41,6 @@ function showNotifications () {
|
|||
var pageExcluded = excludePage(window.location.pathname, exclude);
|
||||
var notificationRead = notificationIsRead(notificationID(this), 'message');
|
||||
|
||||
console.log(pageExcluded)
|
||||
|
||||
if (pageInScope && !pageExcluded && !notificationRead) {
|
||||
$(this).show().animate({ right: 0, opacity: 1 }, 200, 'swing');
|
||||
}
|
||||
|
|
@ -50,7 +48,7 @@ function showNotifications () {
|
|||
}
|
||||
|
||||
// Hide a notification and set the notification as read
|
||||
function hideNotification (el) {
|
||||
function hideNotification(el) {
|
||||
$(el)
|
||||
.closest('.notification')
|
||||
.animate({ height: 0, opacity: 0 }, 200, 'swing', function () {
|
||||
|
|
|
|||
|
|
@ -114,6 +114,9 @@ pre[class*="language-"] {
|
|||
.nl, /* Name.Label */
|
||||
.si /* Literal.String.Interpol */
|
||||
{ color: $article-code-accent4 }
|
||||
|
||||
.gd /* Generic.Deleted strike-through*/
|
||||
{ text-decoration: line-through; }
|
||||
|
||||
.m, /* Literal.Number */
|
||||
.ni, /* Name.Entity */
|
||||
|
|
|
|||
407
compose.yaml
407
compose.yaml
|
|
@ -1,45 +1,28 @@
|
|||
# This is a Docker Compose file for the InfluxData documentation site.
|
||||
## Run documentation tests for code samples.
|
||||
name: influxdata-docs
|
||||
volumes:
|
||||
test-content:
|
||||
secrets:
|
||||
influxdb2-admin-username:
|
||||
file: ~/.env.influxdb2-admin-username
|
||||
influxdb2-admin-password:
|
||||
file: ~/.env.influxdb2-admin-password
|
||||
influxdb2-admin-token:
|
||||
file: ~/.env.influxdb2-admin-token
|
||||
services:
|
||||
markdownlint:
|
||||
image: davidanson/markdownlint-cli2:v0.13.0
|
||||
container_name: markdownlint
|
||||
profiles:
|
||||
- ci
|
||||
- lint
|
||||
volumes:
|
||||
- type: bind
|
||||
source: .
|
||||
target: /workdir
|
||||
working_dir: /workdir
|
||||
build:
|
||||
context: .
|
||||
vale:
|
||||
image: jdkato/vale:latest
|
||||
container_name: vale
|
||||
profiles:
|
||||
- ci
|
||||
- lint
|
||||
volumes:
|
||||
- type: bind
|
||||
source: .
|
||||
target: /workdir
|
||||
working_dir: /workdir
|
||||
entrypoint: ["/bin/vale"]
|
||||
build:
|
||||
context: .
|
||||
dockerfile_inline: |
|
||||
COPY .ci /src/.ci
|
||||
COPY **/.vale.ini /src/
|
||||
## Run InfluxData documentation with the hugo development server on port 1313.
|
||||
## For more information about the hugomods/hugo image, see
|
||||
## https://docker.hugomods.com/docs/development/docker-compose/
|
||||
local-dev:
|
||||
image: hugomods/hugo:exts-0.123.8
|
||||
build:
|
||||
context: .
|
||||
dockerfile_inline: |
|
||||
FROM hugomods/hugo:exts-0.123.8
|
||||
RUN apk add --no-cache curl openssl
|
||||
command: hugo server --bind 0.0.0.0
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "-f", "http://localhost:1313/influxdb/cloud-dedicated/"]
|
||||
interval: 1m
|
||||
timeout: 10s
|
||||
retries: 2
|
||||
start_period: 40s
|
||||
start_interval: 5s
|
||||
ports:
|
||||
- 1313:1313
|
||||
volumes:
|
||||
|
|
@ -49,3 +32,355 @@ services:
|
|||
- type: bind
|
||||
source: $HOME/hugo_cache
|
||||
target: /tmp/hugo_cache
|
||||
profiles:
|
||||
- local
|
||||
- lint
|
||||
cloud-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/influxdb/cloud/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/influxdb/cloud
|
||||
profiles:
|
||||
- test
|
||||
- v2
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/influxdb/cloud/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: cloud-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
cloud-dedicated-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/influxdb/cloud-dedicated/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/influxdb/cloud-dedicated
|
||||
profiles:
|
||||
- test
|
||||
- v3
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/influxdb/cloud-dedicated/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# The following mount assumes your influxctl configuration file is located at ./content/influxdb/cloud-dedicated/config.toml.
|
||||
- type: bind
|
||||
source: ./content/influxdb/cloud-dedicated/config.toml
|
||||
target: /root/.config/influxctl/config.toml
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: cloud-dedicated-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
cloud-serverless-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/influxdb/cloud-serverless/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/influxdb/cloud-serverless
|
||||
profiles:
|
||||
- test
|
||||
- v3
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/influxdb/cloud-serverless/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: cloud-serverless-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
clustered-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/influxdb/clustered/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/influxdb/clustered
|
||||
profiles:
|
||||
- test
|
||||
- v3
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/influxdb/clustered/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# The following mount assumes your influxctl configuration file is located at ./content/influxdb/clustered/config.toml.
|
||||
- type: bind
|
||||
source: ./content/influxdb/clustered/config.toml
|
||||
target: /root/.config/influxctl/config.toml
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: clustered-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
telegraf-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/telegraf/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/telegraf
|
||||
profiles:
|
||||
- test
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/telegraf/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: telegraf-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
v2-pytest:
|
||||
image: influxdata/docs-pytest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile.pytest
|
||||
entrypoint:
|
||||
- /bin/bash
|
||||
- /src/test/scripts/run-tests.sh
|
||||
- pytest
|
||||
command:
|
||||
# In the command, pass file paths to test.
|
||||
# The container preprocesses the files for testing and runs the tests.
|
||||
- content/influxdb/v2/**/*.md
|
||||
environment:
|
||||
- CONTENT_PATH=content/influxdb/v2
|
||||
profiles:
|
||||
- test
|
||||
- v2
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
# Site configuration files.
|
||||
- type: bind
|
||||
source: .
|
||||
target: /src
|
||||
read_only: true
|
||||
# Files shared between host and container and writeable by both.
|
||||
- type: bind
|
||||
source: ./test/shared
|
||||
target: /shared
|
||||
- type: bind
|
||||
source: ./content/influxdb/v2/.env.test
|
||||
target: /app/.env.test
|
||||
read_only: true
|
||||
# In your code samples, use `/app/data/<FILE.lp>` or `data/<FILE.lp>` to access sample data files from the `static/downloads` directory.
|
||||
- type: bind
|
||||
source: ./static/downloads
|
||||
target: /app/data
|
||||
read_only: true
|
||||
# In your code samples, use `/app/iot-starter` to store example modules or project files.
|
||||
- type: volume
|
||||
source: v2-tmp
|
||||
target: /app/iot-starter
|
||||
# Target directory for the content under test.
|
||||
# Files are copied from /src/content/<productpath> to /app/content/<productpath> before running tests.
|
||||
- type: volume
|
||||
source: test-content
|
||||
target: /app/content
|
||||
working_dir: /app
|
||||
influxdb2:
|
||||
image: influxdb:2
|
||||
ports:
|
||||
- 8086:8086
|
||||
environment:
|
||||
DOCKER_INFLUXDB_INIT_MODE: setup
|
||||
DOCKER_INFLUXDB_INIT_USERNAME_FILE: /run/secrets/influxdb2-admin-username
|
||||
DOCKER_INFLUXDB_INIT_PASSWORD_FILE: /run/secrets/influxdb2-admin-password
|
||||
DOCKER_INFLUXDB_INIT_ADMIN_TOKEN_FILE: /run/secrets/influxdb2-admin-token
|
||||
DOCKER_INFLUXDB_INIT_ORG: docs
|
||||
DOCKER_INFLUXDB_INIT_BUCKET: get-started
|
||||
INFLUX_ORG: docs
|
||||
INFLUX_BUCKET: get-started
|
||||
profiles:
|
||||
- v2
|
||||
- local
|
||||
secrets:
|
||||
- influxdb2-admin-username
|
||||
- influxdb2-admin-password
|
||||
- influxdb2-admin-token
|
||||
volumes:
|
||||
- type: volume
|
||||
source: influxdb2-data
|
||||
target: /var/lib/influxdb2
|
||||
- type: volume
|
||||
source: influxdb2-config
|
||||
target: /etc/influxdb2
|
||||
remark-lint:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: .ci/Dockerfile.remark
|
||||
command: ["remark", "${CONTENT_PATH}"]
|
||||
profiles:
|
||||
- lint
|
||||
volumes:
|
||||
- type: bind
|
||||
source: ./content
|
||||
target: /app/content
|
||||
volumes:
|
||||
test-content:
|
||||
cloud-tmp:
|
||||
cloud-dedicated-tmp:
|
||||
cloud-serverless-tmp:
|
||||
clustered-tmp:
|
||||
telegraf-tmp:
|
||||
v2-tmp:
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
settings:
|
||||
bullet: "-"
|
||||
|
||||
plugins:
|
||||
# Before you can configure plugins for remark here, you need to add them to
|
||||
# the `devDependencies` in the `package.json` file--for CI: `/.ci/app/package.json`.
|
||||
- remark-frontmatter
|
||||
- remark-lint-frontmatter-schema
|
||||
- remark-lint-no-shell-dollars
|
||||
# Check that markdown is consistent (list items have the same indentation)
|
||||
- remark-preset-lint-consistent
|
||||
# - remark-preset-lint-markdown-style-guide
|
||||
# - remark-preset-lint-recommended
|
||||
|
|
@ -19,12 +19,37 @@ InfluxDB Enterprise builds are available. For more information, see
|
|||
[FIPS-compliant InfluxDB Enterprise builds](/enterprise_influxdb/v1/introduction/installation/fips-compliant/).
|
||||
{{% /note %}}
|
||||
|
||||
## v1.11.6 {date="2024-08-02"}
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Prevent retention service from hanging, which could lead to a failure to remove old shards.
|
||||
- Fix shard precreation service to pre-create shards for more than the first database.
|
||||
- Fix issues with remote iterators caused by floating point literals being rounded in a way that causes precision loss and can drastically change the result.
|
||||
This impacts InfluxQL statements that require creating remote iterators.
|
||||
Clusters with replication across all data nodes are unlikely to see this issue.
|
||||
The additional visible changes of this fix include:
|
||||
- Changes precision of floating point numbers in error messages related to InfluxQL.
|
||||
- Changes precision of floating point numbers in "EXPLAIN" and "EXPLAIN ANALYZE" output.
|
||||
- Changes precision of floating point numbers from InfluxQL expressions included in tracing spans.
|
||||
- Fix panic when empty tags are queried.
|
||||
- Fix `influx_inspect` error when deleting last measurement.
|
||||
- Improve TSM error handling.
|
||||
|
||||
### Other
|
||||
|
||||
- Upgrade Flux to v0.194.5.
|
||||
- Upgrade Go to 1.21.10.
|
||||
- Upgrade `protobuf` library.
|
||||
|
||||
---
|
||||
|
||||
## v1.11.5 {date="2024-02-14"}
|
||||
|
||||
{{% note %}}
|
||||
#### Upgrading from InfluxDB Enterprise v1.11.3
|
||||
|
||||
If upgrading from InfluxDB Enterprise v1.11.3 to {{< latest-patch >}}, you can
|
||||
If upgrading from InfluxDB Enterprise v1.11.3+ to {{< latest-patch >}}, you can
|
||||
now configure whether or not InfluxDB compacts series files on startup using the
|
||||
[`compact-series-file` configuration option](/enterprise_influxdb/v1/administration/configure/config-data-nodes/#compact-series-file)
|
||||
in your [InfluxDB Enterprise data node configuration file](/enterprise_influxdb/v1/administration/configure/config-data-nodes/).
|
||||
|
|
|
|||
|
|
@ -3,7 +3,9 @@ title: Work with Prometheus
|
|||
description: >
|
||||
Flux provides tools for scraping and processing raw [Prometheus-formatted metrics](https://prometheus.io/docs/concepts/data_model/)
|
||||
from an HTTP-accessible endpoint.
|
||||
menu: flux_0_x
|
||||
menu:
|
||||
flux_v0:
|
||||
name: Work with Prometheus
|
||||
weight: 8
|
||||
flux/v0/tags: [prometheus]
|
||||
---
|
||||
|
|
|
|||
|
|
@ -2,7 +2,9 @@
|
|||
title: Query data sources
|
||||
description: >
|
||||
Query different data sources with Flux including InfluxDB, SQL databases, CSV, and Prometheus.
|
||||
menu: flux_0_x
|
||||
menu:
|
||||
flux_v0:
|
||||
name: Query data sources
|
||||
weight: 5
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,9 @@
|
|||
title: Write to data sources
|
||||
description: >
|
||||
Write to different data sources with Flux including InfluxDB, SQL databases, CSV, and Prometheus.
|
||||
menu: flux_0_x
|
||||
menu:
|
||||
flux_v0:
|
||||
name: Write to data sources
|
||||
weight: 5
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -1,14 +1,17 @@
|
|||
StylesPath = "../../../.ci/vale/styles"
|
||||
|
||||
Vocab = Cloud-Dedicated
|
||||
Vocab = InfluxDataDocs
|
||||
|
||||
MinAlertLevel = warning
|
||||
|
||||
Packages = Google, Hugo, write-good
|
||||
Packages = Google, write-good, Hugo
|
||||
|
||||
[*.md]
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Google, write-good
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Cloud-Dedicated, Google, write-good
|
||||
|
||||
Google.Acronyms = NO
|
||||
Google.DateFormat = NO
|
||||
Google.Ellipses = NO
|
||||
Google.Headings = NO
|
||||
Google.WordList = NO
|
||||
Google.WordList = NO
|
||||
Vale.Spelling = NO
|
||||
|
|
@ -335,7 +335,7 @@ _For more information about the query lifecycle, see
|
|||
##### Query example
|
||||
|
||||
Consider the following query that selects everything in the `production` table
|
||||
where the `line` tag is `A` and the `station` tag is `1`:
|
||||
where the `line` tag is `A` and the `station` tag is `cnc`:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
|
|
|
|||
|
|
@ -33,7 +33,7 @@ table.
|
|||
#### Partition templates can only be applied on create
|
||||
|
||||
You can only apply a partition template when creating a database or table.
|
||||
There is no way to update a partition template on an existing resource.
|
||||
You can't update a partition template on an existing resource.
|
||||
{{% /note %}}
|
||||
|
||||
Use the following command flags to identify
|
||||
|
|
@ -71,6 +71,9 @@ The following example creates a new `example-db` database and applies a partitio
|
|||
template that partitions by distinct values of two tags (`room` and `sensor-type`),
|
||||
bucketed values of the `customerID` tag, and by week using the time format `%Y wk:%W`:
|
||||
|
||||
<!--Skip database create and delete tests: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--template-tag room \
|
||||
|
|
@ -82,21 +85,60 @@ influxctl database create \
|
|||
|
||||
## Create a table with a custom partition template
|
||||
|
||||
The following example creates a new `example-table` table in the `example-db`
|
||||
The following example creates a new `example-table` table in the specified
|
||||
database and applies a partition template that partitions by distinct values of
|
||||
two tags (`room` and `sensor-type`), bucketed values of the `customerID` tag,
|
||||
and by month using the time format `%Y-%m`:
|
||||
|
||||
<!--Skip database create and delete tests: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME" %}}
|
||||
|
||||
```sh
|
||||
influxctl table create \
|
||||
--template-tag room \
|
||||
--template-tag sensor-type \
|
||||
--template-tag-bucket customerID,500 \
|
||||
--template-timeformat '%Y-%m' \
|
||||
example-db \
|
||||
DATABASE_NAME \
|
||||
example-table
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following in your command:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}: your {{% product-name %}} [database](/influxdb/cloud-dedicated/admin/databases/)
|
||||
|
||||
<!--actual test
|
||||
|
||||
```sh
|
||||
|
||||
# Test the preceding command outside of the code block.
|
||||
# influxctl authentication requires TTY interaction--
|
||||
# output the auth URL to a file that the host can open.
|
||||
|
||||
TABLE_NAME=table_TEST_RUN
|
||||
script -c "influxctl table create \
|
||||
--template-tag room \
|
||||
--template-tag sensor-type \
|
||||
--template-tag-bucket customerID,500 \
|
||||
--template-timeformat '%Y-%m' \
|
||||
DATABASE_NAME \
|
||||
$TABLE_NAME" \
|
||||
/dev/null > /shared/urls.txt
|
||||
|
||||
script -c "influxctl query \
|
||||
--database DATABASE_NAME \
|
||||
--token DATABASE_TOKEN \
|
||||
'SHOW TABLES'" > /shared/temp_tables.txt
|
||||
grep -q $TABLE_NAME /shared/temp_tables.txt
|
||||
rm /shared/temp_tables.txt
|
||||
```
|
||||
|
||||
-->
|
||||
|
||||
## Example partition templates
|
||||
|
||||
Given the following [line protocol](/influxdb/cloud-dedicated/reference/syntax/line-protocol/)
|
||||
|
|
@ -108,7 +150,7 @@ prod,line=A,station=weld1 temp=81.9,qty=36i 1704067200000000000
|
|||
|
||||
##### Partitioning by distinct tag values
|
||||
|
||||
| Description | Tag part(s) | Time part | Resulting partition key |
|
||||
| Description | Tag parts | Time part | Resulting partition key |
|
||||
| :---------------------- | :---------------- | :--------- | :----------------------- |
|
||||
| By day (default) | | `%Y-%m-%d` | 2024-01-01 |
|
||||
| By day (non-default) | | `%d %b %Y` | 01 Jan 2024 |
|
||||
|
|
|
|||
|
|
@ -10,20 +10,22 @@ menu:
|
|||
parent: Manage databases
|
||||
weight: 201
|
||||
list_code_example: |
|
||||
<!--pytest.mark.skip-->
|
||||
##### CLI
|
||||
```sh
|
||||
influxctl database create \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250 \
|
||||
<DATABASE_NAME>
|
||||
DATABASE_NAME
|
||||
```
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
##### API
|
||||
```sh
|
||||
curl \
|
||||
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases" \
|
||||
--request POST
|
||||
--request POST \
|
||||
--header "Accept: application/json" \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
|
||||
|
|
@ -103,6 +105,9 @@ to create a database in your {{< product-name omit=" Clustered" >}} cluster.
|
|||
_{{< product-name >}} supports up to 7 total tags or tag buckets in the partition template._
|
||||
{{% /note %}}
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME|30d|500|100|300|(TAG_KEY(_\d)?)" %}}
|
||||
|
||||
```sh
|
||||
|
|
@ -127,11 +132,15 @@ Replace the following in your command:
|
|||
|
||||
## Database attributes
|
||||
|
||||
- [Retention period syntax (influxctl CLI)](#retention-period-syntax-influxctl-cli)
|
||||
- [Custom partitioning (influxctl CLI)](#custom-partitioning-influxctl-cli)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
- [Database attributes](#database-attributes)
|
||||
- [Retention period syntax (influxctl CLI)](#retention-period-syntax-influxctl-cli)
|
||||
- [Custom partitioning (influxctl CLI)](#custom-partitioning-influxctl-cli)
|
||||
- [Database attributes](#database-attributes-1)
|
||||
- [Retention period syntax (Management API)](#retention-period-syntax-management-api)
|
||||
- [Custom partitioning (Management API)](#custom-partitioning-management-api)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
|
||||
### Retention period syntax (influxctl CLI)
|
||||
|
||||
|
|
@ -190,7 +199,7 @@ For more information, see [Manage data partitioning](/influxdb/cloud-dedicated/a
|
|||
#### Partition templates can only be applied on create
|
||||
|
||||
You can only apply a partition template when creating a database.
|
||||
There is no way to update a partition template on an existing database.
|
||||
You can't update a partition template on an existing database.
|
||||
{{% /note %}}
|
||||
|
||||
<!-------------------------------- END INFLUXCTL ------------------------------>
|
||||
|
|
@ -237,12 +246,15 @@ _{{< product-name >}} supports up to 7 total tags or tag buckets in the partitio
|
|||
|
||||
The following example shows how to use the Management API to create a database with custom partitioning:
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME|2592000000000|500|100|300|250|ACCOUNT_ID|CLUSTER_ID|MANAGEMENT_TOKEN|(TAG_KEY(_\d)?)" %}}
|
||||
|
||||
```sh
|
||||
curl \
|
||||
--location "https://console.influxdata.com/api/v0/accounts/ACCOUNT_ID/clusters/CLUSTER_ID/databases" \
|
||||
--request POST
|
||||
--request POST \
|
||||
--header "Accept: application/json" \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header "Authorization: Bearer MANAGEMENT_TOKEN" \
|
||||
|
|
@ -294,11 +306,15 @@ Replace the following in your request:
|
|||
|
||||
## Database attributes
|
||||
|
||||
- [Retention period syntax (Management API)](#retention-period-syntax-management-api)
|
||||
- [Custom partitioning (Management API)](#custom-partitioning-management-api)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
- [Database attributes](#database-attributes)
|
||||
- [Retention period syntax (influxctl CLI)](#retention-period-syntax-influxctl-cli)
|
||||
- [Custom partitioning (influxctl CLI)](#custom-partitioning-influxctl-cli)
|
||||
- [Database attributes](#database-attributes-1)
|
||||
- [Retention period syntax (Management API)](#retention-period-syntax-management-api)
|
||||
- [Custom partitioning (Management API)](#custom-partitioning-management-api)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
|
||||
### Retention period syntax (Management API)
|
||||
|
||||
|
|
@ -334,7 +350,7 @@ For more information, see [Manage data partitioning](/influxdb/cloud-dedicated/a
|
|||
#### Partition templates can only be applied on create
|
||||
|
||||
You can only apply a partition template when creating a database.
|
||||
There is no way to update a partition template on an existing database.
|
||||
You can't update a partition template on an existing database.
|
||||
{{% /note %}}
|
||||
|
||||
<!------------------------------- END cURL ------------------------------------>
|
||||
|
|
@ -364,7 +380,7 @@ database and retention policy (DBRP) to be queryable with InfluxQL.
|
|||
**When naming a database that you want to query with InfluxQL**, use the following
|
||||
naming convention to automatically map v1 DBRP combinations to an {{% product-name %}} database:
|
||||
|
||||
```sh
|
||||
```text
|
||||
database_name/retention_policy_name
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -15,8 +15,8 @@ list_code_example: |
|
|||
influxctl database update \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250
|
||||
<DATABASE_NAME>
|
||||
--max-columns 250 \
|
||||
DATABASE_NAME
|
||||
```
|
||||
|
||||
##### API
|
||||
|
|
@ -56,18 +56,19 @@ to update a database in your {{< product-name omit=" Clustered" >}} cluster.
|
|||
2. In your terminal, run the `influxctl database update` command and provide the following:
|
||||
|
||||
- Database name
|
||||
- _Optional_: Database [retention period](/influxdb/cloud-dedicated/admin/databases/#retention-periods)
|
||||
Default is `infinite` (`0`).
|
||||
- _Optional_: Database [retention period](/influxdb/cloud-dedicated/admin/databases/#retention-periods).
|
||||
Default is infinite (`0`).
|
||||
- _Optional_: Database table (measurement) limit. Default is `500`.
|
||||
- _Optional_: Database column limit. Default is `250`.
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME|30d|500|200" %}}
|
||||
|
||||
```sh
|
||||
influxctl database update DATABASE_NAME \
|
||||
influxctl database update \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250
|
||||
--max-columns 250 \
|
||||
DATABASE_NAME
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
|
@ -76,6 +77,13 @@ Replace the following in your command:
|
|||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}: your {{% product-name %}} [database](/influxdb/cloud-dedicated/admin/databases/)
|
||||
|
||||
{{% warn %}}
|
||||
#### Database names can't be updated
|
||||
|
||||
The `influxctl database update` command uses the database name to identify which
|
||||
database to apply updates to. The database name itself can't be updated.
|
||||
{{% /warn %}}
|
||||
|
||||
## Database attributes
|
||||
|
||||
- [Retention period syntax](#retention-period-syntax-influxctl-cli)
|
||||
|
|
@ -91,7 +99,7 @@ for the database.
|
|||
The retention period value is a time duration value made up of a numeric value
|
||||
plus a duration unit.
|
||||
For example, `30d` means 30 days.
|
||||
A zero duration (`0d`) retention period is infinite and data won't expire.
|
||||
A zero duration (for example, `0s` or `0d`) retention period is infinite and data won't expire.
|
||||
The retention period value cannot be negative or contain whitespace.
|
||||
|
||||
{{< flex >}}
|
||||
|
|
@ -211,13 +219,15 @@ The retention period value cannot be negative or contain whitespace.
|
|||
|
||||
#### Database names can't be updated
|
||||
|
||||
The `influxctl database update` command uses the database name to identify which
|
||||
database to apply updates to. The database name itself can't be updated.
|
||||
The Management API `PATCH /api/v0/database` endpoint and
|
||||
the`influxctl database update` command use the database name to identify which
|
||||
database to apply updates to.
|
||||
The database name itself can't be updated.
|
||||
|
||||
#### Partition templates can't be updated
|
||||
|
||||
You can only apply a partition template when creating a database.
|
||||
There is no way to update a partition template on an existing database.
|
||||
You can't update a partition template on an existing database.
|
||||
{{% /warn %}}
|
||||
|
||||
### Database naming restrictions
|
||||
|
|
@ -234,7 +244,7 @@ Database names must adhere to the following naming restrictions:
|
|||
|
||||
In InfluxDB 1.x, data is stored in [databases](/influxdb/v1/concepts/glossary/#database)
|
||||
and [retention policies](/influxdb/v1/concepts/glossary/#retention-policy-rp).
|
||||
In InfluxDB Cloud Dedicated, databases and retention policies have been merged into
|
||||
In {{< product-name >}}, databases and retention policies have been merged into
|
||||
_databases_, where databases have a retention period, but retention policies
|
||||
are no longer part of the data model.
|
||||
Because InfluxQL uses the 1.x data model, a database must be mapped to a v1
|
||||
|
|
@ -243,7 +253,7 @@ database and retention policy (DBRP) to be queryable with InfluxQL.
|
|||
**When naming a database that you want to query with InfluxQL**, use the following
|
||||
naming convention to automatically map v1 DBRP combinations to a database:
|
||||
|
||||
```sh
|
||||
```text
|
||||
database_name/retention_policy_name
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -174,21 +174,33 @@ can write data to {{% product-name %}}.
|
|||
## Authorization
|
||||
|
||||
**{{% product-name %}} requires authentication** using
|
||||
[tokens](/influxdb/cloud-dedicated/admin/tokens/).
|
||||
|
||||
There are two types of tokens:
|
||||
one of the following [token](/influxdb/cloud-dedicated/admin/tokens/) types:
|
||||
|
||||
- **Database token**: A token that grants read and write access to InfluxDB
|
||||
databases.
|
||||
- **Management token**: A short-lived (1 hour) [Auth0 token](#) used to
|
||||
administer your InfluxDB cluster. These are generated by the `influxctl` CLI
|
||||
and do not require any direct management. Management tokens authorize a user
|
||||
to perform tasks related to:
|
||||
- **Management token**:
|
||||
[Auth0 authentication token](/influxdb/cloud-dedicated/reference/internals/security/#access-authentication-and-authorization) generated by the `influxctl` CLI and used to administer your InfluxDB cluster.
|
||||
Management tokens authorize a user to perform tasks related to:
|
||||
|
||||
- Account management
|
||||
- Database management
|
||||
- Database token management
|
||||
- Pricing
|
||||
|
||||
By default, management tokens are
|
||||
|
||||
- short-lived
|
||||
- issued for a specific user
|
||||
- issued by an OAuth2 identity provider
|
||||
- managed by `influxctl` and don't require management by users
|
||||
|
||||
However, for automation purposes, an `influxctl` user can
|
||||
[manually create a long-lived
|
||||
management token](/influxdb/cloud-dedicated/admin/tokens/management/#create-a-management-token)
|
||||
for use with the
|
||||
[Management API for Cloud Dedicated](/influxdb/cloud-dedicated/api/management).
|
||||
Manually-created management tokens authenticate directly with your InfluxDB
|
||||
cluster and don't require human interaction with your identity provider.
|
||||
<!-- - Infrastructure management -->
|
||||
|
||||
{{< page-nav next="/influxdb/clustered/get-started/setup/" >}}
|
||||
|
|
|
|||
|
|
@ -35,8 +35,10 @@ the simplicity of SQL.
|
|||
|
||||
{{% note %}}
|
||||
The examples in this section of the tutorial query the
|
||||
[**get-started** database](/influxdb/cloud-dedicated/get-started/setup/#create-a-database) for data written in the
|
||||
[Get started writing data](/influxdb/cloud-dedicated/get-started/write/#write-line-protocol-to-influxdb) section.
|
||||
[**get-started** database](/influxdb/cloud-dedicated/get-started/setup/#create-a-database)
|
||||
for data written in the
|
||||
[Get started writing data](/influxdb/cloud-dedicated/get-started/write/#write-line-protocol-to-influxdb)
|
||||
section.
|
||||
{{% /note %}}
|
||||
|
||||
## Tools to execute queries
|
||||
|
|
@ -202,9 +204,47 @@ WHERE
|
|||
```
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
||||
<!--setup-test
|
||||
```sh
|
||||
curl --silent \
|
||||
"https://{{< influxdb/host >}}/write?db=get-started&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--header "Content-type: text/plain; charset=utf-8" \
|
||||
--header "Accept: application/json" \
|
||||
--data-binary "
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719907200
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719907200
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719910800
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719910800
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719914400
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719914400
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719918000
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719918000
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719921600
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719921600
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719925200
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719925200
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719928800
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719928800
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719932400
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719932400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719936000
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719936000
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719939600
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719939600
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719943200
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719943200
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719946800
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719946800
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719950400
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719950400
|
||||
"
|
||||
```
|
||||
-->
|
||||
|
||||
{{% note %}}
|
||||
Some examples in this getting started tutorial assume your InfluxDB
|
||||
credentials (**URL**, and **token**) are provided by
|
||||
credentials (**URL** and **token**) are provided by
|
||||
[environment variables](/influxdb/cloud-dedicated/get-started/setup/?t=InfluxDB+API#configure-authentication-credentials).
|
||||
{{% /note %}}
|
||||
|
||||
|
|
@ -233,21 +273,33 @@ Provide the following:
|
|||
|
||||
{{% influxdb/custom-timestamps %}}
|
||||
{{% code-placeholders "get-started" %}}
|
||||
|
||||
```sh
|
||||
influxctl query \
|
||||
--database get-started \
|
||||
--token $INFLUX_TOKEN \
|
||||
"SELECT
|
||||
*
|
||||
FROM
|
||||
home
|
||||
WHERE
|
||||
time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T20:00:00Z'"
|
||||
*
|
||||
FROM
|
||||
home
|
||||
WHERE
|
||||
time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T20:00:00Z'"
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
||||
{{% note %}}
|
||||
#### Query using stored credentials
|
||||
|
||||
Optionally, you can configure `database` and `token` query credentials in your `influxctl`
|
||||
[connection profile](/influxdb/clustered/reference/cli/influxctl/#create-a-configuration-file).
|
||||
|
||||
The `--database` and `--token` command line flags override credentials in your
|
||||
configuration file.
|
||||
{{% /note %}}
|
||||
|
||||
<!--------------------------- END influxctl CONTENT --------------------------->
|
||||
{{% /tab-content %}}
|
||||
{{% tab-content %}}
|
||||
|
|
@ -262,15 +314,15 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
1. Create a directory for your project and change into it:
|
||||
|
||||
```sh
|
||||
mkdir influx3-query-example && cd $_
|
||||
```bash
|
||||
mkdir -p influx3-query-example && cd influx3-query-example
|
||||
```
|
||||
|
||||
2. To create and activate a Python virtual environment, run the following command:
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
python -m venv envs/virtual-env && . envs/virtual-env/bin/activate
|
||||
```
|
||||
|
||||
|
|
@ -278,7 +330,7 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
pip install influxdb3-python-cli
|
||||
```
|
||||
|
||||
|
|
@ -290,7 +342,7 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```sh
|
||||
influx3 config \
|
||||
influx3 config create \
|
||||
--name="config-dedicated" \
|
||||
--database="get-started" \
|
||||
--host="{{< influxdb/host >}}" \
|
||||
|
|
@ -308,12 +360,12 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```sh
|
||||
influx3 sql "SELECT *
|
||||
```sh
|
||||
influx3 sql "SELECT *
|
||||
FROM home
|
||||
WHERE time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T20:00:00Z'"
|
||||
```
|
||||
```
|
||||
|
||||
`influx3` displays query results in your terminal.
|
||||
|
||||
|
|
@ -338,7 +390,7 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
<!-- Run for tests and hide from users.
|
||||
|
||||
```sh
|
||||
mkdir -p influxdb_py_client && cd $_
|
||||
mkdir -p influxdb_py_client && cd influxdb_py_client
|
||||
```
|
||||
-->
|
||||
|
||||
|
|
@ -348,7 +400,7 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
python -m venv envs/virtual-env && . ./envs/virtual-env/bin/activate
|
||||
```
|
||||
|
||||
3. Install the following dependencies:
|
||||
2. Install the following dependencies:
|
||||
|
||||
{{< req type="key" text="Already installed in the [Write data section](/influxdb/cloud-dedicated/get-started/write/?t=Python#write-line-protocol-to-influxdb)" color="magenta" >}}
|
||||
|
||||
|
|
@ -364,7 +416,7 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
pip install influxdb3-python pandas tabulate
|
||||
```
|
||||
|
||||
4. In your terminal or editor, create a new file for your code--for example: `query.py`.
|
||||
3. In your terminal or editor, create a new file for your code--for example: `query.py`.
|
||||
|
||||
2. In `query.py`, enter the following sample code:
|
||||
|
||||
|
|
@ -396,17 +448,23 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
'''
|
||||
|
||||
table = client.query(query=sql)
|
||||
assert table['room'], "Expect table to have room column."
|
||||
assert table.num_rows > 0, "Expect query to return data."
|
||||
assert table['room'], f"Expect ${table} to have room column."
|
||||
print(table.to_pandas().to_markdown())
|
||||
```
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "<span class='req'>Important</span>: If using **Windows**, specify the **Windows** certificate path" %}}
|
||||
|
||||
When instantiating the client, Python looks for SSL/TLS certificate authority (CA) certificates for verifying the server's authenticity.
|
||||
If using a non-POSIX-compliant operating system (such as Windows), you need to specify a certificate bundle path that Python can access on your system.
|
||||
When instantiating the client, Python looks for SSL/TLS certificate authority
|
||||
(CA) certificates for verifying the server's authenticity.
|
||||
If using a non-POSIX-compliant operating system (such as Windows), you need to
|
||||
specify a certificate bundle path that Python can access on your system.
|
||||
|
||||
The following example shows how to use the [Python `certifi` package](https://certifiio.readthedocs.io/en/latest/) and client library options to provide a bundle of trusted certificates to the Python Flight client:
|
||||
The following example shows how to use the
|
||||
[Python `certifi` package](https://certifiio.readthedocs.io/en/latest/) and
|
||||
client library options to provide a bundle of trusted certificates to the
|
||||
Python Flight client:
|
||||
|
||||
1. In your terminal, install the Python `certifi` package.
|
||||
|
||||
|
|
@ -445,29 +503,31 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
2. Calls the `InfluxDBClient3()` constructor method with credentials to instantiate an InfluxDB `client` with the following credentials:
|
||||
|
||||
- **`host`**: {{% product-name omit=" Clustered" %}} cluster URL (without `https://` protocol or trailing slash)
|
||||
- **`host`**: {{% product-name omit=" Clustered" %}} cluster URL
|
||||
(without `https://` protocol or trailing slash)
|
||||
- **`token`**: a [database token](/influxdb/cloud-dedicated/admin/tokens/#database-tokens)
|
||||
with read access to the specified database.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
_Store this in a secret store or environment variable to avoid exposing
|
||||
the raw token string._
|
||||
- **`database`**: the name of the {{% product-name %}} database to query
|
||||
|
||||
3. Defines the SQL query to execute and assigns it to a `query` variable.
|
||||
1. Defines the SQL query to execute and assigns it to a `query` variable.
|
||||
|
||||
4. Calls the `client.query()` method with the SQL query.
|
||||
2. Calls the `client.query()` method with the SQL query.
|
||||
`query()` sends a
|
||||
Flight request to InfluxDB, queries the database, retrieves result data from the endpoint, and then returns a
|
||||
[`pyarrow.Table`](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table)
|
||||
assigned to the `table` variable.
|
||||
|
||||
5. Calls the [`to_pandas()` method](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas)
|
||||
3. Calls the [`to_pandas()` method](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas)
|
||||
to convert the Arrow table to a [`pandas.DataFrame`](https://arrow.apache.org/docs/python/pandas.html).
|
||||
|
||||
6. Calls the [`pandas.DataFrame.to_markdown()` method](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_markdown.html)
|
||||
4. Calls the [`pandas.DataFrame.to_markdown()` method](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_markdown.html)
|
||||
to convert the DataFrame to a markdown table.
|
||||
|
||||
7. Calls the `print()` method to print the markdown table to stdout.
|
||||
5. Calls the `print()` method to print the markdown table to stdout.
|
||||
|
||||
2. Enter the following command to run the program and query your {{% product-name omit=" Clustered" %}} cluster:
|
||||
1. Enter the following command to run the program and query your {{% product-name omit=" Clustered" %}} cluster:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -606,20 +666,25 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
2. Defines a `Query()` function that does the following:
|
||||
|
||||
1. Instantiates `influx.Client` with InfluxDB credentials.
|
||||
1. Instantiates `influx.Client` with the following parameters for InfluxDB credentials:
|
||||
|
||||
- **`Host`**: your {{% product-name omit=" Clustered" %}} cluster URL
|
||||
- **`Database`**: The name of your {{% product-name %}} database
|
||||
- **`Database`**: the name of your {{% product-name %}} database
|
||||
- **`Token`**: a [database token](/influxdb/cloud-dedicated/admin/tokens/#database-tokens)
|
||||
with read permission on the specified database.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
_Store this in a secret store or environment variable to avoid
|
||||
exposing the raw token string._
|
||||
|
||||
2. Defines a deferred function to close the client after execution.
|
||||
3. Defines a string variable for the SQL query.
|
||||
|
||||
4. Calls the `influxdb3.Client.Query(sql string)` method and passes the SQL string to query InfluxDB.
|
||||
`Query(sql string)` method returns an `iterator` for data in the response stream.
|
||||
5. Iterates over rows, formats the timestamp as an [RFC3339 timestamp](/influxdb/cloud-dedicated/reference/glossary/#rfc3339-timestamp), and prints the data in table format to stdout.
|
||||
4. Calls the `influxdb3.Client.Query(sql string)` method and passes the
|
||||
SQL string to query InfluxDB.
|
||||
The `Query(sql string)` method returns an `iterator` for data in the
|
||||
response stream.
|
||||
5. Iterates over rows, formats the timestamp as an
|
||||
[RFC3339 timestamp](/influxdb/cloud-dedicated/reference/glossary/#rfc3339-timestamp),
|
||||
and prints the data in table format to stdout.
|
||||
|
||||
3. In your editor, open the `main.go` file you created in the
|
||||
[Write data section](/influxdb/cloud-dedicated/get-started/write/?t=Go#write-line-protocol-to-influxdb) and insert code to call the `Query()` function--for example:
|
||||
|
|
@ -633,12 +698,13 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
}
|
||||
```
|
||||
|
||||
4. In your terminal, enter the following command to install the necessary packages, build the module, and run the program:
|
||||
4. In your terminal, enter the following command to install the necessary
|
||||
packages, build the module, and run the program:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
go mod tidy && go build && go run influxdb_go_client
|
||||
go mod tidy && go run influxdb_go_client
|
||||
```
|
||||
|
||||
The program executes the `main()` function that writes the data and prints the query results to the console.
|
||||
|
|
@ -724,18 +790,19 @@ _This tutorial assumes you installed Node.js and npm, and created an `influxdb_j
|
|||
- **`host`**: your {{% product-name omit=" Clustered" %}} cluster URL
|
||||
- **`token`**: a [database token](/influxdb/cloud-dedicated/admin/tokens/#database-tokens)
|
||||
with read permission on the database you want to query.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
_Store this in a secret store or environment variable to avoid exposing
|
||||
the raw token string._
|
||||
|
||||
3. Defines a string variable (`sql`) for the SQL query.
|
||||
4. Defines an object (`data`) with column names for keys and array values for storing row data.
|
||||
5. Calls the `InfluxDBClient.query()` method with the following arguments:
|
||||
1. Defines a string variable (`sql`) for the SQL query.
|
||||
2. Defines an object (`data`) with column names for keys and array values for storing row data.
|
||||
3. Calls the `InfluxDBClient.query()` method with the following arguments:
|
||||
|
||||
- **`sql`**: the query to execute
|
||||
- **`database`**: the name of the {{% product-name %}} database to query
|
||||
|
||||
`query()` returns a stream of row vectors.
|
||||
6. Iterates over rows and adds the column data to the arrays in `data`.
|
||||
7. Passes `data` to the Arrow `tableFromArrays()` function to format the arrays as a table, and then passes the result to the `console.table()` method to output a highlighted table in the terminal.
|
||||
4. Iterates over rows and adds the column data to the arrays in `data`.
|
||||
5. Passes `data` to the Arrow `tableFromArrays()` function to format the arrays as a table, and then passes the result to the `console.table()` method to output a highlighted table in the terminal.
|
||||
5. Inside of `index.mjs` (created in the [Write data section](/influxdb/cloud-dedicated/get-started/write/?t=Nodejs)), enter the following sample code to import the modules and call the functions:
|
||||
|
||||
```js
|
||||
|
|
@ -756,7 +823,7 @@ _This tutorial assumes you installed Node.js and npm, and created an `influxdb_j
|
|||
main();
|
||||
```
|
||||
|
||||
9. In your terminal, execute `index.mjs` to write to and query {{% product-name %}}:
|
||||
6. In your terminal, execute `index.mjs` to write to and query {{% product-name %}}:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -1014,7 +1081,7 @@ _This tutorial assumes using Maven version 3.9, Java version >= 15, and an `infl
|
|||
|
||||
- The `App`, `Write`, and `Query` classes belong to the `com.influxdbv3` package (your project **groupId**).
|
||||
- `App` defines a `main()` function that calls `Write.writeLineProtocol()` and `Query.querySQL()`.
|
||||
4. In your terminal or editor, use Maven to to install dependencies and compile the project code--for example:
|
||||
4. In your terminal or editor, use Maven to install dependencies and compile the project code--for example:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -1029,8 +1096,6 @@ _This tutorial assumes using Maven version 3.9, Java version >= 15, and an `infl
|
|||
|
||||
**Linux/MacOS**
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
export MAVEN_OPTS="--add-opens=java.base/java.nio=ALL-UNNAMED"
|
||||
```
|
||||
|
|
|
|||
|
|
@ -45,16 +45,16 @@ following information:
|
|||
## Download, install, and configure the influxctl CLI
|
||||
|
||||
The [`influxctl` CLI](/influxdb/cloud-dedicated/reference/cli/influxctl/)
|
||||
provides a simple way to manage your InfluxDB Cloud Dedicated cluster from a
|
||||
command line. It lets you perform administrative tasks such as managing
|
||||
lets you manage your {{< product-name omit="Clustered" >}} cluster from a
|
||||
command line and perform administrative tasks such as managing
|
||||
databases and tokens.
|
||||
|
||||
1. [Download and install the `influxctl` CLI](/influxdb/cloud-dedicated/reference/cli/influxctl/#download-and-install-influxctl).
|
||||
|
||||
2. **Create a connection profile and provide your InfluxDB Cloud Dedicated connection credentials**.
|
||||
2. **Create a connection profile and provide your {{< product-name >}} connection credentials**.
|
||||
|
||||
The `influxctl` CLI uses [connection profiles](/influxdb/cloud-dedicated/reference/cli/influxctl/#configure-connection-profiles)
|
||||
to connect to and authenticate with your InfluxDB Cloud Dedicated cluster.
|
||||
to connect to and authenticate with your {{< product-name omit="Clustered" >}} cluster.
|
||||
|
||||
Create a file named `config.toml` at the following location depending on
|
||||
your operating system.
|
||||
|
|
@ -72,7 +72,7 @@ If stored at a non-default location, include the `--config` flag with each
|
|||
|
||||
{{% /note %}}
|
||||
|
||||
**Copy and paste the sample configuration profile code** into your `config.toml`:
|
||||
3. **Copy and paste the sample configuration profile code** into your `config.toml`:
|
||||
|
||||
{{% code-placeholders "ACCOUNT_ID|CLUSTER_ID" %}}
|
||||
|
||||
|
|
@ -97,10 +97,11 @@ _For detailed information about `influxctl` profiles, see
|
|||
|
||||
## Create a database
|
||||
|
||||
Use the [`influxctl database create` command](/influxdb/cloud-dedicated/reference/cli/influxctl/database/create/)
|
||||
Use the
|
||||
[`influxctl database create` command](/influxdb/cloud-dedicated/reference/cli/influxctl/database/create/)
|
||||
to create a database. You can use an existing database or create a new one
|
||||
specifically for this getting started tutorial.
|
||||
_Examples in this getting started tutorial assume a database named **"get-started"**._
|
||||
_Examples in this getting started tutorial assume a database named `get-started`._
|
||||
|
||||
{{% note %}}
|
||||
|
||||
|
|
@ -109,15 +110,19 @@ _Examples in this getting started tutorial assume a database named **"get-starte
|
|||
The first time you run an `influxctl` CLI command, you are directed
|
||||
to login to **Auth0**. Once logged in, Auth0 issues a short-lived (1 hour)
|
||||
management token for the `influxctl` CLI that grants administrative access
|
||||
to your InfluxDB Cloud Dedicated cluster.
|
||||
to your {{< product-name omit="Clustered" >}} cluster.
|
||||
{{% /note %}}
|
||||
|
||||
Provide the following:
|
||||
|
||||
- Database name.
|
||||
- _Optional:_ Database [retention period](/influxdb/cloud-dedicated/admin/databases/#retention-periods)
|
||||
- _Optional:_ Database
|
||||
[retention period](/influxdb/cloud-dedicated/admin/databases/#retention-periods)
|
||||
as a duration value. If no retention period is specified, the default is infinite.
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "get-started|1y" %}}
|
||||
|
||||
```sh
|
||||
|
|
@ -128,7 +133,8 @@ influxctl database create --retention-period 1y get-started
|
|||
|
||||
## Create a database token
|
||||
|
||||
Use the [`influxctl token create` command](/influxdb/cloud-dedicated/reference/cli/influxctl/token/create/)
|
||||
Use the
|
||||
[`influxctl token create` command](/influxdb/cloud-dedicated/reference/cli/influxctl/token/create/)
|
||||
to create a database token with read and write permissions for your database.
|
||||
|
||||
Provide the following:
|
||||
|
|
@ -140,15 +146,24 @@ Provide the following:
|
|||
|
||||
{{% code-placeholders "get-started" %}}
|
||||
|
||||
```sh
|
||||
```bash
|
||||
influxctl token create \
|
||||
--read-database get-started \
|
||||
--write-database get-started \
|
||||
"Read/write token for get-started database"
|
||||
"Read/write token for get-started database" > /app/iot-starter/secret.txt
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
<!--test-cleanup
|
||||
```bash
|
||||
influxctl token delete --force \
|
||||
$(influxctl token list \
|
||||
| grep "Read/write token for get-started database" \
|
||||
| head -n1 | cut -d' ' -f2)
|
||||
```
|
||||
-->
|
||||
|
||||
The command returns the token ID and the token string.
|
||||
Store the token string in a safe place.
|
||||
You'll need it later.
|
||||
|
|
@ -211,6 +226,8 @@ $env:INFLUX_TOKEN = "DATABASE_TOKEN"
|
|||
|
||||
{{% code-placeholders "DATABASE_TOKEN" %}}
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
set INFLUX_TOKEN=DATABASE_TOKEN
|
||||
# Make sure to include a space character at the end of this command.
|
||||
|
|
|
|||
|
|
@ -40,7 +40,8 @@ line protocol for you, but it's good to understand how line protocol works.
|
|||
|
||||
All data written to InfluxDB is written using **line protocol**, a text-based
|
||||
format that lets you provide the necessary information to write a data point to
|
||||
InfluxDB. _This tutorial covers the basics of line protocol, but for detailed
|
||||
InfluxDB.
|
||||
_This tutorial covers the basics of line protocol, but for detailed
|
||||
information, see the
|
||||
[Line protocol reference](/influxdb/cloud-dedicated/reference/syntax/line-protocol/)._
|
||||
|
||||
|
|
@ -163,7 +164,8 @@ The following examples show how to write the preceding
|
|||
[sample data](#home-sensor-data-line-protocol), already in line protocol format,
|
||||
to an {{% product-name %}} database.
|
||||
|
||||
To learn more about available tools and options, see [Write data](/influxdb/cloud-dedicated/write-data/).
|
||||
To learn more about available tools and options, see
|
||||
[Write data](/influxdb/cloud-dedicated/write-data/).
|
||||
|
||||
{{% note %}}
|
||||
Some examples in this getting started tutorial assume your InfluxDB
|
||||
|
|
@ -204,12 +206,12 @@ to write the [home sensor sample data](#home-sensor-data-line-protocol) to your
|
|||
{{% influxdb/custom-timestamps %}}
|
||||
{{% code-placeholders "get-started" %}}
|
||||
|
||||
```sh
|
||||
```bash
|
||||
influxctl write \
|
||||
--database get-started \
|
||||
--token $INFLUX_TOKEN \
|
||||
--precision s \
|
||||
'home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
'home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600
|
||||
|
|
@ -243,12 +245,12 @@ home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200'
|
|||
If successful, the output is the success message; otherwise, error details and
|
||||
the failure message.
|
||||
|
||||
<!----------------------------- END INFLUXCTL CLI CONTENT ----------------------------->
|
||||
<!-------------------------- END INFLUXCTL CLI CONTENT ------------------------>
|
||||
|
||||
{{% /tab-content %}}
|
||||
{{% tab-content %}}
|
||||
|
||||
<!------------------------------- BEGIN TELEGRAF CONTENT ------------------------------>
|
||||
<!-------------------------- BEGIN TELEGRAF CONTENT --------------------------->
|
||||
|
||||
{{% influxdb/custom-timestamps %}}
|
||||
|
||||
|
|
@ -261,7 +263,7 @@ Use [Telegraf](/telegraf/v1/) to consume line protocol, and then write it to
|
|||
2. Copy and save the [home sensor data sample](#home-sensor-data-line-protocol)
|
||||
to a file on your local system--for example, `home.lp`.
|
||||
|
||||
```sh
|
||||
```bash
|
||||
cat <<- EOF > home.lp
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
|
|
@ -296,7 +298,7 @@ Use [Telegraf](/telegraf/v1/) to consume line protocol, and then write it to
|
|||
(`./telegraf.conf`) that enables the `inputs.file` and `outputs.influxdb_v2`
|
||||
plugins:
|
||||
|
||||
```sh
|
||||
```bash
|
||||
telegraf --sample-config \
|
||||
--input-filter file \
|
||||
--output-filter influxdb_v2 \
|
||||
|
|
@ -351,7 +353,7 @@ Use [Telegraf](/telegraf/v1/) to consume line protocol, and then write it to
|
|||
echo '' >> telegraf.conf
|
||||
echo ' organization = ""' >> telegraf.conf
|
||||
echo '' >> telegraf.conf
|
||||
echo ' bucket = "get-started"' >> telegraf.conf
|
||||
echo ' bucket = "${INFLUX_DATABASE}"' >> telegraf.conf
|
||||
```
|
||||
-->
|
||||
|
||||
|
|
@ -371,10 +373,18 @@ Use [Telegraf](/telegraf/v1/) to consume line protocol, and then write it to
|
|||
|
||||
Enter the following command in your terminal:
|
||||
|
||||
```sh
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
telegraf --once --config ./telegraf.conf
|
||||
```
|
||||
|
||||
<!--test
|
||||
```bash
|
||||
telegraf --quiet --once --config ./telegraf.conf
|
||||
```
|
||||
-->
|
||||
|
||||
If the write is successful, the output is similar to the following:
|
||||
|
||||
```plaintext
|
||||
|
|
@ -444,12 +454,13 @@ to InfluxDB:
|
|||
|
||||
{{% code-placeholders "DATABASE_TOKEN" %}}
|
||||
|
||||
```sh
|
||||
response=$(curl --silent --write-out "%{response_code}:%{errormsg}" \
|
||||
```bash
|
||||
response=$(curl --silent \
|
||||
"https://{{< influxdb/host >}}/write?db=get-started&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--header "Content-type: text/plain; charset=utf-8" \
|
||||
--header "Accept: application/json" \
|
||||
--write-out "\n%{response_code}" \
|
||||
--data-binary "
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
|
|
@ -479,16 +490,15 @@ home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641067200
|
|||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
||||
")
|
||||
|
||||
# Format the response code and error message output.
|
||||
response_code=${response%%:*}
|
||||
errormsg=${response#*:}
|
||||
# Extract the response body (all but the last line)
|
||||
response_body=$(echo "$response" | head -n -1)
|
||||
|
||||
# Remove leading and trailing whitespace from errormsg
|
||||
errormsg=$(echo "${errormsg}" | tr -d '[:space:]')
|
||||
# Extract the HTTP status code (the last line)
|
||||
response_code=$(echo "$response" | tail -n 1)
|
||||
|
||||
echo "$response_code"
|
||||
if [[ $errormsg ]]; then
|
||||
echo "$errormsg"
|
||||
if [[ $response_body ]]; then
|
||||
echo "$response_body"
|
||||
fi
|
||||
```
|
||||
|
||||
|
|
@ -556,8 +566,8 @@ to InfluxDB:
|
|||
|
||||
{{% code-placeholders "DATABASE_TOKEN"%}}
|
||||
|
||||
```sh
|
||||
response=$(curl --silent --write-out "%{response_code}:%{errormsg}" \
|
||||
```bash
|
||||
response=$(curl --silent --write-out "%{response_code}:-%{errormsg}" \
|
||||
"https://{{< influxdb/host >}}/api/v2/write?bucket=get-started&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--header "Content-Type: text/plain; charset=utf-8" \
|
||||
|
|
@ -592,8 +602,8 @@ home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
|||
")
|
||||
|
||||
# Format the response code and error message output.
|
||||
response_code=${response%%:*}
|
||||
errormsg=${response#*:}
|
||||
response_code=${response%%:-*}
|
||||
errormsg=${response#*:-}
|
||||
|
||||
# Remove leading and trailing whitespace from errormsg
|
||||
errormsg=$(echo "${errormsg}" | tr -d '[:space:]')
|
||||
|
|
@ -799,7 +809,7 @@ To write data to {{% product-name %}} using Go, use the InfluxDB v3
|
|||
|
||||
2. Initialize a new Go module in the directory.
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
go mod init influxdb_go_client
|
||||
|
|
@ -808,7 +818,7 @@ To write data to {{% product-name %}} using Go, use the InfluxDB v3
|
|||
3. In your terminal or editor, create a new file for your code--for example:
|
||||
`write.go`.
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
touch write.go
|
||||
|
|
@ -953,7 +963,7 @@ To write data to {{% product-name %}} using Go, use the InfluxDB v3
|
|||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
go mod tidy && go run influxdb_go_client
|
||||
```
|
||||
|
||||
|
|
@ -977,15 +987,13 @@ the failure message.
|
|||
`influxdb_js_client` directory for your project:
|
||||
|
||||
```bash
|
||||
mkdir influxdb_js_client && cd influxdb_js_client
|
||||
mkdir -p influxdb_js_client && cd influxdb_js_client
|
||||
```
|
||||
|
||||
3. Inside of `influxdb_js_client`, enter the following command to initialize a
|
||||
package. This example configures the package to use
|
||||
[ECMAScript modules (ESM)](https://nodejs.org/api/packages.html#modules-loaders).
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```bash
|
||||
npm init -y; npm pkg set type="module"
|
||||
```
|
||||
|
|
@ -993,8 +1001,6 @@ the failure message.
|
|||
4. Install the `@influxdata/influxdb3-client` JavaScript client library as a
|
||||
dependency to your project.
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```bash
|
||||
npm install --save @influxdata/influxdb3-client
|
||||
```
|
||||
|
|
@ -1002,7 +1008,6 @@ the failure message.
|
|||
5. In your terminal or editor, create a `write.js` file.
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```bash
|
||||
touch write.js
|
||||
```
|
||||
|
|
@ -1146,9 +1151,9 @@ the failure message.
|
|||
|
||||
9. In your terminal, execute `index.js` to write to {{% product-name %}}:
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
node index.js
|
||||
```
|
||||
|
||||
|
|
@ -1174,7 +1179,7 @@ the failure message.
|
|||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
dotnet new console --name influxdb_csharp_client
|
||||
```
|
||||
|
||||
|
|
@ -1182,7 +1187,7 @@ the failure message.
|
|||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
cd influxdb_csharp_client
|
||||
```
|
||||
|
||||
|
|
@ -1191,7 +1196,7 @@ the failure message.
|
|||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
dotnet add package InfluxDB3.Client
|
||||
```
|
||||
|
||||
|
|
@ -1337,7 +1342,7 @@ the failure message.
|
|||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
dotnet run
|
||||
```
|
||||
|
||||
|
|
@ -1360,6 +1365,7 @@ _The tutorial assumes using Maven version 3.9 and Java version >= 15._
|
|||
[Maven](https://maven.apache.org/download.cgi) for your system.
|
||||
2. In your terminal or editor, use Maven to generate a project--for example:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
```bash
|
||||
mvn org.apache.maven.plugins:maven-archetype-plugin:3.1.2:generate \
|
||||
-DarchetypeArtifactId="maven-archetype-quickstart" \
|
||||
|
|
@ -1401,7 +1407,6 @@ _The tutorial assumes using Maven version 3.9 and Java version >= 15._
|
|||
enter the following in your terminal:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
mvn validate
|
||||
```
|
||||
|
|
@ -1562,7 +1567,6 @@ _The tutorial assumes using Maven version 3.9 and Java version >= 15._
|
|||
the project code--for example:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
mvn compile
|
||||
```
|
||||
|
|
@ -1571,8 +1575,7 @@ _The tutorial assumes using Maven version 3.9 and Java version >= 15._
|
|||
example, using Maven:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
```bash
|
||||
mvn exec:java -Dexec.mainClass="com.influxdbv3.App"
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -60,7 +60,7 @@ The simplest way to do this is to directly modify the line protocol exported in
|
|||
|
||||
For example, the following line protocol includes both a tag and field named `temp`.
|
||||
|
||||
```
|
||||
```text
|
||||
home,room=Kitchen,temp=F co=0i,hum=56.6,temp=71.0 1672531200000000000
|
||||
```
|
||||
|
||||
|
|
@ -143,13 +143,13 @@ the [exported line protocol](#migrate-data-step-1) to group certain fields into
|
|||
unique measurements.
|
||||
For example:
|
||||
|
||||
```
|
||||
```text
|
||||
example-measurement field1=0,field2=0,field3=0,field4=0,field5=0,field6=0,field7=0,field8=0 1672531200000000000
|
||||
```
|
||||
|
||||
Would become:
|
||||
|
||||
```
|
||||
```text
|
||||
new-measurement-1 field1=0,field2=0,field3=0,field4=0 1672531200000000000
|
||||
new-measurement-2 field5=0,field6=0,field7=0,field8=0 1672531200000000000
|
||||
```
|
||||
|
|
@ -209,6 +209,9 @@ databases.
|
|||
{{% /note %}}
|
||||
|
||||
##### Export all data in a database and retention policy to a file
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -221,6 +224,8 @@ databases.
|
|||
{{< expand-wrapper >}}
|
||||
{{% expand "Export all data to a file" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -231,6 +236,8 @@ influx_inspect export \
|
|||
|
||||
{{% expand "Export all data to a compressed file" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -242,6 +249,8 @@ influx_inspect export \
|
|||
|
||||
{{% expand "Export data within time bounds to a file" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -254,6 +263,8 @@ influx_inspect export \
|
|||
|
||||
{{% expand "Export a database and all its retention policies to a file" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -265,6 +276,8 @@ influx_inspect export \
|
|||
|
||||
{{% expand "Export a specific database and retention policy to a file" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -277,6 +290,8 @@ influx_inspect export \
|
|||
|
||||
{{% expand "Export all data from _non-default_ `data` and `wal` directories" %}}
|
||||
|
||||
<!--pytest.mark.xfail-->
|
||||
|
||||
```sh
|
||||
influx_inspect export \
|
||||
-lponly \
|
||||
|
|
@ -329,6 +344,9 @@ You would create the following InfluxDB {{< current-version >}} databases:
|
|||
(default is infinite)
|
||||
- Database name _(see [Database naming restrictions](#database-naming-restrictions))_
|
||||
|
||||
<!--Skip tests for dataase create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create --retention-period 30d <DATABASE_NAME>
|
||||
```
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ list_code_example: |
|
|||
|
||||
func Query() error {
|
||||
client, err := influxdb3.New(influxdb3.ClientConfig{
|
||||
Host: "https://cluster-id.influxdb.io",
|
||||
Host: "https://cluster-id.a.influxdb.io",
|
||||
Token: "DATABASE_TOKEN",
|
||||
Database: "DATABASE_NAME",
|
||||
})
|
||||
|
|
|
|||
|
|
@ -25,20 +25,29 @@ following clauses:
|
|||
|
||||
{{< req type="key" >}}
|
||||
|
||||
- {{< req "\*">}} `SELECT`: Specify fields, tags, and calculations to return from a
|
||||
measurement or use the wildcard alias (`*`) to select all fields and tags
|
||||
from a measurement. It requires at least one
|
||||
[field key](/influxdb/cloud-dedicated/reference/glossary/#field-key) or the wildcard alias (`*`).
|
||||
For more information, see [Notable SELECT statement behaviors](/influxdb/cloud-dedicated/reference/influxql/select/#notable-select-statement-behaviors).
|
||||
- {{< req "\*">}} `FROM`: Specify the [measurement](/influxdb/cloud-dedicated/reference/glossary/#measurement) to query from.
|
||||
It requires one or more comma-delimited [measurement expressions](/influxdb/cloud-dedicated/reference/influxql/select/#measurement_expression).
|
||||
- {{< req "\*">}} `SELECT`: Specify fields, tags, and calculations to return
|
||||
from a [table](/influxdb/cloud-dedicated/reference/glossary/#table) or use the
|
||||
wildcard alias (`*`) to select all fields and tags from a table. It requires
|
||||
at least one
|
||||
[field key](/influxdb/cloud-dedicated/reference/glossary/#field-key) or the
|
||||
wildcard alias (`*`). For more information, see
|
||||
[Notable SELECT statement behaviors](/influxdb/cloud-dedicated/reference/influxql/select/#notable-select-statement-behaviors).
|
||||
- {{< req "\*">}} `FROM`: Specify the
|
||||
[table](/influxdb/cloud-dedicated/reference/glossary/#table) to query from.
|
||||
<!-- vale InfluxDataDocs.v3Schema = NO -->
|
||||
It requires one or more comma-delimited
|
||||
[measurement expressions](/influxdb/cloud-dedicated/reference/influxql/select/#measurement_expression).
|
||||
<!-- vale InfluxDataDocs.v3Schema = YES -->
|
||||
- `WHERE`: Filter data based on
|
||||
[field values](/influxdb/cloud-dedicated/reference/glossary/#field),
|
||||
[tag values](/influxdb/cloud-dedicated/reference/glossary/#tag), or
|
||||
[timestamps](/influxdb/cloud-dedicated/reference/glossary/#timestamp). Only return data that meets the specified conditions--for example, falls within
|
||||
a time range, contains specific tag values, or contains a field value outside a specified range.
|
||||
[field values](/influxdb/cloud-dedicated/reference/glossary/#field),
|
||||
[tag values](/influxdb/cloud-dedicated/reference/glossary/#tag), or
|
||||
[timestamps](/influxdb/cloud-dedicated/reference/glossary/#timestamp). Only
|
||||
return data that meets the specified conditions--for example, falls within a
|
||||
time range, contains specific tag values, or contains a field value outside a
|
||||
specified range.
|
||||
|
||||
{{% influxdb/custom-timestamps %}}
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
temp,
|
||||
|
|
@ -49,21 +58,28 @@ WHERE
|
|||
time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T20:00:00Z'
|
||||
```
|
||||
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
||||
## Result set
|
||||
|
||||
If at least one row satisfies the query, {{% product-name %}} returns row data in the query result set.
|
||||
If a query uses a `GROUP BY` clause, the result set includes the following:
|
||||
If at least one row satisfies the query, {{% product-name %}} returns row data
|
||||
in the query result set.
|
||||
If a query uses a `GROUP BY` clause, the result set
|
||||
includes the following:
|
||||
|
||||
- Columns listed in the query's `SELECT` clause
|
||||
- A `time` column that contains the timestamp for the record or the group
|
||||
- An `iox::measurement` column that contains the record's measurement (table) name
|
||||
- Columns listed in the query's `GROUP BY` clause; each row in the result set contains the values used for grouping
|
||||
- An `iox::measurement` column that contains the record's
|
||||
[table](/influxdb/cloud-dedicated/reference/glossary/#table) name
|
||||
- Columns listed in the query's `GROUP BY` clause; each row in the result set
|
||||
contains the values used for grouping
|
||||
|
||||
### GROUP BY result columns
|
||||
|
||||
If a query uses `GROUP BY` and the `WHERE` clause doesn't filter by time, then groups are based on the [default time range](/influxdb/cloud-dedicated/reference/influxql/group-by/#default-time-range).
|
||||
If a query uses `GROUP BY` and the `WHERE` clause doesn't filter by time, then
|
||||
groups are based on the
|
||||
[default time range](/influxdb/cloud-dedicated/reference/influxql/group-by/#default-time-range).
|
||||
|
||||
## Basic query examples
|
||||
|
||||
|
|
@ -75,9 +91,10 @@ If a query uses `GROUP BY` and the `WHERE` clause doesn't filter by time, then g
|
|||
- [Alias queried fields and tags](#alias-queried-fields-and-tags)
|
||||
|
||||
{{% note %}}
|
||||
|
||||
#### Sample data
|
||||
|
||||
The following examples use the
|
||||
The following examples use the
|
||||
[Get started home sensor data](/influxdb/cloud-dedicated/reference/sample-data/#get-started-home-sensor-data).
|
||||
To run the example queries and return results,
|
||||
[write the sample data](/influxdb/cloud-dedicated/reference/sample-data/#write-the-home-sensor-data-to-influxdb)
|
||||
|
|
@ -89,12 +106,14 @@ to your {{% product-name %}} database before running the example queries.
|
|||
- Use the `SELECT` clause to specify what tags and fields to return.
|
||||
Specify at least one field key.
|
||||
To return all tags and fields, use the wildcard alias (`*`).
|
||||
- Specify the measurement to query in the `FROM` clause.
|
||||
- Specify time boundaries in the `WHERE` clause.
|
||||
Include time-based predicates that compare the value of the `time` column to a timestamp.
|
||||
- Specify the [table](/influxdb/cloud-dedicated/reference/glossary/#table) to
|
||||
query in the `FROM` clause.
|
||||
- Specify time boundaries in the `WHERE` clause. Include time-based predicates
|
||||
that compare the value of the `time` column to a timestamp.
|
||||
Use the `AND` logical operator to chain multiple predicates together.
|
||||
|
||||
{{% influxdb/custom-timestamps %}}
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM home
|
||||
|
|
@ -102,13 +121,13 @@ WHERE
|
|||
time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T12:00:00Z'
|
||||
```
|
||||
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
||||
Query time boundaries can be relative or absolute.
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "Query with relative time boundaries" %}}
|
||||
|
||||
To query data from relative time boundaries, compare the value of the `time`
|
||||
column to a timestamp calculated by subtracting an interval from a timestamp.
|
||||
Use `now()` to return the timestamp for the current time (UTC).
|
||||
|
|
@ -119,7 +138,7 @@ Use `now()` to return the timestamp for the current time (UTC).
|
|||
SELECT * FROM home WHERE time >= now() - 30d
|
||||
```
|
||||
|
||||
##### Query one day of data data from a week ago
|
||||
##### Query one day of data from a week ago
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
|
|
@ -128,16 +147,18 @@ WHERE
|
|||
time >= now() - 7d
|
||||
AND time <= now() - 6d
|
||||
```
|
||||
|
||||
{{% /expand %}}
|
||||
|
||||
{{% expand "Query with absolute time boundaries" %}}
|
||||
|
||||
To query data from absolute time boundaries, compare the value of the `time` column
|
||||
to a timestamp literal.
|
||||
Use the `AND` logical operator to chain together multiple predicates and define
|
||||
both start and stop boundaries for the query.
|
||||
To query data from absolute time boundaries, compare the value of the `time`
|
||||
column to a timestamp literal.
|
||||
Use the `AND` logical operator to chain together
|
||||
multiple predicates and define both start and stop boundaries for the query.
|
||||
|
||||
{{% influxdb/custom-timestamps %}}
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
*
|
||||
|
|
@ -147,6 +168,7 @@ WHERE
|
|||
time >= '2022-01-01T08:00:00Z'
|
||||
AND time <= '2022-01-01T20:00:00Z'
|
||||
```
|
||||
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
||||
{{% /expand %}}
|
||||
|
|
@ -156,8 +178,8 @@ WHERE
|
|||
|
||||
To query data without time boundaries, do not include any time-based predicates
|
||||
in your `WHERE` clause.
|
||||
If a time range is not defined in the `WHERE` clause, the default time range is
|
||||
the Unix epoch (`1970-01-01T00:00:00Z`) to _now_.
|
||||
If a time range is not defined in the `WHERE` clause,
|
||||
the default time range is the Unix epoch (`1970-01-01T00:00:00Z`) to _now_.
|
||||
|
||||
{{% warn %}}
|
||||
Querying data _without time bounds_ can return an unexpected amount of data.
|
||||
|
|
@ -172,8 +194,8 @@ SELECT * FROM home
|
|||
|
||||
To query specific fields, include them in the `SELECT` clause.
|
||||
If querying multiple fields or tags, comma-delimit each.
|
||||
If a field or tag key includes special characters or spaces or is case-sensitive,
|
||||
wrap the key in _double-quotes_.
|
||||
If a field or tag key includes special characters or spaces or is
|
||||
case-sensitive, wrap the key in _double-quotes_.
|
||||
|
||||
```sql
|
||||
SELECT time, room, temp, hum FROM home
|
||||
|
|
@ -181,10 +203,12 @@ SELECT time, room, temp, hum FROM home
|
|||
|
||||
### Query fields based on tag values
|
||||
|
||||
- In the `SELECT` clause, include fields you want to query and tags you want to base conditions on.
|
||||
- In the `WHERE` clause, include predicates that compare the tag identifier to a string literal.
|
||||
Use [logical operators](/influxdb/cloud-dedicated/reference/influxql/where/#logical-operators) to chain multiple predicates together and apply
|
||||
multiple conditions.
|
||||
- In the `SELECT` clause, include fields you want to query and tags you want to
|
||||
base conditions on.
|
||||
- In the `WHERE` clause, include predicates that compare the tag identifier to a
|
||||
string literal. Use
|
||||
[logical operators](/influxdb/cloud-dedicated/reference/influxql/where/#logical-operators)
|
||||
to chain multiple predicates together and apply multiple conditions.
|
||||
|
||||
```sql
|
||||
SELECT * FROM home WHERE room = 'Kitchen'
|
||||
|
|
@ -193,9 +217,12 @@ SELECT * FROM home WHERE room = 'Kitchen'
|
|||
### Query points based on field values
|
||||
|
||||
- In the `SELECT` clause, include fields you want to query.
|
||||
- In the `WHERE` clause, include predicates that compare the field identifier to a value or expression.
|
||||
Use [logical operators](/influxdb/cloud-dedicated/reference/influxql/where/#logical-operators) (`AND`, `OR`) to chain multiple predicates together
|
||||
and apply multiple conditions.
|
||||
- In the `WHERE` clause, include predicates that compare the field identifier to
|
||||
a value or expression.
|
||||
Use
|
||||
[logical operators](/influxdb/cloud-dedicated/reference/influxql/where/#logical-operators)
|
||||
(`AND`, `OR`) to chain multiple predicates together and apply multiple
|
||||
conditions.
|
||||
|
||||
```sql
|
||||
SELECT co, time FROM home WHERE co >= 10 OR co <= -10
|
||||
|
|
@ -204,13 +231,17 @@ SELECT co, time FROM home WHERE co >= 10 OR co <= -10
|
|||
### Alias queried fields and tags
|
||||
|
||||
To alias or rename fields and tags that you query, use the `AS` clause.
|
||||
After the tag, field, or expression you want to alias, pass `AS` followed by the alias name as an identifier (wrap in double quotes (`"`) if the alias includes spaces or special characters)--for example:
|
||||
After the tag, field, or expression you want to alias, pass `AS` followed by the
|
||||
alias name as an identifier (wrap in double quotes (`"`) if the alias includes
|
||||
spaces or special characters)--for example:
|
||||
|
||||
```sql
|
||||
SELECT temp AS temperature, hum AS "humidity (%)" FROM home
|
||||
```
|
||||
|
||||
{{% note %}}
|
||||
When aliasing columns in **InfluxQL**, use the `AS` clause and an [identifier](/influxdb/cloud-dedicated/reference/influxql/#identifiers).
|
||||
When [aliasing columns in **SQL**](/influxdb/cloud-dedicated/query-data/sql/basic-query/#alias-queried-fields-and-tags), you can use the `AS` clause to define the alias, but it isn't necessary.
|
||||
When aliasing columns in **InfluxQL**, use the `AS` clause and an
|
||||
[identifier](/influxdb/cloud-dedicated/reference/influxql/#identifiers). When
|
||||
[aliasing columns in **SQL**](/influxdb/cloud-dedicated/query-data/sql/basic-query/#alias-queried-fields-and-tags),
|
||||
you can use the `AS` clause to define the alias, but it isn't necessary.
|
||||
{{% /note %}}
|
||||
|
|
|
|||
|
|
@ -28,6 +28,13 @@ If a query doesn't return any data, it might be due to the following:
|
|||
- Your data falls outside the time range (or other conditions) in the query--for example, the InfluxQL `SHOW TAG VALUES` command uses a default time range of 1 day.
|
||||
- The query (InfluxDB server) timed out.
|
||||
- The query client timed out.
|
||||
- The query return type is not supported by the client library.
|
||||
For example, array or list types may not be supported.
|
||||
In this case, use `array_to_string()` to convert the array value to a string--for example:
|
||||
|
||||
```sql
|
||||
SELECT array_to_string(array_agg([1, 2, 3]), ', ')
|
||||
```
|
||||
|
||||
If a query times out or returns an error, it might be due to the following:
|
||||
|
||||
|
|
|
|||
|
|
@ -65,12 +65,29 @@ Be sure to follow [partitioning best practices](/influxdb/cloud-dedicated/admin/
|
|||
|
||||
If defining a custom partition template for your database with any of the
|
||||
`--template-*` flags, always include the `--template-timeformat` flag with a
|
||||
time format to use in your partition template. Otherwise time will be omitted
|
||||
from the partition template and partitions won't be able to be compacted.
|
||||
time format to use in your partition template.
|
||||
Otherwise, InfluxDB omits time from the partition template and won't compact partitions.
|
||||
{{% /note %}}
|
||||
|
||||
{{% warn %}}
|
||||
#### Cannot reuse deleted database names
|
||||
|
||||
You cannot reuse the name of a deleted database when creating a new database.
|
||||
If you try to reuse the name, the API response status code
|
||||
is `400` and the `message` field contains the following:
|
||||
|
||||
```text
|
||||
'iox_proxy.app.CreateDatabase failed to create database: \
|
||||
rpc error: code = AlreadyExists desc = A namespace with the
|
||||
name `<DATABASE_NAME>` already exists'
|
||||
```
|
||||
{{% /warn %}}
|
||||
|
||||
## Usage
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create [flags] <DATABASE_NAME>
|
||||
```
|
||||
|
|
@ -85,12 +102,12 @@ influxctl database create [flags] <DATABASE_NAME>
|
|||
|
||||
| Flag | | Description |
|
||||
| :--- | :---------------------- | :--------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| | `--retention-period` | Database retention period (default is 0s or infinite) |
|
||||
| | `--max-tables` | Maximum tables per database (default is 500, 0 uses default) |
|
||||
| | `--max-columns` | Maximum columns per table (default is 250, 0 uses default) |
|
||||
| | `--retention-period` | Database retention period (default is `0s`, infinite) |
|
||||
| | `--max-tables` | Maximum tables per database (default is 500, `0` uses default) |
|
||||
| | `--max-columns` | Maximum columns per table (default is 250, `0` uses default) |
|
||||
| | `--template-tag` | Tag to add to partition template (can include multiple of this flag) |
|
||||
| | `--template-tag-bucket` | Tag and number of buckets to partition tag values into separated by a comma--for example: `tag1,100` (can include multiple of this flag) |
|
||||
| | `--template-timeformat` | Timestamp format for partition template <!--(default is `%Y-%m-%d`) --> |
|
||||
| | `--template-timeformat` | Timestamp format for partition template (default is `%Y-%m-%d`) |
|
||||
| `-h` | `--help` | Output command help |
|
||||
|
||||
{{% caption %}}
|
||||
|
|
@ -106,12 +123,18 @@ _Also see [`influxctl` global flags](/influxdb/cloud-dedicated/reference/cli/inf
|
|||
|
||||
### Create a database with an infinite retention period
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create mydb
|
||||
```
|
||||
|
||||
### Create a database with a 30-day retention period
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--retention-period 30d \
|
||||
|
|
@ -120,6 +143,9 @@ influxctl database create \
|
|||
|
||||
### Create a database with non-default table and column limits
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--max-tables 200 \
|
||||
|
|
@ -133,6 +159,9 @@ The following example creates a new `mydb` database and applies a partition
|
|||
template that partitions by two tags (`room` and `sensor-type`) and by week using
|
||||
the time format `%Y wk:%W`:
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--template-tag room \
|
||||
|
|
|
|||
|
|
@ -14,6 +14,9 @@ Cloud Dedicated cluster.
|
|||
|
||||
## Usage
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database delete [command options] [--force] <DATABASE_NAME> [<DATABASE_NAME_N>...]
|
||||
```
|
||||
|
|
@ -50,12 +53,18 @@ _Also see [`influxctl` global flags](/influxdb/cloud-dedicated/reference/cli/inf
|
|||
|
||||
##### Delete a database named "mydb"
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database delete mydb
|
||||
```
|
||||
|
||||
##### Delete multiple databases
|
||||
|
||||
<!--Skip tests for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database delete mydb1 mydb2
|
||||
```
|
||||
|
|
|
|||
|
|
@ -36,6 +36,7 @@ list_code_example: |
|
|||
FlightInfo flightInfo = sqlClient.execute(query, auth);
|
||||
}
|
||||
}
|
||||
```
|
||||
---
|
||||
|
||||
[Apache Arrow Flight SQL for Java](https://arrow.apache.org/docs/java/reference/org/apache/arrow/flight/sql/package-summary.html) integrates with Java applications to query and retrieve data from Flight database servers using RPC and SQL.
|
||||
|
|
@ -483,10 +484,12 @@ Follow these steps to build and run the application using Docker:
|
|||
- **`HOST`**: your {{% product-name %}} hostname (URL without the "https://")
|
||||
- **`TOKEN`**: your [{{% product-name %}} database token](/influxdb/cloud-dedicated/get-started/setup/) with _read_ permission to the database
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
docker build \
|
||||
--build-arg DATABASE_NAME=INFLUX_DATABASE \
|
||||
--build-arg HOST=cluster-id.influxdb.io \
|
||||
--build-arg HOST={{% influxdb/host %}}\
|
||||
--build-arg TOKEN=INFLUX_TOKEN \
|
||||
-t javaflight .
|
||||
```
|
||||
|
|
@ -495,6 +498,8 @@ Follow these steps to build and run the application using Docker:
|
|||
|
||||
4. To run the application in a new Docker container, enter the following command:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
docker run javaflight
|
||||
```
|
||||
|
|
|
|||
|
|
@ -3,7 +3,6 @@ title: Java client library for InfluxDB v3
|
|||
list_title: Java
|
||||
description: >
|
||||
The InfluxDB v3 `influxdb3-java` Java client library integrates with application code to write and query data stored in an InfluxDB Cloud Dedicated database.
|
||||
external_url: https://github.com/InfluxCommunity/influxdb3-java
|
||||
menu:
|
||||
influxdb_cloud_dedicated:
|
||||
name: Java
|
||||
|
|
@ -13,9 +12,350 @@ influxdb/cloud-dedicated/tags: [Flight client, Java, gRPC, SQL, Flight SQL, clie
|
|||
weight: 201
|
||||
---
|
||||
|
||||
The InfluxDB v3 [`influxdb3-java` Java client library](https://github.com/InfluxCommunity/influxdb3-java) integrates with Java application code
|
||||
to write and query data stored in an {{% product-name %}} database.
|
||||
The InfluxDB v3 [`influxdb3-java` Java client library](https://github.com/InfluxCommunity/influxdb3-java) integrates
|
||||
with Java application code to write and query data stored in {{% product-name %}}.
|
||||
|
||||
The documentation for this client library is available on GitHub.
|
||||
InfluxDB client libraries provide configurable batch writing of data to {{% product-name %}}.
|
||||
Use client libraries to construct line protocol data, transform data from other formats
|
||||
to line protocol, and batch write line protocol data to InfluxDB HTTP APIs.
|
||||
|
||||
<a href="https://github.com/InfluxCommunity/influxdb3-java" target="_blank" class="btn github">InfluxDB v3 Java client library</a>
|
||||
InfluxDB v3 client libraries can query {{% product-name %}} using SQL or InfluxQL.
|
||||
The `influxdb3-java` Java client library wraps the Apache Arrow `org.apache.arrow.flight.FlightClient`
|
||||
in a convenient InfluxDB v3 interface for executing SQL and InfluxQL queries, requesting
|
||||
server metadata, and retrieving data from {{% product-name %}} using the Flight protocol with gRPC.
|
||||
|
||||
- [Installation](#installation)
|
||||
- [Using Maven](#using-maven)
|
||||
- [Using Gradle](#using-gradle)
|
||||
- [Importing the client](#importing-the-client)
|
||||
- [API reference](#api-reference)
|
||||
- [Classes](#classes)
|
||||
- [InfluxDBClient interface](#influxdbclient-interface)
|
||||
- [Initialize with credential parameters](#initialize-with-credential-parameters)
|
||||
- [InfluxDBClient instance methods](#influxdbclient-instance-methods)
|
||||
- [InfluxDBClient.writePoint](#influxdbclientwritepoint)
|
||||
- [InfluxDBClient.query](#influxdbclientquery)
|
||||
|
||||
|
||||
#### Example: write and query data
|
||||
|
||||
The following example shows how to use `influxdb3-java` to write and query data stored in {{% product-name %}}.
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | DATABASE_TOKEN" %}}
|
||||
|
||||
```java
|
||||
package com.influxdata.demo;
|
||||
|
||||
import com.influxdb.v3.client.InfluxDBClient;
|
||||
import com.influxdb.v3.client.Point;
|
||||
import com.influxdb.v3.client.query.QueryOptions;
|
||||
import com.influxdb.v3.client.query.QueryType;
|
||||
|
||||
import java.time.Instant;
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class HelloInfluxDB {
|
||||
private static final String HOST_URL = "https://{{< influxdb/host >}}"; // your cluster URL
|
||||
private static final String DATABASE = "DATABASE_NAME"; // your InfluxDB database name
|
||||
private static final char[] TOKEN = System.getenv("DATABASE_TOKEN"); // a local environment variable that stores your database token
|
||||
|
||||
// Create a client instance that writes and queries data in your database.
|
||||
public static void main(String[] args) {
|
||||
// Instantiate the client with your InfluxDB credentials
|
||||
try (InfluxDBClient client = InfluxDBClient.getInstance(HOST_URL, TOKEN, DATABASE)) {
|
||||
writeData(client);
|
||||
queryData(client);
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("An error occurred while connecting to InfluxDB!");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
// Use the Point class to construct time series data.
|
||||
private static void writeData(InfluxDBClient client) {
|
||||
Point point = Point.measurement("temperature")
|
||||
.setTag("location", "London")
|
||||
.setField("value", 30.01)
|
||||
.setTimestamp(Instant.now().minusSeconds(10));
|
||||
try {
|
||||
client.writePoint(point);
|
||||
System.out.println("Data is written to the database.");
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to write data to the database.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
// Use SQL to query the most recent 10 measurements
|
||||
private static void queryData(InfluxDBClient client) {
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
System.out.printf("| %-8s | %-8s | %-30s |%n", "location", "value", "time");
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
|
||||
String sql = "select time,location,value from temperature order by time desc limit 10";
|
||||
try (Stream<Object[]> stream = client.query(sql)) {
|
||||
stream.forEach(row -> System.out.printf("| %-8s | %-8s | %-30s |%n", row[1], row[2], row[0]));
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to query data from the database.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{% cite %}}Source: [suyashcjoshi/SimpleJavaInfluxDB](https://github.com/suyashcjoshi/SimpleJavaInfluxDB/) on GitHub{{% /cite %}}
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
the name of your {{% product-name %}}
|
||||
[database](/influxdb/cloud-dedicated/admin/databases/) to read and write data to
|
||||
- {{% code-placeholder-key %}}`DATABASE_TOKEN`{{% /code-placeholder-key %}}: a
|
||||
local environment variable that stores your
|
||||
[token](/influxdb/cloud-dedicated/admin/tokens/database/)--the token must have
|
||||
read and write permissions on the specified database.
|
||||
|
||||
### Run the example to write and query data
|
||||
|
||||
1. Build an executable JAR for the project--for example, using Maven:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
mvn package
|
||||
```
|
||||
|
||||
2. In your terminal, run the `java` command to write and query data in your database:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
java \
|
||||
--add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED \
|
||||
-jar target/PROJECT_NAME.jar
|
||||
```
|
||||
|
||||
Include the following in your command:
|
||||
|
||||
- [`--add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED`](https://arrow.apache.org/docs/java/install.html#id3): with Java version 9 or later and Apache Arrow version 16 or later, exposes JDK internals for Arrow.
|
||||
For more options, see the [Apache Arrow Java install documentation](https://arrow.apache.org/docs/java/install.html).
|
||||
- `-jar target/PROJECT_NAME.jar`: your `.jar` file to run.
|
||||
|
||||
The output is the newly written data from your {{< product-name >}} database.
|
||||
|
||||
## Installation
|
||||
|
||||
Include `com.influxdb.influxdb3-java` in your project dependencies.
|
||||
|
||||
{{< code-tabs-wrapper >}}
|
||||
{{% code-tabs %}}
|
||||
[Maven pom.xml](#)
|
||||
[Gradle dependency script](#)
|
||||
{{% /code-tabs %}}
|
||||
{{% code-tab-content %}}
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.influxdb</groupId>
|
||||
<artifactId>influxdb3-java</artifactId>
|
||||
<version>RELEASE</version>
|
||||
</dependency>
|
||||
```
|
||||
{{% /code-tab-content %}}
|
||||
{{% code-tab-content %}}
|
||||
<!--pytest.mark.skip-->
|
||||
```groovy
|
||||
dependencies {
|
||||
|
||||
implementation group: 'com.influxdb', name: 'influxdb3-java', version: 'latest.release'
|
||||
|
||||
}
|
||||
```
|
||||
{{% /code-tab-content %}}
|
||||
{{< /code-tabs-wrapper >}}
|
||||
|
||||
## Importing the client
|
||||
|
||||
The `influxdb3-java` client library package provides
|
||||
`com.influxdb.v3.client` classes for constructing, writing, and querying data
|
||||
stored in {{< product-name >}}.
|
||||
|
||||
## API reference
|
||||
|
||||
- [Interface InfluxDBClient](#interface-influxdbclient)
|
||||
- [Initialize with credential parameters](#initialize-with-credential-parameters)
|
||||
- [InfluxDBClient instance methods](#influxdbclient-instance-methods)
|
||||
- [InfluxDBClient.writePoint](#influxdbclientwritepoint)
|
||||
- [InfluxDBClient.query](#influxdbclientquery)
|
||||
|
||||
|
||||
## InfluxDBClient interface
|
||||
|
||||
`InfluxDBClient` provides an interface for interacting with InfluxDB APIs for writing and querying data.
|
||||
|
||||
The `InfluxDBClient.getInstance` constructor initializes and returns a client instance with the following:
|
||||
|
||||
- A _write client_ configured for writing to the database.
|
||||
- An Arrow _Flight client_ configured for querying the database.
|
||||
|
||||
To initialize a client, call `getInstance` and pass your credentials as one of
|
||||
the following types:
|
||||
|
||||
- [parameters](#initialize-with-credential-parameters)
|
||||
- a [`ClientConfig`](https://github.com/InfluxCommunity/influxdb3-java/blob/main/src/main/java/com/influxdb/v3/client/config/ClientConfig.java)
|
||||
- a [database connection string](#initialize-using-a-database-connection-string)
|
||||
|
||||
### Initialize with credential parameters
|
||||
|
||||
{{% code-placeholders "host | database | token" %}}
|
||||
|
||||
```java
|
||||
static InfluxDBClient getInstance(@Nonnull final String host,
|
||||
@Nullable final char[] token,
|
||||
@Nullable final String database)
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
- {{% code-placeholder-key %}}`host`{{% /code-placeholder-key %}} (string): The host URL of the InfluxDB instance.
|
||||
- {{% code-placeholder-key %}}`database`{{% /code-placeholder-key %}} (string): The [database](/influxdb/cloud-dedicated/admin/databases/) to use for writing and querying.
|
||||
- {{% code-placeholder-key %}}`token`{{% /code-placeholder-key %}} (char array): A [database token](/influxdb/cloud-dedicated/admin/tokens/database/) with read/write permissions.
|
||||
|
||||
#### Example: initialize with credential parameters
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | DATABASE_TOKEN" %}}
|
||||
|
||||
```java
|
||||
package com.influxdata.demo;
|
||||
|
||||
import com.influxdb.v3.client.InfluxDBClient;
|
||||
import com.influxdb.v3.client.Point;
|
||||
import com.influxdb.v3.client.query.QueryOptions;
|
||||
import com.influxdb.v3.client.query.QueryType;
|
||||
|
||||
import java.time.Instant;
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class HelloInfluxDB {
|
||||
private static final String HOST_URL = "https://{{< influxdb/host >}}";
|
||||
private static final String DATABASE = "DATABASE_NAME";
|
||||
private static final char[] TOKEN = System.getenv("DATABASE_TOKEN");
|
||||
|
||||
// Create a client instance, and then write and query data in InfluxDB.
|
||||
public static void main(String[] args) {
|
||||
try (InfluxDBClient client = InfluxDBClient.getInstance(HOST_URL, DATABASE_TOKEN, DATABASE)) {
|
||||
writeData(client);
|
||||
queryData(client);
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("An error occurred while connecting to InfluxDB!");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
your {{% product-name %}} [database](/influxdb/cloud-dedicated/admin/databases/)
|
||||
- {{% code-placeholder-key %}}`DATABASE_TOKEN`{{% /code-placeholder-key %}}: a
|
||||
[database token](/influxdb/cloud-dedicated/admin/tokens/database/) that has
|
||||
the necessary permissions on the specified database.
|
||||
|
||||
#### Default tags
|
||||
|
||||
To include default [tags](/influxdb/cloud-dedicated/reference/glossary/#tag) in
|
||||
all written data, pass a `Map` of tag keys and values.
|
||||
|
||||
```java
|
||||
InfluxDBClient getInstance(@Nonnull final String host,
|
||||
@Nullable final char[] token,
|
||||
@Nullable final String database,
|
||||
@Nullable Map<String, String> defaultTags)
|
||||
```
|
||||
|
||||
### Initialize using a database connection string
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | API_TOKEN" %}}
|
||||
|
||||
```java
|
||||
"https://{{< influxdb/host >}}"
|
||||
+ "?token=DATABASE_TOKEN&database=DATABASE_NAME"
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
your {{% product-name %}} [database](/influxdb/cloud-dedicated/admin/databases/)
|
||||
- {{% code-placeholder-key %}}`DATABASE_TOKEN`{{% /code-placeholder-key %}}: a
|
||||
[database token](/influxdb/cloud-dedicated/admin/tokens/database/) that has
|
||||
the necessary permissions on the specified database.
|
||||
|
||||
### InfluxDBClient instance methods
|
||||
|
||||
#### InfluxDBClient.writePoint
|
||||
|
||||
To write points as line protocol to a database:
|
||||
|
||||
1. [Initialize the `client`](#initialize-with-credential-parameters)--your
|
||||
token must have write permission on the specified database.
|
||||
2. Use the `com.influxdb.v3.client.Point` class to create time series data.
|
||||
3. Call the `client.writePoint()` method to write points as line protocol in your
|
||||
database.
|
||||
|
||||
```java
|
||||
// Use the Point class to construct time series data.
|
||||
// Call client.writePoint to write the point in your database.
|
||||
private static void writeData(InfluxDBClient client) {
|
||||
Point point = Point.measurement("temperature")
|
||||
.setTag("location", "London")
|
||||
.setField("value", 30.01)
|
||||
.setTimestamp(Instant.now().minusSeconds(10));
|
||||
try {
|
||||
client.writePoint(point);
|
||||
System.out.println("Data written to the database.");
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to write data to the database.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### InfluxDBClient.query
|
||||
|
||||
To query data and process the results:
|
||||
|
||||
1. [Initialize the `client`](#initialize-with-credential-parameters)--the
|
||||
token must have read permission on the database you want to query.
|
||||
2. Call `client.query()` and provide your SQL query as a string.
|
||||
3. Use the result stream's built-in iterator to process row data.
|
||||
|
||||
```java
|
||||
// Query the latest 10 measurements using SQL
|
||||
private static void queryData(InfluxDBClient client) {
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
System.out.printf("| %-8s | %-8s | %-30s |%n", "location", "value", "time");
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
|
||||
String sql = "select time,location,value from temperature order by time desc limit 10";
|
||||
try (Stream<Object[]> stream = client.query(sql)) {
|
||||
stream.forEach(row -> System.out.printf("| %-8s | %-8s | %-30s |%n", row[1], row[2], row[0]));
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to query data from the database.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<a class="btn" href="https://github.com/InfluxCommunity/influxdb3-java/" target="\_blank">View the InfluxDB v3 Java client library</a>
|
||||
|
|
|
|||
|
|
@ -282,16 +282,16 @@ status = None
|
|||
# Define callbacks for write responses
|
||||
def success(self, data: str):
|
||||
status = "Success writing batch: data: {data}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
def error(self, data: str, err: InfluxDBError):
|
||||
status = f"Error writing batch: config: {self}, data: {data}, error: {err}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
|
||||
def retry(self, data: str, err: InfluxDBError):
|
||||
status = f"Retry error writing batch: config: {self}, data: {data}, error: {err}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
# Instantiate WriteOptions for batching
|
||||
write_options = WriteOptions()
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ InfluxData's information security program is based on industry-recognized standa
|
|||
including but not limited to ISO 27001, NIST 800-53, CIS20, and SOC2 Type II.
|
||||
The security policy describes the secure development, deployment, and operation of InfluxDB Cloud.
|
||||
|
||||
To protect data, InfluxDB Cloud Dedicated includes the following:
|
||||
To protect data, {{% product-name %}} includes the following:
|
||||
|
||||
- Guaranteed [tenant isolation](#tenant-isolation) and [data integrity](#data-integrity).
|
||||
- Trusted cloud infrastructure
|
||||
|
|
@ -48,30 +48,30 @@ To protect data, InfluxDB Cloud Dedicated includes the following:
|
|||
|
||||
## Tenant isolation
|
||||
|
||||
In the InfluxDB Cloud Dedicated platform, access controls ensure that only valid
|
||||
In the {{% product-name %}} platform, access controls ensure that only valid
|
||||
authenticated and authorized requests access your account data.
|
||||
Access control includes:
|
||||
|
||||
- A unique cluster ID assigned to each InfluxDB Cloud Dedicated cluster.
|
||||
- A unique cluster ID assigned to each {{% product-name %}} cluster.
|
||||
All internal Cloud services require this cluster ID to authenticate entities before accessing or operating on data.
|
||||
- All external requests must be authorized with a valid token or session.
|
||||
Every InfluxDB Cloud Dedicated service enforces this policy.
|
||||
Every {{% product-name %}} service enforces this policy.
|
||||
|
||||
## Data integrity
|
||||
|
||||
A dedicated internal service ensures data integrity
|
||||
by periodically creating, recording, and writing test data into test buckets.
|
||||
The service periodically executes queries to ensure the data hasn't been lost or corrupted.
|
||||
A separate instance of this service lives within each InfluxDB Cloud Dedicated cluster.
|
||||
A separate instance of this service lives within each {{% product-name %}} cluster.
|
||||
Additionally, the service creates out-of-band backups in
|
||||
[line protocol](https://docs.influxdata.com/influxdb/cloud/reference/syntax/line-protocol/),
|
||||
and ensures the backup data matches the data on disk.
|
||||
|
||||
## Cloud infrastructure
|
||||
|
||||
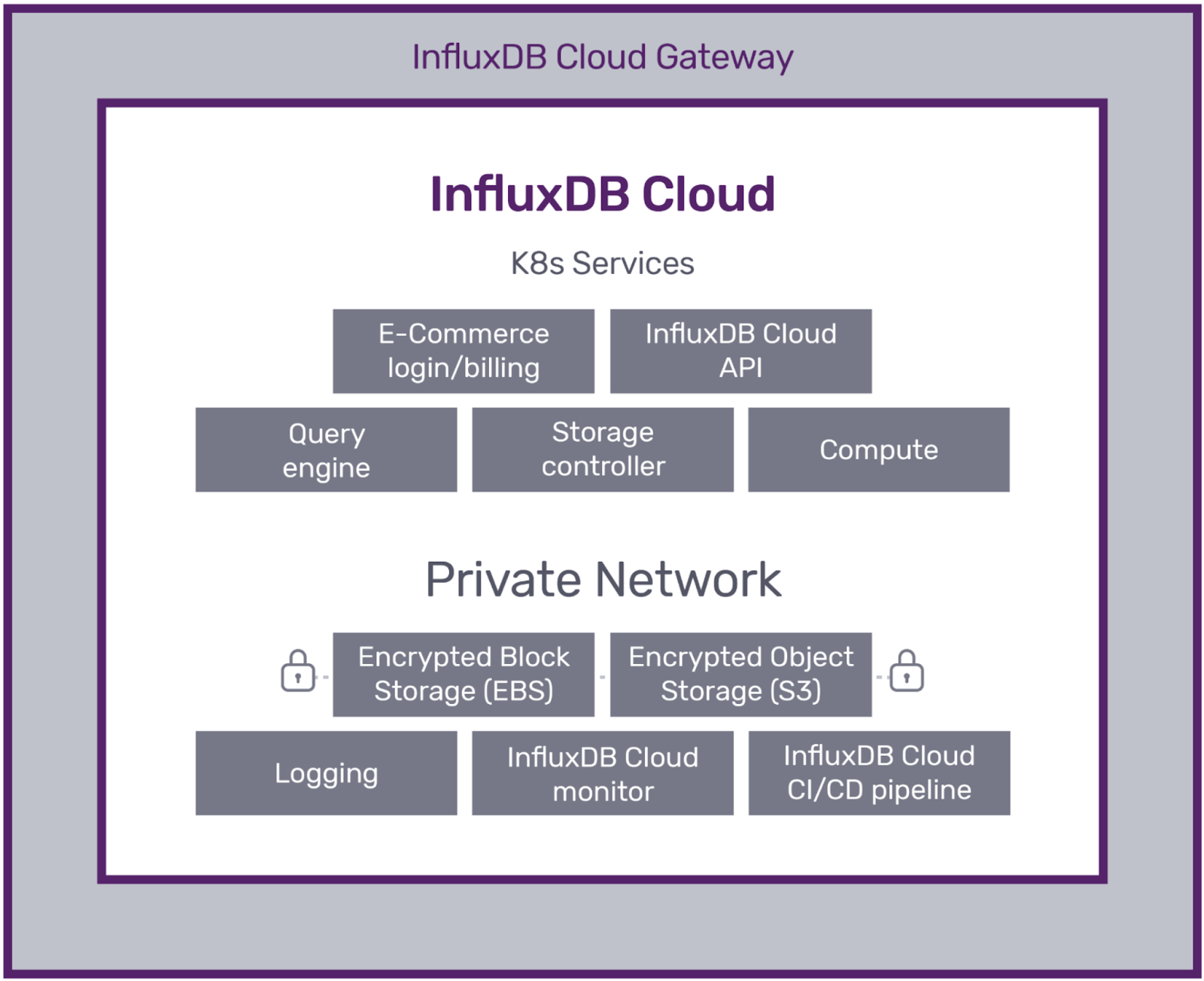
|
||||

|
||||
|
||||
InfluxDB Cloud Dedicated is available on the following cloud providers:
|
||||
{{% product-name %}} is available on the following cloud providers:
|
||||
|
||||
- [Amazon Web Services (AWS)](https://aws.amazon.com/)
|
||||
- [Microsoft Azure](https://azure.microsoft.com/en-us/) _(Coming)_
|
||||
|
|
@ -80,17 +80,17 @@ InfluxDB Cloud Dedicated is available on the following cloud providers:
|
|||
To ensure data security, availability, and durability, each instance is isolated
|
||||
and protected in its own virtual private cloud (VPC).
|
||||
|
||||
Users interact with InfluxDB Cloud Dedicated only through Cloud Dedicated established APIs.
|
||||
Users interact with {{% product-name %}} only through Cloud Dedicated established APIs.
|
||||
For cluster management activities, authorized users interact with the Granite service.
|
||||
For workload clusters, authorized users interact with APIs for InfluxDB v3 Ingesters (writes) and Queriers (reads).
|
||||
These services don't expose AWS S3 or other cloud provider or internal services.
|
||||
InfluxDB Cloud Dedicated uses separate S3 buckets for each customer's cluster to persist writes.
|
||||
{{% product-name %}} uses separate S3 buckets for each customer's cluster to persist writes.
|
||||
The S3 buckets are only accessible by the customer's cluster services.
|
||||
Separate configuration ensures one customer's S3 buckets cannot be accessed by another customer (for example, in the event of a service defect).
|
||||
|
||||
### Amazon Web Services (AWS)
|
||||
|
||||
An instance of InfluxDB Cloud Dedicated consists of microservices in Kubernetes.
|
||||
An instance of {{% product-name %}} consists of microservices in Kubernetes.
|
||||
Each VPC within AWS is segmented into public and private subnets:
|
||||
|
||||
- The public subnet contains resources exposed to the public internet, including
|
||||
|
|
@ -103,7 +103,7 @@ For detail about AWS's physical security and data center protocols, see [AWS's C
|
|||
|
||||
### Google Cloud Platform (GCP)
|
||||
|
||||
In Google Cloud Platform (GCP), InfluxDB Cloud Dedicated uses the Google Kubernetes Engine (GKE)
|
||||
In Google Cloud Platform (GCP), {{% product-name %}} uses the Google Kubernetes Engine (GKE)
|
||||
and Google Compute Engine to deploy individual cluster components.
|
||||
Clusters are isolated at the project level
|
||||
to enhance access controls and data governance, and support auditing.
|
||||
|
|
@ -113,7 +113,7 @@ For detail about physical security in GCP data centers, see [Google's Compliance
|
|||
|
||||
### Microsoft Azure
|
||||
|
||||
In Microsoft Azure, InfluxDB Cloud Dedicated uses Azure Kubernetes Service (AKS)
|
||||
In Microsoft Azure, {{% product-name %}} uses Azure Kubernetes Service (AKS)
|
||||
and Azure Virtual Machines to deploy individual cluster components.
|
||||
To support auditing and authorization control within Azure,
|
||||
clusters are deployed into dedicated VNets within each region.
|
||||
|
|
@ -123,9 +123,9 @@ For detail about physical security within Microsoft Azure data centers, see [Mic
|
|||
|
||||
### Data encryption
|
||||
|
||||
InfluxDB Cloud Dedicated enforces TLS encryption for data in transit from all
|
||||
{{% product-name %}} enforces TLS encryption for data in transit from all
|
||||
clients, including Telegraf agents, browsers, and custom applications.
|
||||
TLS 1.2 is the minimum TLS version allowed by InfluxDB Cloud Dedicated, including Granite server and management cluster TLS termination.
|
||||
TLS 1.2 is the minimum TLS version allowed by {{% product-name %}}, including Granite server and management cluster TLS termination.
|
||||
Requests using TLS 1.1 or earlier are rejected.
|
||||
|
||||
By default, data at rest is encrypted using strong encryption methods (AES-256)
|
||||
|
|
@ -145,11 +145,11 @@ InfluxData maintains the following application and service security controls:
|
|||
- Multi-factor authentication (MFA) is required for all infrastructure (AWS, GCP, and Azure)
|
||||
and for other production systems with access to user information
|
||||
(see [InfluxData Subprocessors](https://www.influxdata.com/legal/influxdata-subprocessors/)).
|
||||
- InfluxDB Cloud Dedicated access is logged and audited regularly.
|
||||
- {{% product-name %}} access is logged and audited regularly.
|
||||
|
||||
### Configuration management
|
||||
|
||||
InfluxDB Cloud Dedicated is programmatically managed and deployed using
|
||||
{{% product-name %}} is programmatically managed and deployed using
|
||||
“infrastructure as code” which undergoes version control and testing as part of
|
||||
the automated deployment process.
|
||||
Permission to push code is tightly controlled,
|
||||
|
|
@ -191,7 +191,7 @@ Dedicated environments.
|
|||
for event analysis, capacity planning, alerting, and instrumentation.
|
||||
Access to these logs and operator interfaces is controlled by group access
|
||||
permissions, and provided only to teams that require access to deliver
|
||||
InfluxDB Cloud Dedicated services.
|
||||
{{% product-name %}} services.
|
||||
|
||||
### Security assessments
|
||||
|
||||
|
|
@ -212,7 +212,7 @@ The Business Continuity Plan and Disaster Recovery Plan are updated annually.
|
|||
|
||||
### Data durability
|
||||
|
||||
Data is replicated within multiple storage engines of InfluxDB Cloud Dedicated.
|
||||
Data is replicated within multiple storage engines of {{% product-name %}}.
|
||||
The replication mechanism executes a serializable upsert and delete stream
|
||||
against all replicas and runs background entropy detection processes to identify
|
||||
diverged replicas.
|
||||
|
|
@ -233,7 +233,9 @@ Users can configure the following security controls:
|
|||
|
||||
### Access, authentication, and authorization
|
||||
|
||||
InfluxDB Cloud Dedicated uses [Auth0](https://auth0.com/) for authentication and separates workload cluster management authorizations (using _management tokens_) from database read and write authorizations (using _database tokens_).
|
||||
{{< product-name >}} uses [Auth0](https://auth0.com/) for authentication and
|
||||
separates workload cluster management authorizations (using _management tokens_)
|
||||
from database read and write authorizations (using _database tokens_).
|
||||
|
||||
- [User provisioning](#user-provisioning)
|
||||
- [Management tokens](#management-tokens)
|
||||
|
|
@ -241,23 +243,32 @@ InfluxDB Cloud Dedicated uses [Auth0](https://auth0.com/) for authentication and
|
|||
|
||||
#### User provisioning
|
||||
|
||||
InfluxData uses Auth0 to create user accounts and assign permission sets to user accounts on the InfluxDB Cloud Dedicated system.
|
||||
InfluxData uses [Auth0](https://auth0.com/) to create user accounts and assign
|
||||
permission sets to user accounts on {{% product-name %}}.
|
||||
After a user account is created, InfluxData provides the user with the following:
|
||||
|
||||
- An **Auth0 login** to authenticate access to the cluster
|
||||
- The InfluxDB Cloud Dedicated **account ID**
|
||||
- The InfluxDB Cloud Dedicated **cluster ID**
|
||||
- The InfluxDB Cloud Dedicated **cluster URL**
|
||||
- The {{% product-name %}} **account ID**
|
||||
- The {{% product-name %}} **cluster ID**
|
||||
- The {{% product-name %}} **cluster URL**
|
||||
- A password reset email for setting the login password
|
||||
|
||||
With a valid password, the user can login via InfluxData's `influxctl` command line tool.
|
||||
The login command initiates an Auth0 browser login so that the password is never exchanged with `influxctl`.
|
||||
With a successful authentication to Auth0, InfluxDB Cloud Dedicated provides the user's `influxctl` session with a short-lived [management token](#management-tokens) for access to the Granite service.
|
||||
The user interacts with the `influxctl` command line tool to manage the workload cluster, including creating [database tokens](#database-tokens) for database read and write access.
|
||||
With a valid password, the user can login by invoking one of the
|
||||
[`influxctl` commands](/influxdb/cloud-dedicated/reference/influxctl/).
|
||||
The command initiates an Auth0 browser login so that the password is never
|
||||
exchanged with `influxctl`.
|
||||
After a successful Auth0 authentication, {{% product-name %}} provides the
|
||||
user's `influxctl` session with a short-lived
|
||||
[management token](#management-tokens) for access to the Granite service.
|
||||
The user interacts with the `influxctl` command line tool to manage the workload
|
||||
cluster, including creating [database tokens](#database-tokens) for database
|
||||
read and write access and [creating long-lived management tokens](/influxdb/cloud-dedicated/admin/management-tokens/)
|
||||
for use with the [Management API](/influxdb/cloud-dedicated/api/management/).
|
||||
|
||||
#### Management tokens
|
||||
|
||||
Management tokens authenticate user accounts to the Granite service and provide authorizations for workload cluster management activities, including:
|
||||
Management tokens authenticate user accounts to the Granite service and provide
|
||||
authorizations for workload cluster management activities, including:
|
||||
|
||||
- account, pricing, and infrastructure management
|
||||
- inviting, listing, and deleting users
|
||||
|
|
@ -268,19 +279,51 @@ Management tokens consist of the following:
|
|||
|
||||
- An access token string (sensitive)
|
||||
- A permission set for management activities (configured during user provisioning)
|
||||
- A mandatory 1 hour expiration
|
||||
- A mandatory 1 hour expiration for tokens generated by logging in to `influxctl`
|
||||
|
||||
When a user issues a command using the `influxctl` command-line tool, `influxctl` sends the management token string with the request to the server, where Granite validates the token (for example, using Auth0).
|
||||
If the management token is valid and not expired, the service then compares the token's permissions against the permissions needed to complete the user's request.
|
||||
When a user issues a command using the `influxctl` command-line tool,
|
||||
`influxctl` sends the management token string with the request to the server,
|
||||
where Granite validates the token (for example, using Auth0).
|
||||
If the management token is valid and not expired, the service then compares the
|
||||
token's permissions against the permissions needed to complete the user's request.
|
||||
|
||||
Only valid unexpired tokens that have the necessary permission sets are authorized to perform management functions with InfluxDB Cloud Dedicated.
|
||||
Following security best practice, management tokens are never stored on InfluxDB Cloud Dedicated (Granite or workload cluster) servers, which prevents token theft from the server.
|
||||
On the client (the user's system), the management token is stored on disk with restricted permissions for `influxctl` to use on subsequent runs.
|
||||
For example, a user's Linux system would store the management token at `~/.cache/influxctl/*.json` with `0600` permissions (that is, owner read and write, and no access for _group_ or _other_).
|
||||
Only valid unexpired tokens that have the necessary permission sets are
|
||||
authorized to perform management functions with {{% product-name %}}.
|
||||
Following security best practice, management tokens are never stored on
|
||||
{{% product-name %}} (Granite or workload cluster) servers, which prevents token
|
||||
theft from the server.
|
||||
On the client (the user's system), the management token is stored on disk with
|
||||
restricted permissions for `influxctl` to use on subsequent runs.
|
||||
For example, a user's Linux system would store the management token at
|
||||
`~/.cache/influxctl/*.json` with `0600` permissions
|
||||
(that is, owner read and write, and no access for _group_ or _other_).
|
||||
|
||||
##### Management tokens and the Management API
|
||||
|
||||
A user associated with the cluster and authorized through OAuth may use
|
||||
`influxctl` to
|
||||
[manually create and revoke management tokens](/influxdb/cloud-dedicated/admin/tokens/management/)
|
||||
for automation use
|
||||
cases--for example, using the [Management API for
|
||||
{{% product-name %}}](/influxdb/cloud-dedicated/api/management/) to rotate
|
||||
database tokens or create tables.
|
||||
|
||||
To authenticate a Management API request, the user passes the manually created
|
||||
token in the HTTP `Authorization` header:
|
||||
|
||||
```HTTP
|
||||
Authorization MANAGEMENT_TOKEN
|
||||
```
|
||||
|
||||
A manually created management token has an optional expiration and
|
||||
doesn't require human interaction with the OAuth provider.
|
||||
|
||||
Manually created management tokens are meant for automation use cases
|
||||
and shouldn't be used to circumvent the OAuth provider.
|
||||
|
||||
#### Database tokens
|
||||
|
||||
Database tokens provide authorization for users and client applications to read and write data and metadata in an InfluxDB Cloud Dedicated database.
|
||||
Database tokens provide authorization for users and client applications to read and write data and metadata in an {{% product-name %}} database.
|
||||
All data write and query API requests require a valid database token with sufficient permissions.
|
||||
_**Note:** an all-access management token can't read or write to a database because it's not a database token._
|
||||
|
||||
|
|
@ -291,13 +334,13 @@ Database tokens consist of the following:
|
|||
- A permission set for reading from a database, writing to a database, or both
|
||||
- An API key string (sensitive, with the format apiv<N>_<base64-encoded 512-bit random string>)
|
||||
|
||||
When a user successfully creates a database token, the InfluxDB Cloud Dedicated Granite server reveals the new database token to the user as an API key string--the key string is only visible when it's created.
|
||||
When a user successfully creates a database token, the {{% product-name %}} Granite server reveals the new database token to the user as an API key string--the key string is only visible when it's created.
|
||||
The user is responsible for securely storing and managing the API key string.
|
||||
|
||||
Following security best practice, a database token's raw API key string is never stored on InfluxDB Cloud Dedicated (Granite or workload cluster) servers, which prevents token theft from the server.
|
||||
Following security best practice, a database token's raw API key string is never stored on {{% product-name %}} (Granite or workload cluster) servers, which prevents token theft from the server.
|
||||
The servers store non-sensitive database token attributes (identifier, description, and permission set) and the SHA-512 of the token API key string.
|
||||
When a user provides the API key as part of a request to the workload cluster, the cluster validates the token's SHA-512 against the stored SHA-512.
|
||||
If the database token is valid, InfluxDB Cloud Dedicated compares the token's permissions against the permissions needed to complete the user's request.
|
||||
If the database token is valid, {{% product-name %}} compares the token's permissions against the permissions needed to complete the user's request.
|
||||
The request is only authorized if it contains a valid token with the necessary permission set.
|
||||
|
||||
##### Token rotation
|
||||
|
|
@ -310,7 +353,7 @@ To rotate a token, a user deletes the database token and issues a new one.
|
|||
|
||||
InfluxDB Cloud accounts support multiple users in an organization.
|
||||
By default, each user with the *Owner* role has full permissions on resources
|
||||
in your InfluxDB Cloud Dedicated cluster.
|
||||
in your {{% product-name %}} cluster.
|
||||
|
||||
### Advanced controls
|
||||
|
||||
|
|
|
|||
|
|
@ -23,11 +23,13 @@ queries, and is optimized to reduce storage cost.
|
|||
|
||||
- [Storage engine diagram](#storage-engine-diagram)
|
||||
- [Storage engine components](#storage-engine-components)
|
||||
- [Router](#router)
|
||||
- [Ingester](#ingester)
|
||||
- [Querier](#querier)
|
||||
- [Catalog](#catalog)
|
||||
- [Object store](#object-store)
|
||||
- [Compactor](#compactor)
|
||||
- [Garbage collector](#garbage-collector)
|
||||
- [Scaling strategies](#scaling-strategies)
|
||||
- [Vertical scaling](#vertical-scaling)
|
||||
- [Horizontal scaling](#horizontal-scaling)
|
||||
|
|
@ -38,11 +40,29 @@ queries, and is optimized to reduce storage cost.
|
|||
|
||||
## Storage engine components
|
||||
|
||||
- [Router](#router)
|
||||
- [Ingester](#ingester)
|
||||
- [Querier](#querier)
|
||||
- [Catalog](#catalog)
|
||||
- [Object store](#object-store)
|
||||
- [Compactor](#compactor)
|
||||
- [Garbage collector](#garbage-collector)
|
||||
|
||||
### Router
|
||||
|
||||
The Router (also known as the Ingest Router) parses incoming line
|
||||
protocol and then routes it to [Ingesters](#ingester).
|
||||
To ensure write durability, the Router replicates data to two or more of the
|
||||
available Ingesters.
|
||||
|
||||
##### Router scaling strategies
|
||||
|
||||
The Router can be scaled both [vertically](#vertical-scaling) and
|
||||
[horizontally](#horizontal-scaling).
|
||||
Horizontal scaling increases write throughput and is typically the most
|
||||
effective scaling strategy for the Router.
|
||||
Vertical scaling (specifically increased CPU) improves the Router's ability to
|
||||
parse incoming line protocol with lower latency.
|
||||
|
||||
### Ingester
|
||||
|
||||
|
|
@ -150,6 +170,20 @@ increasing the available CPU) is the most effective scaling strategy for the Com
|
|||
Horizontal scaling increases compaction throughput, but not as efficiently as
|
||||
vertical scaling.
|
||||
|
||||
### Garbage collector
|
||||
|
||||
The Garbage collector runs background jobs that evict expired or deleted data,
|
||||
remove obsolete compaction files, and reclaim space in both the [Catalog](#catalog) and the
|
||||
[Object store](#object-store).
|
||||
|
||||
##### Garbage collector scaling strategies
|
||||
|
||||
The Garbage collector is not designed for distributed load and should _not_ be
|
||||
scaled horizontally. The Garbage collector does not perform CPU- or
|
||||
memory-intensive work, so [vertical scaling](#vertical-scaling) should only be
|
||||
considered only if you observe very high CPU usage or if the container regularly
|
||||
runs out of memory.
|
||||
|
||||
---
|
||||
|
||||
## Scaling strategies
|
||||
|
|
|
|||
|
|
@ -11,6 +11,17 @@ menu:
|
|||
weight: 202
|
||||
---
|
||||
|
||||
## v2.9.4 {date="2024-07-25"}
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Resolve crash when parsing error message and authentication was null.
|
||||
|
||||
### Dependency Updates
|
||||
|
||||
- Update `golang.org/x/mod` from 0.18.0 to 0.19.0
|
||||
- Update `google.golang.org/grpc` from 1.64.0 to 1.65.0
|
||||
|
||||
## v2.9.3 {date="2024-06-26"}
|
||||
|
||||
### Bug Fixes
|
||||
|
|
|
|||
|
|
@ -56,8 +56,9 @@ The `message` property of the response body may contain additional details about
|
|||
| `400 "Bad request"` | error details about rejected points, up to 100 points: `line` contains the first rejected line, `message` describes rejections line | If request data is malformed |
|
||||
| `401 "Unauthorized"` | | If the `Authorization` header is missing or malformed or if the [token](/influxdb/cloud-dedicated/admin/tokens/) doesn't have [permission](/influxdb/cloud-dedicated/reference/cli/influxctl/token/create/#examples) to write to the database. See [examples using credentials](/influxdb/cloud-dedicated/get-started/write/#write-line-protocol-to-influxdb) in write requests. |
|
||||
| `404 "Not found"` | requested **resource type** (for example, "organization" or "database"), and **resource name** | If a requested resource (for example, organization or database) wasn't found |
|
||||
| `422 "Unprocessable Entity"` | `message` contains details about the error | If the data isn't allowed (for example, falls outside of the database’s retention period).
|
||||
| `500 "Internal server error"` | | Default status for an error |
|
||||
| `503 "Service unavailable"` | | If the server is temporarily unavailable to accept writes. The `Retry-After` header contains the number of seconds to wait before trying the write again.
|
||||
| `503 "Service unavailable"` | | If the server is temporarily unavailable to accept writes. The `Retry-After` header contains the number of seconds to wait before trying the write again.
|
||||
|
||||
The `message` property of the response body may contain additional details about the error.
|
||||
If your data did not write to the database, see how to [troubleshoot rejected points](#troubleshoot-rejected-points).
|
||||
|
|
|
|||
|
|
@ -1,14 +1,17 @@
|
|||
StylesPath = "../../../.ci/vale/styles"
|
||||
|
||||
Vocab = Cloud-Serverless
|
||||
Vocab = InfluxDataDocs
|
||||
|
||||
MinAlertLevel = warning
|
||||
|
||||
Packages = Google, Hugo, write-good
|
||||
Packages = Google, write-good, Hugo
|
||||
|
||||
[*.md]
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Google, write-good
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Cloud-Serverless, Google, write-good
|
||||
|
||||
Google.Acronyms = NO
|
||||
Google.DateFormat = NO
|
||||
Google.Ellipses = NO
|
||||
Google.Headings = NO
|
||||
Google.WordList = NO
|
||||
Google.WordList = NO
|
||||
Vale.Spelling = NO
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: Get started querying data
|
||||
seotitle: Query data | Get started with InfluxDB
|
||||
seotitle: Query data | Get started with InfluxDB Cloud Serverless
|
||||
list_title: Query data
|
||||
description: >
|
||||
Get started querying data in InfluxDB by learning about SQL and InfluxQL, and
|
||||
|
|
@ -402,10 +402,15 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
{{< expand-wrapper >}}
|
||||
{{% expand "<span class='req'>Important</span>: If using **Windows**, specify the **Windows** certificate path" %}}
|
||||
|
||||
When instantiating the client, Python looks for SSL/TLS certificate authority (CA) certificates for verifying the server's authenticity.
|
||||
If using a non-POSIX-compliant operating system (such as Windows), you need to specify a certificate bundle path that Python can access on your system.
|
||||
When instantiating the client, Python looks for SSL/TLS certificate authority
|
||||
(CA) certificates for verifying the server's authenticity.
|
||||
If using a non-POSIX-compliant operating system (such as Windows), you need to
|
||||
specify a certificate bundle path that Python can access on your system.
|
||||
|
||||
The following example shows how to use the [Python `certifi` package](https://certifiio.readthedocs.io/en/latest/) and client library options to provide a bundle of trusted certificates to the Python Flight client:
|
||||
The following example shows how to use the
|
||||
[Python `certifi` package](https://certifiio.readthedocs.io/en/latest/) and
|
||||
client library options to provide a bundle of trusted certificates to the
|
||||
Python Flight client:
|
||||
|
||||
1. In your terminal, install the Python `certifi` package.
|
||||
|
||||
|
|
@ -444,28 +449,30 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
|
||||
2. Calls the `InfluxDBClient3()` constructor method with credentials to instantiate an InfluxDB `client` with the following credentials:
|
||||
|
||||
- **`host`**: {{% product-name %}} region hostname (URL without protocol or trailing slash)
|
||||
- **`host`**: {{% product-name %}} region hostname
|
||||
(without `https://` protocol or trailing slash)
|
||||
- **`database`**: the name of the [{{% product-name %}} bucket](/influxdb/cloud-serverless/admin/buckets/) to query
|
||||
- **`token`**: an [API token](/influxdb/cloud-serverless/admin/tokens/) with _read_ access to the specified bucket.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
_Store this in a secret store or environment variable to avoid exposing
|
||||
the raw token string._
|
||||
|
||||
3. Defines the SQL query to execute and assigns it to a `query` variable.
|
||||
1. Defines the SQL query to execute and assigns it to a `query` variable.
|
||||
|
||||
4. Calls the `client.query()` method with the SQL query.
|
||||
2. Calls the `client.query()` method with the SQL query.
|
||||
`query()` sends a
|
||||
Flight request to InfluxDB, queries the database (bucket), retrieves result data from the endpoint, and then returns a
|
||||
[`pyarrow.Table`](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table)
|
||||
assigned to the `table` variable.
|
||||
|
||||
5. Calls the [`to_pandas()` method](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas)
|
||||
3. Calls the [`to_pandas()` method](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas)
|
||||
to convert the Arrow table to a [`pandas.DataFrame`](https://arrow.apache.org/docs/python/pandas.html).
|
||||
|
||||
6. Calls the [`pandas.DataFrame.to_markdown()` method](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_markdown.html)
|
||||
4. Calls the [`pandas.DataFrame.to_markdown()` method](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_markdown.html)
|
||||
to convert the DataFrame to a markdown table.
|
||||
|
||||
7. Calls the `print()` method to print the markdown table to stdout.
|
||||
5. Calls the `print()` method to print the markdown table to stdout.
|
||||
|
||||
6. In your terminal, enter the following command to run the program and query {{% product-name %}}:
|
||||
1. In your terminal, enter the following command to run the program and query {{% product-name %}}:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -609,14 +616,18 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
- **`Host`**: your {{% product-name %}} region URL
|
||||
- **`Database`**: The name of your {{% product-name %}} bucket
|
||||
- **`Token`**: an [API token](/influxdb/cloud-serverless/admin/tokens/) with read permission on the specified bucket.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
_Store this in a secret store or environment variable to avoid
|
||||
exposing the raw token string._
|
||||
|
||||
2. Defines a deferred function to close the client after execution.
|
||||
3. Defines a string variable for the SQL query.
|
||||
|
||||
4. Calls the `influxdb3.Client.Query(sql string)` method and passes the SQL string to query InfluxDB.
|
||||
`Query(sql string)` method returns an `iterator` for data in the response stream.
|
||||
5. Iterates over rows, formats the timestamp as an [RFC3339 timestamp](/influxdb/cloud-serverless/reference/glossary/#rfc3339-timestamp), and prints the data in table format to stdout.
|
||||
4. Calls the `influxdb3.Client.Query(sql string)` method and passes the
|
||||
SQL string to query InfluxDB.
|
||||
The `Query(sql string)` method returns an `iterator` for data in the
|
||||
response stream.
|
||||
5. Iterates over rows, formats the timestamp as an
|
||||
[RFC3339 timestamp](/influxdb/cloud-serverless/reference/glossary/#rfc3339-timestamp),and prints the data in table format to stdout.
|
||||
|
||||
3. In your editor, open the `main.go` file you created in the
|
||||
[Write data section](/influxdb/cloud-serverless/get-started/write/?t=Go#write-line-protocol-to-influxdb) and insert code to call the `Query()` function--for example:
|
||||
|
|
@ -630,12 +641,13 @@ _If your project's virtual environment is already running, skip to step 3._
|
|||
}
|
||||
```
|
||||
|
||||
4. In your terminal, enter the following command to install the necessary packages, build the module, and run the program:
|
||||
4. In your terminal, enter the following command to install the necessary
|
||||
packages, build the module, and run the program:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
go mod tidy && go build && go run influxdb_go_client
|
||||
go mod tidy && go run influxdb_go_client
|
||||
```
|
||||
|
||||
The program executes the `main()` function that writes the data and prints the query results to the console.
|
||||
|
|
@ -719,8 +731,10 @@ _This tutorial assumes you installed Node.js and npm, and created an `influxdb_j
|
|||
with InfluxDB credentials.
|
||||
|
||||
- **`host`**: your {{% product-name %}} region URL
|
||||
- **`token`**: an [API token](/influxdb/cloud-serverless/admin/tokens/) with _read_ access to the specified bucket.
|
||||
_Store this in a secret store or environment variable to avoid exposing the raw token string._
|
||||
- **`token`**: an [API token](/influxdb/cloud-serverless/admin/tokens/)
|
||||
with _read_ permission on the bucket you want to query.
|
||||
_Store this in a secret store or environment variable to avoid exposing
|
||||
the raw token string._
|
||||
|
||||
3. Defines a string variable (`sql`) for the SQL query.
|
||||
4. Defines an object (`data`) with column names for keys and array values for storing row data.
|
||||
|
|
@ -752,7 +766,7 @@ _This tutorial assumes you installed Node.js and npm, and created an `influxdb_j
|
|||
main();
|
||||
```
|
||||
|
||||
9. In your terminal, execute `index.mjs` to write to and query {{% product-name %}}:
|
||||
6. In your terminal, execute `index.mjs` to write to and query {{% product-name %}}:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -1008,7 +1022,7 @@ _This tutorial assumes using Maven version 3.9, Java version >= 15, and an `infl
|
|||
|
||||
- The `App`, `Write`, and `Query` classes belong to the `com.influxdbv3` package (your project **groupId**).
|
||||
- `App` defines a `main()` function that calls `Write.writeLineProtocol()` and `Query.querySQL()`.
|
||||
4. In your terminal or editor, use Maven to to install dependencies and compile the project code--for example:
|
||||
4. In your terminal or editor, use Maven to install dependencies and compile the project code--for example:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
|
|
@ -1023,8 +1037,6 @@ _This tutorial assumes using Maven version 3.9, Java version >= 15, and an `infl
|
|||
|
||||
**Linux/MacOS**
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
export MAVEN_OPTS="--add-opens=java.base/java.nio=ALL-UNNAMED"
|
||||
```
|
||||
|
|
|
|||
|
|
@ -19,9 +19,11 @@ related:
|
|||
- /telegraf/v1/
|
||||
---
|
||||
|
||||
This tutorial walks you through the fundamental of creating **line protocol** data and writing it to InfluxDB.
|
||||
This tutorial walks you through the fundamental of creating **line protocol**
|
||||
data and writing it to InfluxDB.
|
||||
|
||||
InfluxDB provides many different options for ingesting or writing data, including the following:
|
||||
InfluxDB provides many different options for ingesting or writing data,
|
||||
including the following:
|
||||
|
||||
- Influx user interface (UI)
|
||||
- InfluxDB HTTP API (v1 and v2)
|
||||
|
|
@ -30,15 +32,17 @@ InfluxDB provides many different options for ingesting or writing data, includin
|
|||
- InfluxDB client libraries
|
||||
- `influx` CLI
|
||||
|
||||
If using tools like Telegraf or InfluxDB client libraries, they can
|
||||
build the line protocol for you, but it's good to understand how line protocol works.
|
||||
If using tools like Telegraf or InfluxDB client libraries, they can build the
|
||||
line protocol for you, but it's good to understand how line protocol works.
|
||||
|
||||
## Line protocol
|
||||
|
||||
All data written to InfluxDB is written using **line protocol**, a text-based
|
||||
format that lets you provide the necessary information to write a data point to InfluxDB.
|
||||
format that lets you provide the necessary information to write a data point to
|
||||
InfluxDB.
|
||||
_This tutorial covers the basics of line protocol, but for detailed information,
|
||||
see the [Line protocol reference](/influxdb/cloud-serverless/reference/syntax/line-protocol/)._
|
||||
see the
|
||||
[Line protocol reference](/influxdb/cloud-serverless/reference/syntax/line-protocol/)._
|
||||
|
||||
### Line protocol elements
|
||||
|
||||
|
|
@ -80,7 +84,8 @@ whitespace sensitive.
|
|||
|
||||
---
|
||||
|
||||
_For schema design recommendations, see [InfluxDB schema design](/influxdb/cloud-serverless/write-data/best-practices/schema-design/)._
|
||||
_For schema design recommendations, see
|
||||
[InfluxDB schema design](/influxdb/cloud-serverless/write-data/best-practices/schema-design/)._
|
||||
|
||||
## Construct line protocol
|
||||
|
||||
|
|
@ -109,32 +114,32 @@ The following line protocol sample represents data collected hourly beginning at
|
|||
##### Home sensor data line protocol
|
||||
|
||||
```text
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1641031200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1641034800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1641038400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1641042000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1641045600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1641049200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1641052800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1641056400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1641060000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1641063600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641067200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719924000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719927600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719931200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719934800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719938400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719942000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719945600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719949200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719952800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719956400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719960000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719963600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719967200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200
|
||||
```
|
||||
|
||||
{{% /influxdb/custom-timestamps %}}
|
||||
|
|
@ -210,32 +215,32 @@ The UI confirms that the data has been written successfully.
|
|||
influx write \
|
||||
--bucket get-started \
|
||||
--precision s "
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1641031200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1641034800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1641038400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1641042000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1641045600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1641049200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1641052800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1641056400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1641060000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1641063600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641067200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719924000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719927600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719931200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719934800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719938400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719942000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719945600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719949200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719952800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719956400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719960000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719963600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719967200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200
|
||||
"
|
||||
```
|
||||
|
||||
|
|
@ -261,32 +266,32 @@ Use [Telegraf](/telegraf/v1/) to consume line protocol, and then write it to
|
|||
|
||||
```sh
|
||||
cat <<- EOF > home.lp
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1641031200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1641034800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1641038400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1641042000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1641045600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1641049200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1641052800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1641056400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1641060000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1641063600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641067200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
||||
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719924000
|
||||
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000
|
||||
home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719927600
|
||||
home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600
|
||||
home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719931200
|
||||
home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200
|
||||
home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719934800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800
|
||||
home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719938400
|
||||
home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719942000
|
||||
home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719945600
|
||||
home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600
|
||||
home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719949200
|
||||
home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200
|
||||
home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719952800
|
||||
home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800
|
||||
home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719956400
|
||||
home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400
|
||||
home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719960000
|
||||
home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000
|
||||
home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719963600
|
||||
home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600
|
||||
home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719967200
|
||||
home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200
|
||||
EOF
|
||||
```
|
||||
|
||||
|
|
@ -434,7 +439,7 @@ InfluxDB creates a bucket named `get-started/autogen` and an
|
|||
{{% code-placeholders "API_TOKEN " %}}
|
||||
|
||||
```sh
|
||||
response=$(curl --silent --write-out "%{response_code}:%{errormsg}" \
|
||||
response=$(curl --silent --write-out "%{response_code}:-%{errormsg}" \
|
||||
"https://{{< influxdb/host >}}/write?db=get-started&precision=s" \
|
||||
--header "Authorization: Token API_TOKEN" \
|
||||
--header "Content-type: text/plain; charset=utf-8" \
|
||||
|
|
@ -469,15 +474,15 @@ home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
|||
")
|
||||
|
||||
# Format the response code and error message output.
|
||||
response_code=${response%%:*}
|
||||
errormsg=${response#*:}
|
||||
response_code=${response%%:-*}
|
||||
errormsg=${response#*:-}
|
||||
|
||||
# Remove leading and trailing whitespace from errormsg
|
||||
errormsg=$(echo "${errormsg}" | tr -d '[:space:]')
|
||||
|
||||
echo "$response_code"
|
||||
if [[ $errormsg ]]; then
|
||||
echo "$errormsg"
|
||||
echo "$response"
|
||||
fi
|
||||
```
|
||||
|
||||
|
|
@ -536,9 +541,9 @@ to InfluxDB:
|
|||
{{% code-placeholders "API_TOKEN" %}}
|
||||
|
||||
```sh
|
||||
response=$(curl --silent --write-out "%{response_code}:%{errormsg}" \
|
||||
response=$(curl --silent --write-out "%{response_code}:-%{errormsg}" \
|
||||
"https://{{< influxdb/host >}}/api/v2/write?bucket=get-started&precision=s" \
|
||||
--header "Authorization: Bearer DATABASE_TOKEN" \
|
||||
--header "Authorization: Token DATABASE_TOKEN" \
|
||||
--header "Content-Type: text/plain; charset=utf-8" \
|
||||
--header "Accept: application/json" \
|
||||
--data-binary "
|
||||
|
|
@ -571,8 +576,8 @@ home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200
|
|||
")
|
||||
|
||||
# Format the response code and error message output.
|
||||
response_code=${response%%:*}
|
||||
errormsg=${response#*:}
|
||||
response_code=${response%%:-*}
|
||||
errormsg=${response#*:-}
|
||||
|
||||
# Remove leading and trailing whitespace from errormsg
|
||||
errormsg=$(echo "${errormsg}" | tr -d '[:space:]')
|
||||
|
|
@ -683,32 +688,32 @@ dependencies to your current project.
|
|||
)
|
||||
|
||||
lines = [
|
||||
"home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641027600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600",
|
||||
"home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1641031200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200",
|
||||
"home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1641038400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400",
|
||||
"home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1641042000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000",
|
||||
"home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1641045600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600",
|
||||
"home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1641049200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200",
|
||||
"home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1641052800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800",
|
||||
"home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1641056400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400",
|
||||
"home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1641060000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000",
|
||||
"home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1641063600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600",
|
||||
"home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641067200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200"
|
||||
"home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719927600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600",
|
||||
"home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719931200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200",
|
||||
"home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719938400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400",
|
||||
"home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719942000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000",
|
||||
"home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719945600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600",
|
||||
"home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719949200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200",
|
||||
"home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719952800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800",
|
||||
"home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719956400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400",
|
||||
"home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719960000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000",
|
||||
"home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719963600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600",
|
||||
"home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719967200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200"
|
||||
]
|
||||
|
||||
client.write(lines,write_precision='s')
|
||||
|
|
@ -831,32 +836,32 @@ InfluxDB v3 [influxdb3-go client library package](https://github.com/InfluxCommu
|
|||
// to preserve backslashes and prevent interpretation
|
||||
// of escape sequences--for example, escaped spaces in tag values.
|
||||
lines := [...]string{
|
||||
`home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1641124000`,
|
||||
`home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641124000`,
|
||||
`home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1641127600`,
|
||||
`home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641127600`,
|
||||
`home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1641131200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641131200`,
|
||||
`home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1641134800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641134800`,
|
||||
`home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1641138400`,
|
||||
`home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641138400`,
|
||||
`home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1641142000`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641142000`,
|
||||
`home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1641145600`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641145600`,
|
||||
`home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1641149200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641149200`,
|
||||
`home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1641152800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641152800`,
|
||||
`home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1641156400`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641156400`,
|
||||
`home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1641160000`,
|
||||
`home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641160000`,
|
||||
`home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1641163600`,
|
||||
`home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641163600`,
|
||||
`home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1641167200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641167200`,
|
||||
`home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1719124000`,
|
||||
`home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719124000`,
|
||||
`home,room=Living\ Room temp=21.4,hum=35.9,co=0i 1719127600`,
|
||||
`home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719127600`,
|
||||
`home,room=Living\ Room temp=21.8,hum=36.0,co=0i 1719131200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719131200`,
|
||||
`home,room=Living\ Room temp=22.2,hum=36.0,co=0i 1719134800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719134800`,
|
||||
`home,room=Living\ Room temp=22.2,hum=35.9,co=0i 1719138400`,
|
||||
`home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719138400`,
|
||||
`home,room=Living\ Room temp=22.4,hum=36.0,co=0i 1719142000`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719142000`,
|
||||
`home,room=Living\ Room temp=22.3,hum=36.1,co=0i 1719145600`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719145600`,
|
||||
`home,room=Living\ Room temp=22.3,hum=36.1,co=1i 1719149200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719149200`,
|
||||
`home,room=Living\ Room temp=22.4,hum=36.0,co=4i 1719152800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719152800`,
|
||||
`home,room=Living\ Room temp=22.6,hum=35.9,co=5i 1719156400`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719156400`,
|
||||
`home,room=Living\ Room temp=22.8,hum=36.2,co=9i 1719160000`,
|
||||
`home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719160000`,
|
||||
`home,room=Living\ Room temp=22.5,hum=36.3,co=14i 1719163600`,
|
||||
`home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719163600`,
|
||||
`home,room=Living\ Room temp=22.2,hum=36.4,co=17i 1719167200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719167200`,
|
||||
}
|
||||
|
||||
// Iterate over the lines array and write each line
|
||||
|
|
@ -1007,32 +1012,32 @@ the failure message.
|
|||
* Define line protocol records to write.
|
||||
*/
|
||||
const records = [
|
||||
`home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1641124000`,
|
||||
`home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641124000`,
|
||||
`home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1641127600`,
|
||||
`home,room=Kitchen temp=23.0,hum=36.2,co=0 1641127600`,
|
||||
`home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1641131200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641131200`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1641134800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641134800`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1641138400`,
|
||||
`home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641138400`,
|
||||
`home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1641142000`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641142000`,
|
||||
`home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1641145600`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641145600`,
|
||||
`home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1641149200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641149200`,
|
||||
`home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1641152800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641152800`,
|
||||
`home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1641156400`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641156400`,
|
||||
`home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1641160000`,
|
||||
`home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641160000`,
|
||||
`home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1641163600`,
|
||||
`home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641163600`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1641167200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641167200`,
|
||||
`home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1719124000`,
|
||||
`home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719124000`,
|
||||
`home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1719127600`,
|
||||
`home,room=Kitchen temp=23.0,hum=36.2,co=0 1719127600`,
|
||||
`home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1719131200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719131200`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1719134800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719134800`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1719138400`,
|
||||
`home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719138400`,
|
||||
`home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1719142000`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719142000`,
|
||||
`home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1719145600`,
|
||||
`home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719145600`,
|
||||
`home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1719149200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719149200`,
|
||||
`home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1719152800`,
|
||||
`home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719152800`,
|
||||
`home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1719156400`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719156400`,
|
||||
`home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1719160000`,
|
||||
`home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719160000`,
|
||||
`home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1719163600`,
|
||||
`home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719163600`,
|
||||
`home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1719167200`,
|
||||
`home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719167200`,
|
||||
];
|
||||
|
||||
/**
|
||||
|
|
@ -1204,32 +1209,32 @@ the failure message.
|
|||
* escaped spaces in tag values.
|
||||
*/
|
||||
string[] lines = new string[] {
|
||||
"home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1641027600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600",
|
||||
"home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1641031200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1641038400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1641042000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1641045600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1641049200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1641052800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800",
|
||||
"home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1641056400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400",
|
||||
"home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1641060000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000",
|
||||
"home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1641063600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1641067200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200"
|
||||
"home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1719927600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600",
|
||||
"home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1719931200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1719938400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1719942000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1719945600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1719949200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1719952800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800",
|
||||
"home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1719956400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400",
|
||||
"home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1719960000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000",
|
||||
"home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1719963600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1719967200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200"
|
||||
};
|
||||
|
||||
// Write each record separately.
|
||||
|
|
@ -1408,32 +1413,32 @@ _The tutorial assumes using Maven version 3.9 and Java version >= 15._
|
|||
token, database)) {
|
||||
// Create a list of line protocol records.
|
||||
final List<String> records = List.of(
|
||||
"home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1641024000",
|
||||
"home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1641027600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1641027600",
|
||||
"home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1641031200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1641031200",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1641034800",
|
||||
"home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1641038400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1641038400",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1641042000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1641042000",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1641045600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1641045600",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1641049200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1641049200",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1641052800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1641052800",
|
||||
"home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1641056400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1641056400",
|
||||
"home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1641060000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1641060000",
|
||||
"home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1641063600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1641063600",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1641067200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1641067200"
|
||||
"home,room=Living\\ Room temp=21.1,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Kitchen temp=21.0,hum=35.9,co=0i 1719924000",
|
||||
"home,room=Living\\ Room temp=21.4,hum=35.9,co=0i 1719927600",
|
||||
"home,room=Kitchen temp=23.0,hum=36.2,co=0i 1719927600",
|
||||
"home,room=Living\\ Room temp=21.8,hum=36.0,co=0i 1719931200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.1,co=0i 1719931200",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=0i 1719934800",
|
||||
"home,room=Living\\ Room temp=22.2,hum=35.9,co=0i 1719938400",
|
||||
"home,room=Kitchen temp=22.5,hum=36.0,co=0i 1719938400",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=0i 1719942000",
|
||||
"home,room=Kitchen temp=22.8,hum=36.5,co=1i 1719942000",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=0i 1719945600",
|
||||
"home,room=Kitchen temp=22.8,hum=36.3,co=1i 1719945600",
|
||||
"home,room=Living\\ Room temp=22.3,hum=36.1,co=1i 1719949200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.2,co=3i 1719949200",
|
||||
"home,room=Living\\ Room temp=22.4,hum=36.0,co=4i 1719952800",
|
||||
"home,room=Kitchen temp=22.4,hum=36.0,co=7i 1719952800",
|
||||
"home,room=Living\\ Room temp=22.6,hum=35.9,co=5i 1719956400",
|
||||
"home,room=Kitchen temp=22.7,hum=36.0,co=9i 1719956400",
|
||||
"home,room=Living\\ Room temp=22.8,hum=36.2,co=9i 1719960000",
|
||||
"home,room=Kitchen temp=23.3,hum=36.9,co=18i 1719960000",
|
||||
"home,room=Living\\ Room temp=22.5,hum=36.3,co=14i 1719963600",
|
||||
"home,room=Kitchen temp=23.1,hum=36.6,co=22i 1719963600",
|
||||
"home,room=Living\\ Room temp=22.2,hum=36.4,co=17i 1719967200",
|
||||
"home,room=Kitchen temp=22.7,hum=36.5,co=26i 1719967200"
|
||||
);
|
||||
|
||||
/**
|
||||
|
|
|
|||
|
|
@ -28,6 +28,13 @@ If a query doesn't return any data, it might be due to the following:
|
|||
- Your data falls outside the time range (or other conditions) in the query--for example, the InfluxQL `SHOW TAG VALUES` command uses a default time range of 1 day.
|
||||
- The query (InfluxDB server) timed out.
|
||||
- The query client timed out.
|
||||
- The query return type is not supported by the client library.
|
||||
For example, array or list types may not be supported.
|
||||
In this case, use `array_to_string()` to convert the array value to a string--for example:
|
||||
|
||||
```sql
|
||||
SELECT array_to_string(array_agg([1, 2, 3]), ', ')
|
||||
```
|
||||
|
||||
If a query times out or returns an error, it might be due to the following:
|
||||
|
||||
|
|
|
|||
|
|
@ -24,3 +24,11 @@ This command is only supported when used with **InfluxDB OSS v2** and
|
|||
{{% /warn %}}
|
||||
|
||||
{{< duplicate-oss >}}
|
||||
|
||||
{{% warn %}}
|
||||
#### InfluxDB Cloud Serverless does not support data deletion
|
||||
|
||||
InfluxDB Cloud Serverless does not currently support deleting data.
|
||||
This command is only supported when used with **InfluxDB OSS v2** and
|
||||
**InfluxDB Cloud (TSM)**.
|
||||
{{% /warn %}}
|
||||
|
|
|
|||
|
|
@ -3,7 +3,6 @@ title: Java client library for InfluxDB v3
|
|||
list_title: Java
|
||||
description: >
|
||||
The InfluxDB v3 `influxdb3-java` Java client library integrates with application code to write and query data stored in an InfluxDB Cloud Serverless bucket.
|
||||
external_url: https://github.com/InfluxCommunity/influxdb3-java
|
||||
menu:
|
||||
influxdb_cloud_serverless:
|
||||
name: Java
|
||||
|
|
@ -15,9 +14,351 @@ aliases:
|
|||
- /cloud-serverless/query-data/sql/execute-queries/java/
|
||||
---
|
||||
|
||||
The InfluxDB v3 [`influxdb3-java` Java client library](https://github.com/InfluxCommunity/influxdb3-java) integrates with Java application code
|
||||
to write and query data stored in an {{% product-name %}} bucket.
|
||||
The InfluxDB v3 [`influxdb3-java` Java client library](https://github.com/InfluxCommunity/influxdb3-java) integrates
|
||||
with Java application code to write and query data stored in {{% product-name %}}.
|
||||
|
||||
The documentation for this client library is available on GitHub.
|
||||
InfluxDB client libraries provide configurable batch writing of data to {{% product-name %}}.
|
||||
Use client libraries to construct line protocol data, transform data from other formats
|
||||
to line protocol, and batch write line protocol data to InfluxDB HTTP APIs.
|
||||
|
||||
<a href="https://github.com/InfluxCommunity/influxdb3-java" target="_blank" class="btn github">InfluxDB v3 Java client library</a>
|
||||
InfluxDB v3 client libraries can query {{% product-name %}} using SQL or InfluxQL.
|
||||
The `influxdb3-java` Java client library wraps the Apache Arrow `org.apache.arrow.flight.FlightClient`
|
||||
in a convenient InfluxDB v3 interface for executing SQL and InfluxQL queries, requesting
|
||||
server metadata, and retrieving data from {{% product-name %}} using the Flight protocol with gRPC.
|
||||
|
||||
- [Installation](#installation)
|
||||
- [Using Maven](#using-maven)
|
||||
- [Using Gradle](#using-gradle)
|
||||
- [Importing the client](#importing-the-client)
|
||||
- [API reference](#api-reference)
|
||||
- [Classes](#classes)
|
||||
- [InfluxDBClient interface](#influxdbclient-interface)
|
||||
- [Initialize with credential parameters](#initialize-with-credential-parameters)
|
||||
- [InfluxDBClient instance methods](#influxdbclient-instance-methods)
|
||||
- [InfluxDBClient.writePoint](#influxdbclientwritepoint)
|
||||
- [InfluxDBClient.query](#influxdbclientquery)
|
||||
|
||||
|
||||
#### Example: write and query data
|
||||
|
||||
The following example shows how to use `influxdb3-java` to write and query data stored in {{% product-name %}}.
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | API_TOKEN" %}}
|
||||
|
||||
```java
|
||||
package com.influxdata.demo;
|
||||
|
||||
import com.influxdb.v3.client.InfluxDBClient;
|
||||
import com.influxdb.v3.client.Point;
|
||||
import com.influxdb.v3.client.query.QueryOptions;
|
||||
import com.influxdb.v3.client.query.QueryType;
|
||||
|
||||
import java.time.Instant;
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class HelloInfluxDB {
|
||||
private static final String HOST_URL = "https://{{< influxdb/host >}}"; // your Cloud Serverless region URL
|
||||
private static final String DATABASE = "DATABASE_NAME"; // your InfluxDB bucket
|
||||
private static final char[] TOKEN = System.getenv("API_TOKEN"); // a local environment variable that stores your API token
|
||||
|
||||
// Create a client instance that writes and queries data in your bucket.
|
||||
public static void main(String[] args) {
|
||||
// Instantiate the client with your InfluxDB credentials
|
||||
try (InfluxDBClient client = InfluxDBClient.getInstance(HOST_URL, TOKEN, DATABASE)) {
|
||||
writeData(client);
|
||||
queryData(client);
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("An error occurred while connecting to InfluxDB!");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
// Use the Point class to construct time series data.
|
||||
private static void writeData(InfluxDBClient client) {
|
||||
Point point = Point.measurement("temperature")
|
||||
.setTag("location", "London")
|
||||
.setField("value", 30.01)
|
||||
.setTimestamp(Instant.now().minusSeconds(10));
|
||||
try {
|
||||
client.writePoint(point);
|
||||
System.out.println("Data is written to the bucket.");
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to write data to the bucket.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
// Use SQL to query the most recent 10 measurements
|
||||
private static void queryData(InfluxDBClient client) {
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
System.out.printf("| %-8s | %-8s | %-30s |%n", "location", "value", "time");
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
|
||||
String sql = "select time,location,value from temperature order by time desc limit 10";
|
||||
try (Stream<Object[]> stream = client.query(sql)) {
|
||||
stream.forEach(row -> System.out.printf("| %-8s | %-8s | %-30s |%n", row[1], row[2], row[0]));
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to query data from the bucket.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{% cite %}}Source: [suyashcjoshi/SimpleJavaInfluxDB](https://github.com/suyashcjoshi/SimpleJavaInfluxDB/) on GitHub{{% /cite %}}
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
the name of your {{% product-name %}}
|
||||
[bucket](/influxdb/cloud-serverless/admin/buckets/) to read and write data to
|
||||
- {{% code-placeholder-key %}}`API_TOKEN`{{% /code-placeholder-key %}}: a local
|
||||
environment variable that stores your
|
||||
[token](/influxdb/cloud-serverless/admin/tokens/)--the token must have read
|
||||
and write permissions on the specified bucket.
|
||||
|
||||
### Run the example to write and query data
|
||||
|
||||
1. Build an executable JAR for the project--for example, using Maven:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
mvn package
|
||||
```
|
||||
|
||||
2. In your terminal, run the `java` command to write and query data in your bucket:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```bash
|
||||
java \
|
||||
--add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED \
|
||||
-jar target/PROJECT_NAME.jar
|
||||
```
|
||||
|
||||
Include the following in your command:
|
||||
|
||||
- [`--add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED`](https://arrow.apache.org/docs/java/install.html#id3): with Java version 9 or later and Apache Arrow version 16 or later, exposes JDK internals for Arrow.
|
||||
For more options, see the [Apache Arrow Java install documentation](https://arrow.apache.org/docs/java/install.html).
|
||||
- `-jar target/PROJECT_NAME.jar`: your `.jar` file to run.
|
||||
|
||||
The output is the newly written data from your {{< product-name >}} bucket.
|
||||
|
||||
## Installation
|
||||
|
||||
Include `com.influxdb.influxdb3-java` in your project dependencies.
|
||||
|
||||
{{< code-tabs-wrapper >}}
|
||||
{{% code-tabs %}}
|
||||
[Maven pom.xml](#)
|
||||
[Gradle dependency script](#)
|
||||
{{% /code-tabs %}}
|
||||
{{% code-tab-content %}}
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.influxdb</groupId>
|
||||
<artifactId>influxdb3-java</artifactId>
|
||||
<version>RELEASE</version>
|
||||
</dependency>
|
||||
```
|
||||
{{% /code-tab-content %}}
|
||||
{{% code-tab-content %}}
|
||||
<!--pytest.mark.skip-->
|
||||
```groovy
|
||||
dependencies {
|
||||
|
||||
implementation group: 'com.influxdb', name: 'influxdb3-java', version: 'latest.release'
|
||||
|
||||
}
|
||||
```
|
||||
{{% /code-tab-content %}}
|
||||
{{< /code-tabs-wrapper >}}
|
||||
|
||||
## Importing the client
|
||||
|
||||
The `influxdb3-java` client library package provides
|
||||
`com.influxdb.v3.client` classes for constructing, writing, and querying data
|
||||
stored in {{< product-name >}}.
|
||||
|
||||
## API reference
|
||||
|
||||
- [Interface InfluxDBClient](#interface-influxdbclient)
|
||||
- [Initialize with credential parameters](#initialize-with-credential-parameters)
|
||||
- [InfluxDBClient instance methods](#influxdbclient-instance-methods)
|
||||
- [InfluxDBClient.writePoint](#influxdbclientwritepoint)
|
||||
- [InfluxDBClient.query](#influxdbclientquery)
|
||||
|
||||
|
||||
## InfluxDBClient interface
|
||||
|
||||
`InfluxDBClient` provides an interface for interacting with InfluxDB APIs for writing and querying data.
|
||||
|
||||
The `InfluxDBClient.getInstance` constructor initializes and returns a client instance with the following:
|
||||
|
||||
- A _write client_ configured for writing to the bucket.
|
||||
- An Arrow _Flight client_ configured for querying the bucket.
|
||||
|
||||
To initialize a client, call `getInstance` and pass your credentials as one of
|
||||
the following types:
|
||||
|
||||
- [parameters](#initialize-with-credential-parameters)
|
||||
- a [`ClientConfig`](https://github.com/InfluxCommunity/influxdb3-java/blob/main/src/main/java/com/influxdb/v3/client/config/ClientConfig.java)
|
||||
- a [database connection string](#initialize-using-a-database-connection-string)
|
||||
|
||||
### Initialize with credential parameters
|
||||
|
||||
{{% code-placeholders "host | database | token" %}}
|
||||
|
||||
```java
|
||||
static InfluxDBClient getInstance(@Nonnull final String host,
|
||||
@Nullable final char[] token,
|
||||
@Nullable final String database)
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
- {{% code-placeholder-key %}}`host`{{% /code-placeholder-key %}} (string): The host URL of the InfluxDB instance.
|
||||
- {{% code-placeholder-key %}}`database`{{% /code-placeholder-key %}} (string): The [bucket](/influxdb/cloud-serverless/admin/buckets/) to use for writing and querying.
|
||||
- {{% code-placeholder-key %}}`token`{{% /code-placeholder-key %}} (char array): A [token](/influxdb/cloud-serverless/admin/tokens/) with read/write permissions.
|
||||
|
||||
#### Example: initialize with credential parameters
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | API_TOKEN" %}}
|
||||
|
||||
```java
|
||||
package com.influxdata.demo;
|
||||
|
||||
import com.influxdb.v3.client.InfluxDBClient;
|
||||
import com.influxdb.v3.client.Point;
|
||||
import com.influxdb.v3.client.query.QueryOptions;
|
||||
import com.influxdb.v3.client.query.QueryType;
|
||||
|
||||
import java.time.Instant;
|
||||
import java.util.stream.Stream;
|
||||
|
||||
public class HelloInfluxDB {
|
||||
private static final String HOST_URL = "https://{{< influxdb/host >}}";
|
||||
private static final String DATABASE = "DATABASE_NAME";
|
||||
private static final char[] API_TOKEN = System.getenv("API_TOKEN");
|
||||
|
||||
// Create a client instance, and then write and query data in InfluxDB.
|
||||
public static void main(String[] args) {
|
||||
try (InfluxDBClient client = InfluxDBClient.getInstance(HOST_URL, API_TOKEN, DATABASE)) {
|
||||
writeData(client);
|
||||
queryData(client);
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("An error occurred while connecting with the serverless InfluxDB!");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
your {{% product-name %}} [bucket](/influxdb/cloud-serverless/admin/buckets/)
|
||||
- {{% code-placeholder-key %}}`API_TOKEN`{{% /code-placeholder-key %}}: a local
|
||||
environment variable that stores your
|
||||
[token](/influxdb/cloud-serverless/admin/tokens/)--the token must have the
|
||||
necessary permissions on the specified bucket.
|
||||
|
||||
#### Default tags
|
||||
|
||||
To include default [tags](/influxdb/cloud-serverless/reference/glossary/#tag) in
|
||||
all written data, pass a `Map` of tag keys and values.
|
||||
|
||||
```java
|
||||
InfluxDBClient getInstance(@Nonnull final String host,
|
||||
@Nullable final char[] token,
|
||||
@Nullable final String database,
|
||||
@Nullable Map<String, String> defaultTags)
|
||||
```
|
||||
|
||||
### Initialize using a database connection string
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME | API_TOKEN" %}}
|
||||
|
||||
```java
|
||||
"https://{{< influxdb/host >}}"
|
||||
+ "?token=API_TOKEN&database=DATABASE_NAME"
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}:
|
||||
your {{% product-name %}} [bucket](/influxdb/cloud-serverless/admin/buckets/)
|
||||
- {{% code-placeholder-key %}}`API_TOKEN`{{% /code-placeholder-key %}}: a
|
||||
[token](/influxdb/cloud-serverless/admin/tokens/) that has the
|
||||
necessary permissions on the specified bucket.
|
||||
|
||||
### InfluxDBClient instance methods
|
||||
|
||||
#### InfluxDBClient.writePoint
|
||||
|
||||
To write points as line protocol to a bucket:
|
||||
|
||||
1. [Initialize the `client`](#initialize-with-credential-parameters)--your
|
||||
token must have write permission on the specified bucket.
|
||||
2. Use the `com.influxdb.v3.client.Point` class to create time series data.
|
||||
3. Call the `client.writePoint()` method to write points as line protocol in your
|
||||
bucket.
|
||||
|
||||
```java
|
||||
// Use the Point class to construct time series data.
|
||||
// Call client.writePoint to write the point in your bucket.
|
||||
private static void writeData(InfluxDBClient client) {
|
||||
Point point = Point.measurement("temperature")
|
||||
.setTag("location", "London")
|
||||
.setField("value", 30.01)
|
||||
.setTimestamp(Instant.now().minusSeconds(10));
|
||||
try {
|
||||
client.writePoint(point);
|
||||
System.out.println("Data written to the bucket.");
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to write data to the bucket.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### InfluxDBClient.query
|
||||
|
||||
To query data and process the results:
|
||||
|
||||
1. [Initialize the `client`](#initialize-with-credential-parameters)--your
|
||||
token must have read permission on the bucket you want to query.
|
||||
2. Call `client.query()` and provide your SQL query as a string.
|
||||
3. Use the result stream's built-in iterator to process row data.
|
||||
|
||||
```java
|
||||
// Query the latest 10 measurements using SQL
|
||||
private static void queryData(InfluxDBClient client) {
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
System.out.printf("| %-8s | %-8s | %-30s |%n", "location", "value", "time");
|
||||
System.out.printf("--------------------------------------------------------%n");
|
||||
|
||||
String sql = "select time,location,value from temperature order by time desc limit 10";
|
||||
try (Stream<Object[]> stream = client.query(sql)) {
|
||||
stream.forEach(row -> System.out.printf("| %-8s | %-8s | %-30s |%n", row[1], row[2], row[0]));
|
||||
}
|
||||
catch (Exception e) {
|
||||
System.err.println("Failed to query data from the bucket.");
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<a class="btn" href="https://github.com/InfluxCommunity/influxdb3-java/" target="\_blank">View the InfluxDB v3 Java client library</a>
|
||||
|
|
|
|||
|
|
@ -15,45 +15,9 @@ aliases:
|
|||
- /influxdb/cloud-serverless/reference/client-libraries/v3/pyinflux3/
|
||||
related:
|
||||
- /influxdb/cloud-serverless/query-data/execute-queries/troubleshoot/
|
||||
list_code_example: >
|
||||
<!-- Import for tests and hide from users.
|
||||
```python
|
||||
import os
|
||||
```
|
||||
-->
|
||||
<!--pytest-codeblocks:cont-->
|
||||
```python
|
||||
from influxdb_client_3 import(InfluxDBClient3,
|
||||
WriteOptions,
|
||||
write_client_options)
|
||||
|
||||
# Instantiate batch writing options for the client
|
||||
|
||||
write_options = WriteOptions()
|
||||
wco = write_client_options(write_options=write_options)
|
||||
|
||||
# Instantiate an InfluxDB v3 client
|
||||
|
||||
with InfluxDBClient3(host=f"{{< influxdb/host >}}",
|
||||
database=f"BUCKET_NAME",
|
||||
token=f"API_TOKEN",
|
||||
write_client_options=wco) as client:
|
||||
|
||||
# Write data in batches
|
||||
client.write_file(file='./data/home-sensor-data.csv', timestamp_column='time',
|
||||
tag_columns=["room"])
|
||||
|
||||
# Execute a query and retrieve data formatted as a PyArrow Table
|
||||
|
||||
table = client.query(
|
||||
'''SELECT *
|
||||
FROM home
|
||||
WHERE time >= now() - INTERVAL '90 days'
|
||||
ORDER BY time''')
|
||||
```
|
||||
---
|
||||
|
||||
The InfluxDB v3 [`influxdb3-python` Python client library](https://github.com/InfluxCommunity/influxdb3-python)
|
||||
The InfluxDB v3 [`influxdb3-python` Python client library](https://github.com/InfluxCommunity/influxdb3-python/)
|
||||
integrates {{% product-name %}} write and query operations with Python scripts and applications.
|
||||
|
||||
InfluxDB client libraries provide configurable batch writing of data to {{% product-name %}}.
|
||||
|
|
@ -85,8 +49,8 @@ Code samples in this page use the [Get started home sensor sample data](/influxd
|
|||
- [Class WriteOptions](#class-writeoptions)
|
||||
- [Parameters](#parameters-4)
|
||||
- [Functions](#functions)
|
||||
- [Function write_client_options(\*\*kwargs)](#function-write_client_optionskwargs)
|
||||
- [Function flight_client_options(\*\*kwargs)](#function-flight_client_optionskwargs)
|
||||
- [Function write_client_options(**kwargs)](#function-write_client_optionskwargs)
|
||||
- [Function flight_client_options(**kwargs)](#function-flight_client_optionskwargs)
|
||||
- [Constants](#constants)
|
||||
- [Exceptions](#exceptions)
|
||||
|
||||
|
|
@ -143,6 +107,11 @@ The `influxdb_client_3` module includes the following classes and functions.
|
|||
- [Class Point](#class-point)
|
||||
- [Class WriteOptions](#class-writeoptions)
|
||||
- [Parameters](#parameters-4)
|
||||
- [Functions](#functions)
|
||||
- [Function write_client_options(**kwargs)](#function-write_client_optionskwargs)
|
||||
- [Function flight_client_options(**kwargs)](#function-flight_client_optionskwargs)
|
||||
- [Constants](#constants)
|
||||
- [Exceptions](#exceptions)
|
||||
|
||||
## Class InfluxDBClient3
|
||||
|
||||
|
|
@ -186,10 +155,10 @@ Given that `write_client_options` isn't specified, the client uses the default [
|
|||
```python
|
||||
import os
|
||||
```
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from influxdb_client_3 import InfluxDBClient3
|
||||
|
||||
|
|
@ -216,6 +185,7 @@ To explicitly specify synchronous mode, create a client with `write_options=SYNC
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -270,6 +240,7 @@ specify callback functions for the response status (success, error, or retryable
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -283,16 +254,16 @@ status = None
|
|||
# Define callbacks for write responses
|
||||
def success(self, data: str):
|
||||
status = "Success writing batch: data: {data}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
def error(self, data: str, err: InfluxDBError):
|
||||
status = f"Error writing batch: config: {self}, data: {data}, error: {err}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
|
||||
def retry(self, data: str, err: InfluxDBError):
|
||||
status = f"Retry error writing batch: config: {self}, data: {data}, error: {err}"
|
||||
assert status.startsWith('Success'), f"Expected {status} to be success"
|
||||
assert status.startswith('Success'), f"Expected {status} to be success"
|
||||
|
||||
# Instantiate WriteOptions for batching
|
||||
write_options = WriteOptions()
|
||||
|
|
@ -348,6 +319,7 @@ Writes a record or a list of records to InfluxDB.
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -401,6 +373,7 @@ data to InfluxDB.
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -534,6 +507,7 @@ and how to write data from CSV and JSON files to InfluxDB:
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -636,6 +610,7 @@ Returns all data in the query result as an Arrow table ([`pyarrow.Table`](https:
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -672,6 +647,7 @@ In the examples, replace the following:
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -698,6 +674,7 @@ print(table.select(['room', 'temp']))
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -723,6 +700,7 @@ print(pd.to_markdown())
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -750,6 +728,7 @@ print(table.schema)
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -776,6 +755,7 @@ Pass `timeout=<number of seconds>` for [`FlightCallOptions`](https://arrow.apach
|
|||
import os
|
||||
```
|
||||
-->
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
|
|
@ -980,3 +960,5 @@ Replace the following:
|
|||
## Exceptions
|
||||
|
||||
- `influxdb_client_3.InfluxDBError`: Exception class raised for InfluxDB-related errors
|
||||
|
||||
<a class="btn" href="https://github.com/InfluxCommunity/influxdb3-python/" target="\_blank">View the InfluxDB v3 Python client library</a>
|
||||
|
|
|
|||
|
|
@ -45,7 +45,7 @@ regexp_like(str, regexp[, flags])
|
|||
- **U**: (ungreedy) Swap the meaning of `x*` and `x*?`.
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "View `regexp_replace` query example" %}}
|
||||
{{% expand "View `regexp_like` query example" %}}
|
||||
|
||||
_The following example uses the sample data set provided in
|
||||
[Get started with InfluxDB tutorial](/influxdb/cloud-serverless/get-started/write/#construct-line-protocol)._
|
||||
|
|
@ -84,7 +84,7 @@ regexp_match(str, regexp, flags)
|
|||
- **i**: (insensitive) Ignore case when matching.
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "View `regexp_replace` query example" %}}
|
||||
{{% expand "View `regexp_match` query example" %}}
|
||||
|
||||
_The following example uses the sample data set provided in
|
||||
[Get started with InfluxDB tutorial](/influxdb/cloud-serverless/get-started/write/#construct-line-protocol)._
|
||||
|
|
|
|||
|
|
@ -0,0 +1,22 @@
|
|||
---
|
||||
title: Delete predicate syntax
|
||||
list_title: Delete predicate
|
||||
description: >
|
||||
InfluxDB uses an InfluxQL-like predicate syntax to determine what data points to delete.
|
||||
menu:
|
||||
influxdb_cloud_serverless:
|
||||
parent: Syntax
|
||||
name: Delete predicate
|
||||
weight: 104
|
||||
influxdb/cloud-serverless/tags: [syntax, delete]
|
||||
related:
|
||||
- /influxdb/cloud-serverless/write-data/delete-data/
|
||||
- /influxdb/cloud-serverless/reference/cli/influx/delete/
|
||||
---
|
||||
{{% warn %}}
|
||||
#### InfluxDB Cloud Serverless does not support data deletion
|
||||
|
||||
InfluxDB Cloud Serverless does not currently support deleting data.
|
||||
This command is only supported when used with **InfluxDB OSS v2** and
|
||||
**InfluxDB Cloud (TSM)**.
|
||||
{{% /warn %}}
|
||||
|
|
@ -51,12 +51,13 @@ The `message` property of the response body may contain additional details about
|
|||
|
||||
| HTTP response code | Response body | Description |
|
||||
| :-------------------------------| :--------------------------------------------------------------- | :------------- |
|
||||
| `204 "No Content"` | error details about rejected points, up to 100 points: `line` contains the first rejected line, `message` describes rejected points | If InfluxDB ingested some or all of the data |
|
||||
| `201 "Created"` | error details about rejected points, up to 100 points, `line` contains the first rejected line, `message` describes rejections | If some of the data is ingested and some of the data is rejected |
|
||||
| `204 "No Content"` | no response body | If InfluxDB ingested all of the data in the batch |
|
||||
| `400 "Bad request"` | `line` contains the first malformed line, `message` describes rejected points | If request data is malformed |
|
||||
| `401 "Unauthorized"` | | If the `Authorization` header is missing or malformed or if the [token](/influxdb/cloud-serverless/admin/tokens/) doesn't have [permission](/influxdb/cloud-serverless/admin/tokens/create-token/) to write to the bucket. See [examples using credentials](/influxdb/cloud-serverless/get-started/write/#write-line-protocol-to-influxdb) in write requests. |
|
||||
| `403 "Forbidden"` | `message` contains details about the error | If the data isn't allowed (for example, falls outside of the bucket's retention period).
|
||||
| `404 "Not found"` | requested **resource type** (for example, "organization" or "bucket"), and **resource name** | If a requested resource (for example, organization or bucket) wasn't found |
|
||||
| `413 “Request too large”` | cannot read data: points in batch is too large | If a request exceeds the maximum [global limit](/influxdb/cloud-serverless/admin/billing/limits/) |
|
||||
| `422 "Unprocessable Entity"` | `message` contains details about the error | If the data isn't allowed (for example, falls outside of the bucket's retention period).
|
||||
| `429 “Too many requests”` | | If the number of requests exceeds the [adjustable service quota](/influxdb/cloud-serverless/admin/billing/limits/#adjustable-service-quotas). The `Retry-After` header contains the number of seconds to wait before trying the write again. | If a request exceeds your plan's [adjustable service quotas](/influxdb/cloud-serverless/admin/billing/limits/#adjustable-service-quotas)
|
||||
| `500 "Internal server error"` | | Default status for an error |
|
||||
| `503 "Service unavailable"` | | If the server is temporarily unavailable to accept writes. The `Retry-After` header contains the number of seconds to wait before trying the write again.
|
||||
|
|
|
|||
|
|
@ -9,68 +9,145 @@ menu:
|
|||
parent: No-code solutions
|
||||
---
|
||||
|
||||
Write data to InfluxDB by configuring third-party technologies that don't require coding.
|
||||
|
||||
A number of third-party technologies can be configured to send line protocol directly to InfluxDB.
|
||||
## Prerequisites
|
||||
|
||||
If you're using any of the following technologies, check out the handy links below to configure these technologies to write data to InfluxDB (**no additional software to download or install**):
|
||||
- Authentication credentials for your InfluxDB instance: your InfluxDB host URL,
|
||||
[organization](/influxdb/cloud/admin/organizations/),
|
||||
[bucket](/influxdb/cloud/admin/buckets/), and an [API token](/influxdb/cloud/admin/tokens/)
|
||||
with write permission on the bucket.
|
||||
|
||||
- (Write metrics and log events only) [Configure Vector 0.9 or later](#configure-vector)
|
||||
- [Configure Apache NiFi 1.8 or later](#configure-apache-nifi)
|
||||
- [Configure OpenHAB 3.0 or later](#configure-openhab)
|
||||
- [Configure Apache JMeter 5.2 or later](#configure-apache-jmeter)
|
||||
- [Configure FluentD 1.x or later](#configure-fluentd)
|
||||
To setup InfluxDB and create credentials, follow the
|
||||
[Get started](/influxdb/cloud/get-started/) guide.
|
||||
|
||||
#### Configure Vector
|
||||
- Access to one of the third-party tools listed in this guide.
|
||||
|
||||
1. View the **Vector documentation**:
|
||||
- For write metrics, [InfluxDB Metrics Sink](https://vector.dev/docs/reference/sinks/influxdb_metrics/)
|
||||
- For log events, [InfluxDB Logs Sink](https://vector.dev/docs/reference/sinks/influxdb_logs/)
|
||||
2. Under **Configuration**, click **v2** to view configuration settings.
|
||||
3. Scroll down to **How It Works** for more detail:
|
||||
- [InfluxDB Metrics Sink – How It Works ](https://vector.dev/docs/reference/sinks/influxdb_metrics/#how-it-works)
|
||||
- [InfluxDB Logs Sink – How It Works](https://vector.dev/docs/reference/sinks/influxdb_logs/#how-it-works)
|
||||
You can configure the following third-party tools to send line protocol data
|
||||
directly to InfluxDB without writing code:
|
||||
|
||||
#### Configure Apache NiFi
|
||||
{{% note %}}
|
||||
Many third-party integrations are community contributions.
|
||||
If there's an integration missing from the list below, please [open a docs issue](https://github.com/influxdata/docs-v2/issues/new/choose) to let us know.
|
||||
{{% /note %}}
|
||||
|
||||
See the _[InfluxDB Processors for Apache NiFi Readme](https://github.com/influxdata/nifi-influxdb-bundle#influxdb-processors-for-apache-nifi)_ for details.
|
||||
- [Vector 0.9 or later](#configure-vector)
|
||||
|
||||
#### Configure OpenHAB
|
||||
- [Apache NiFi 1.8 or later](#configure-apache-nifi)
|
||||
|
||||
See the _[InfluxDB Persistence Readme](https://github.com/openhab/openhab-addons/tree/master/bundles/org.openhab.persistence.influxdb)_ for details.
|
||||
- [OpenHAB 3.0 or later](#configure-openhab)
|
||||
|
||||
#### Configure Apache JMeter
|
||||
- [Apache JMeter 5.2 or later](#configure-apache-jmeter)
|
||||
|
||||
<!-- after doc updates are made, we can simplify to: See the _[Apache JMeter User's Manual - JMeter configuration](https://jmeter.apache.org/usermanual/realtime-results.html#jmeter-configuration)_ for details. -->
|
||||
- [Apache Pulsar](#configure-apache-pulsar)
|
||||
|
||||
To configure Apache JMeter, complete the following steps in InfluxDB and JMeter.
|
||||
- [FluentD 1.x or later](#configure-fluentd)
|
||||
|
||||
##### In InfluxDB
|
||||
|
||||
1. [Find the name of your organization](/influxdb/cloud/admin/organizations/view-orgs/) (needed to create a bucket and token).
|
||||
2. [Create a bucket using the influx CLI](/influxdb/cloud/admin/buckets/create-bucket/#create-a-bucket-using-the-influx-cli) and name it `jmeter`.
|
||||
3. [Create a token](/influxdb/cloud/admin/tokens/create-token/).
|
||||
## Configure Vector
|
||||
|
||||
##### In JMeter
|
||||
> Vector is a lightweight and ultra-fast tool for building observability pipelines.
|
||||
>
|
||||
> {{% cite %}}-- [Vector documentation](https://vector.dev/docs/){{% /cite %}}
|
||||
|
||||
Configure Vector to write metrics and log events to an InfluxDB instance.
|
||||
|
||||
1. Configure your [InfluxDB authentication credentials](#prerequisites) for Vector to write to your bucket.
|
||||
- View example configurations:
|
||||
- [InfluxDB metrics sink configuration](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#configuration)
|
||||
- [InfluxDB logs sink configuration](https://vector.dev/docs/reference/configuration/sinks/influxdb_logs/#example-configurations)
|
||||
- Use the following Vector configuration fields for InfluxDB v2 credentials:
|
||||
- [`endpoint`](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#endpoint):
|
||||
the URL (including scheme, host, and port) for your InfluxDB instance
|
||||
- [`org`](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#org):
|
||||
the name of your InfluxDB organization
|
||||
- [`bucket`](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#bucket):
|
||||
the name of the bucket to write data to
|
||||
- [`token`](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#token):
|
||||
an API token with write permission on the specified bucket
|
||||
|
||||
3. Configure the data that you want Vector to write to InfluxDB.
|
||||
- View [examples of metrics events and configurations](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#examples).
|
||||
- View [Telemetry log metrics](https://vector.dev/docs/reference/configuration/sinks/influxdb_logs/#telemetry).
|
||||
|
||||
4. For more detail, see the **How it works** sections:
|
||||
- [InfluxDB metrics sink–-How it works](https://vector.dev/docs/reference/configuration/sinks/influxdb_metrics/#how-it-works)
|
||||
- [InfluxDB logs sink–-How it works](https://vector.dev/docs/reference/configuration/sinks/influxdb_logs/#how-it-works)
|
||||
|
||||
## Configure Apache NiFi
|
||||
|
||||
> [Apache NiFi](https://nifi.apache.org/documentation/v1/) is a software project from the Apache Software Foundation designed to automate the flow of data between software systems.
|
||||
>
|
||||
> {{% cite %}}-- [Wikipedia](https://en.wikipedia.org/wiki/Apache_NiFi){{% /cite %}}
|
||||
|
||||
The InfluxDB processors for Apache NiFi lets you write NiFi Record structured
|
||||
data into InfluxDB v2.
|
||||
|
||||
See
|
||||
_[InfluxDB Processors for Apache NiFi](https://github.com/influxdata/nifi-influxdb-bundle#influxdb-processors-for-apache-nifi)_
|
||||
on GitHub for details.
|
||||
|
||||
## Configure OpenHAB
|
||||
|
||||
> The open Home Automation Bus (openHAB, pronounced ˈəʊpənˈhæb) is an open source, technology agnostic home automation platform
|
||||
>
|
||||
> {{% cite %}}-- [openHAB documentation](https://www.openhab.org/docs/){{% /cite %}}
|
||||
|
||||
> [The InfluxDB Persistence add-on] service allows you to persist and query states using the [InfluxDB] time series database.
|
||||
>
|
||||
> {{% cite %}}-- [openHAB InfluxDB persistence add-on](https://github.com/openhab/openhab-addons/tree/main/bundles/org.openhab.persistence.influxdb){{% /cite %}}
|
||||
|
||||
See
|
||||
_[InfluxDB Persistence add-on](https://github.com/openhab/openhab-addons/tree/master/bundles/org.openhab.persistence.influxdb)_
|
||||
on GitHub for details.
|
||||
|
||||
## Configure Apache JMeter
|
||||
|
||||
> [Apache JMeter](https://jmeter.apache.org/) is an Apache project that can be used as a load testing tool for
|
||||
> analyzing and measuring the performance of a variety of services, with a focus
|
||||
> on web applications.
|
||||
>
|
||||
> {{% cite %}}-- [Wikipedia](https://en.wikipedia.org/wiki/Apache_JMeter){{% /cite %}}
|
||||
|
||||
1. Create a [Backend Listener](https://jmeter.apache.org/usermanual/component_reference.html#Backend_Listener) using the _**InfluxDBBackendListenerClient**_ implementation.
|
||||
2. In the **Backend Listener implementation** field, enter:
|
||||
```
|
||||
```text
|
||||
org.apache.jmeter.visualizers.backend.influxdb.influxdbBackendListenerClient
|
||||
```
|
||||
3. Under **Parameters**, specify the following:
|
||||
- **influxdbMetricsSender**:
|
||||
```
|
||||
```text
|
||||
org.apache.jmeter.visualizers.backend.influxdb.HttpMetricsSender
|
||||
```
|
||||
- **influxdbUrl**: _(include the bucket and org you created in InfluxDB)_
|
||||
```
|
||||
```text
|
||||
https://cloud2.influxdata.com/api/v2/write?org=my-org&bucket=jmeter
|
||||
```
|
||||
- **application**: `InfluxDB2`
|
||||
- **influxdbToken**: _your InfluxDB API token_
|
||||
- **influxdbToken**: _your InfluxDB API token with write permission on the
|
||||
specified bucket_
|
||||
- Include additional parameters as needed.
|
||||
4. Click **Add** to add the _**InfluxDBBackendListenerClient**_ implementation.
|
||||
1. Click **Add** to add the _**InfluxDBBackendListenerClient**_ implementation.
|
||||
|
||||
#### Configure FluentD
|
||||
## Configure Apache Pulsar
|
||||
|
||||
See the _[influxdb-plugin-fluent Readme](https://github.com/influxdata/influxdb-plugin-fluent)_ for details.
|
||||
> Apache Pulsar is an open source, distributed messaging and streaming platform
|
||||
> built for the cloud.
|
||||
>
|
||||
> The InfluxDB sink connector pulls messages from Pulsar topics and persists the
|
||||
messages to InfluxDB.
|
||||
>
|
||||
> {{% cite %}}-- [Apache Pulsar](https://pulsar.apache.org/){{% /cite %}}
|
||||
|
||||
See _[InfluxDB sink connector](https://pulsar.apache.org/docs/en/io-influxdb-sink/)_
|
||||
for details.
|
||||
|
||||
## Configure FluentD
|
||||
|
||||
> [Fluentd](https://www.fluentd.org/) is a cross-platform open-source data
|
||||
> collection software project.
|
||||
>
|
||||
> {{% cite %}}-- [Wikipedia](https://en.wikipedia.org/wiki/Fluentd){{% /cite %}}
|
||||
|
||||
See _[influxdb-plugin-fluent](https://github.com/influxdata/influxdb-plugin-fluent)_
|
||||
on GitHub for details.
|
||||
|
|
|
|||
|
|
@ -1,14 +1,17 @@
|
|||
StylesPath = "../../../.ci/vale/styles"
|
||||
|
||||
Vocab = Clustered
|
||||
Vocab = InfluxDataDocs
|
||||
|
||||
MinAlertLevel = warning
|
||||
|
||||
Packages = Google, Hugo, write-good
|
||||
Packages = Google, write-good, Hugo
|
||||
|
||||
[*.md]
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Google, write-good
|
||||
BasedOnStyles = Vale, InfluxDataDocs, Clustered, Google, write-good
|
||||
|
||||
Google.Acronyms = NO
|
||||
Google.DateFormat = NO
|
||||
Google.Ellipses = NO
|
||||
Google.Headings = NO
|
||||
Google.WordList = NO
|
||||
Google.WordList = NO
|
||||
Vale.Spelling = NO
|
||||
|
|
@ -7,7 +7,7 @@ description: >
|
|||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
weight: 207
|
||||
weight: 208
|
||||
---
|
||||
|
||||
{{< product-name >}} generates a valid access token (known as the _admin token_)
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ description: >
|
|||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
weight: 103
|
||||
weight: 104
|
||||
influxdb/clustered/tags: [storage]
|
||||
related:
|
||||
- /influxdb/clustered/reference/internals/storage-engine/
|
||||
|
|
|
|||
|
|
@ -33,7 +33,7 @@ table.
|
|||
#### Partition templates can only be applied on create
|
||||
|
||||
You can only apply a partition template when creating a database or table.
|
||||
There is no way to update a partition template on an existing resource.
|
||||
You can't update a partition template on an existing resource.
|
||||
{{% /note %}}
|
||||
|
||||
Use the following command flags to identify
|
||||
|
|
@ -71,6 +71,9 @@ The following example creates a new `example-db` database and applies a partitio
|
|||
template that partitions by distinct values of two tags (`room` and `sensor-type`),
|
||||
bucketed values of the `customerID` tag, and by week using the time format `%Y wk:%W`:
|
||||
|
||||
<!--Skip database create and delete tests: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--template-tag room \
|
||||
|
|
@ -82,21 +85,60 @@ influxctl database create \
|
|||
|
||||
## Create a table with a custom partition template
|
||||
|
||||
The following example creates a new `example-table` table in the `example-db`
|
||||
The following example creates a new `example-table` table in the specified
|
||||
database and applies a partition template that partitions by distinct values of
|
||||
two tags (`room` and `sensor-type`), bucketed values of the `customerID` tag,
|
||||
and by month using the time format `%Y-%m`:
|
||||
|
||||
<!--Skip database create and delete tests: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME" %}}
|
||||
|
||||
```sh
|
||||
influxctl table create \
|
||||
--template-tag room \
|
||||
--template-tag sensor-type \
|
||||
--template-tag-bucket customerID,500 \
|
||||
--template-timeformat '%Y-%m' \
|
||||
example-db \
|
||||
DATABASE_NAME \
|
||||
example-table
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following in your command:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}: your {{% product-name %}} [database](/influxdb/clustered/admin/databases/)
|
||||
|
||||
<!--actual test
|
||||
|
||||
```sh
|
||||
|
||||
# Test the preceding command outside of the code block.
|
||||
# influxctl authentication requires TTY interaction--
|
||||
# output the auth URL to a file that the host can open.
|
||||
|
||||
TABLE_NAME=table_TEST_RUN
|
||||
script -c "influxctl table create \
|
||||
--template-tag room \
|
||||
--template-tag sensor-type \
|
||||
--template-tag-bucket customerID,500 \
|
||||
--template-timeformat '%Y-%m' \
|
||||
DATABASE_NAME \
|
||||
$TABLE_NAME" \
|
||||
/dev/null > /shared/urls.txt
|
||||
|
||||
script -c "influxctl query \
|
||||
--database DATABASE_NAME \
|
||||
--token DATABASE_TOKEN \
|
||||
'SHOW TABLES'" > /shared/temp_tables.txt
|
||||
grep -q $TABLE_NAME /shared/temp_tables.txt
|
||||
rm /shared/temp_tables.txt
|
||||
```
|
||||
|
||||
-->
|
||||
|
||||
## Example partition templates
|
||||
|
||||
Given the following [line protocol](/influxdb/clustered/reference/syntax/line-protocol/)
|
||||
|
|
@ -108,7 +150,7 @@ prod,line=A,station=weld1 temp=81.9,qty=36i 1704067200000000000
|
|||
|
||||
##### Partitioning by distinct tag values
|
||||
|
||||
| Description | Tag part(s) | Time part | Resulting partition key |
|
||||
| Description | Tag parts | Time part | Resulting partition key |
|
||||
| :---------------------- | :---------------- | :--------- | :----------------------- |
|
||||
| By day (default) | | `%Y-%m-%d` | 2024-01-01 |
|
||||
| By day (non-default) | | `%d %b %Y` | 01 Jan 2024 |
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ description: >
|
|||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
weight: 101
|
||||
weight: 103
|
||||
influxdb/clustered/tags: [databases]
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -1,20 +1,22 @@
|
|||
---
|
||||
title: Create a database
|
||||
description: >
|
||||
Use the [`influxctl database create` command](/influxdb/clustered/reference/cli/influxctl/database/create/)
|
||||
to create a new InfluxDB database in your InfluxDB cluster.
|
||||
Use the [`influxctl database create` command](/influxdb/clustered/reference/cli/influxctl/database/create/) to create a new InfluxDB database in your InfluxDB cluster.
|
||||
Provide a database name and an optional retention period.
|
||||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Manage databases
|
||||
weight: 201
|
||||
list_code_example: |
|
||||
<!--pytest.mark.skip-->
|
||||
##### CLI
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250 \
|
||||
<DATABASE_NAME>
|
||||
DATABASE_NAME
|
||||
```
|
||||
related:
|
||||
- /influxdb/clustered/reference/cli/influxctl/database/create/
|
||||
|
|
@ -44,7 +46,11 @@ to create a database in your {{< product-name omit=" Clustered" >}} cluster.
|
|||
_{{< product-name >}} supports up to 7 total tags or tag buckets in the partition template._
|
||||
{{% /note %}}
|
||||
|
||||
<!--Allow fail for database create and delete: namespaces aren't reusable-->
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME|30d|500|200" %}}
|
||||
|
||||
```sh
|
||||
influxctl database create \
|
||||
--retention-period 30d \
|
||||
|
|
@ -57,13 +63,16 @@ influxctl database create \
|
|||
--template-timeformat '%Y-%m-%d' \
|
||||
DATABASE_NAME
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
- [Retention period syntax](#retention-period-syntax)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
- [Custom partitioning](#custom-partitioning)
|
||||
- [Table limit](#table-limit)
|
||||
- [Column limit](#column-limit)
|
||||
- [Custom partitioning](#custom-partitioning)
|
||||
|
||||
## Retention period syntax
|
||||
|
||||
|
|
@ -127,7 +136,7 @@ database and retention policy (DBRP) to be queryable with InfluxQL.
|
|||
**When naming a database that you want to query with InfluxQL**, use the following
|
||||
naming convention to automatically map v1 DBRP combinations to an {{% product-name %}} database:
|
||||
|
||||
```sh
|
||||
```text
|
||||
database_name/retention_policy_name
|
||||
```
|
||||
|
||||
|
|
@ -225,5 +234,5 @@ For more information, see [Manage data partitioning](/influxdb/clustered/admin/c
|
|||
#### Partition templates can only be applied on create
|
||||
|
||||
You can only apply a partition template when creating a database.
|
||||
There is no way to update a partition template on an existing database.
|
||||
You can't update a partition template on an existing database.
|
||||
{{% /note %}}
|
||||
|
|
|
|||
|
|
@ -9,10 +9,11 @@ menu:
|
|||
weight: 201
|
||||
list_code_example: |
|
||||
```sh
|
||||
influxctl database update DATABASE_NAME \
|
||||
influxctl database update \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250
|
||||
--max-columns 250 \
|
||||
DATABASE_NAME
|
||||
```
|
||||
related:
|
||||
- /influxdb/clustered/reference/cli/influxctl/database/update/
|
||||
|
|
@ -25,20 +26,27 @@ to update a database in your {{< product-name omit=" Clustered" >}} cluster.
|
|||
2. Run the `influxctl database update` command and provide the following:
|
||||
|
||||
- Database name
|
||||
- _Optional_: Database [retention period](/influxdb/clustered/admin/databases/#retention-periods)
|
||||
_(default is infinite)_
|
||||
- _Optional_: Database table (measurement) limit _(default is 500)_
|
||||
- _Optional_: Database column limit _(default is 250)_
|
||||
- _Optional_: Database [retention period](/influxdb/cloud-dedicated/admin/databases/#retention-periods).
|
||||
Default is infinite (`0`).
|
||||
- _Optional_: Database table (measurement) limit. Default is `500`.
|
||||
- _Optional_: Database column limit. Default is `250`.
|
||||
|
||||
{{% code-placeholders "DATABASE_NAME|30d|500|200" %}}
|
||||
|
||||
```sh
|
||||
influxctl database update DATABASE_NAME \
|
||||
influxctl database update \
|
||||
--retention-period 30d \
|
||||
--max-tables 500 \
|
||||
--max-columns 250
|
||||
--max-columns 250 \
|
||||
DATABASE_NAME
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
Replace the following in your command:
|
||||
|
||||
- {{% code-placeholder-key %}}`DATABASE_NAME`{{% /code-placeholder-key %}}: your {{% product-name %}} [database](/influxdb/clustered/admin/databases/)
|
||||
|
||||
{{% warn %}}
|
||||
#### Database names can't be updated
|
||||
|
||||
|
|
@ -46,25 +54,28 @@ The `influxctl database update` command uses the database name to identify which
|
|||
database to apply updates to. The database name itself can't be updated.
|
||||
{{% /warn %}}
|
||||
|
||||
- [Retention period syntax](#retention-period-syntax)
|
||||
## Database attributes
|
||||
|
||||
- [Retention period syntax](#retention-period-syntax-influxctl-cli)
|
||||
- [Database naming restrictions](#database-naming-restrictions)
|
||||
- [InfluxQL DBRP naming convention](#influxql-dbrp-naming-convention)
|
||||
- [Table and column limits](#table-and-column-limits)
|
||||
|
||||
## Retention period syntax
|
||||
### Retention period syntax (influxctl CLI)
|
||||
|
||||
Use the `--retention-period` flag to define a specific
|
||||
[retention period](/influxdb/clustered/admin/databases/#retention-periods)
|
||||
for the database.
|
||||
The retention period value is a time duration value made up of a numeric value
|
||||
plus a duration unit. For example, `30d` means 30 days.
|
||||
A zero duration retention period is infinite and data will not expire.
|
||||
plus a duration unit.
|
||||
For example, `30d` means 30 days.
|
||||
A zero duration (for example, `0s` or `0d`) retention period is infinite and data won't expire.
|
||||
The retention period value cannot be negative or contain whitespace.
|
||||
|
||||
{{< flex >}}
|
||||
{{% flex-content %}}
|
||||
{{% flex-content "half" %}}
|
||||
|
||||
##### Valid durations units include
|
||||
#### Valid durations units include
|
||||
|
||||
- **m**: minute
|
||||
- **h**: hour
|
||||
|
|
@ -74,9 +85,9 @@ The retention period value cannot be negative or contain whitespace.
|
|||
- **y**: year
|
||||
|
||||
{{% /flex-content %}}
|
||||
{{% flex-content %}}
|
||||
{{% flex-content "half" %}}
|
||||
|
||||
##### Example retention period values
|
||||
#### Example retention period values
|
||||
|
||||
- `0d`: infinite/none
|
||||
- `3d`: 3 days
|
||||
|
|
@ -99,7 +110,7 @@ Database names must adhere to the following naming restrictions:
|
|||
- Should not start with an underscore (`_`).
|
||||
- Maximum length of 64 characters.
|
||||
|
||||
## InfluxQL DBRP naming convention
|
||||
### InfluxQL DBRP naming convention
|
||||
|
||||
In InfluxDB 1.x, data is stored in [databases](/influxdb/v1/concepts/glossary/#database)
|
||||
and [retention policies](/influxdb/v1/concepts/glossary/#retention-policy-rp).
|
||||
|
|
@ -112,11 +123,11 @@ database and retention policy (DBRP) to be queryable with InfluxQL.
|
|||
**When naming a database that you want to query with InfluxQL**, use the following
|
||||
naming convention to automatically map v1 DBRP combinations to a database:
|
||||
|
||||
```sh
|
||||
```text
|
||||
database_name/retention_policy_name
|
||||
```
|
||||
|
||||
##### Database naming examples
|
||||
#### Database naming examples
|
||||
|
||||
| v1 Database name | v1 Retention Policy name | New database name |
|
||||
| :--------------- | :----------------------- | :------------------------ |
|
||||
|
|
@ -124,12 +135,12 @@ database_name/retention_policy_name
|
|||
| telegraf | autogen | telegraf/autogen |
|
||||
| webmetrics | 1w-downsampled | webmetrics/1w-downsampled |
|
||||
|
||||
## Table and column limits
|
||||
### Table and column limits
|
||||
|
||||
In {{< product-name >}}, table (measurement) and column limits can be
|
||||
configured using the `--max-tables` and `--max-columns` flags.
|
||||
|
||||
### Table limit
|
||||
#### Table limit
|
||||
|
||||
**Default maximum number of tables**: 500
|
||||
|
||||
|
|
@ -172,7 +183,7 @@ operating cost of your cluster.
|
|||
{{% /expand %}}
|
||||
{{< /expand-wrapper >}}
|
||||
|
||||
### Column limit
|
||||
#### Column limit
|
||||
|
||||
**Default maximum number of columns**: 250
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,172 @@
|
|||
---
|
||||
title: Manage your InfluxDB Clustered license
|
||||
description: >
|
||||
Install and manage your InfluxDB Clustered license to authorize the use of
|
||||
the InfluxDB Clustered software.
|
||||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
name: Manage your license
|
||||
weight: 101
|
||||
influxdb/clustered/tags: [licensing]
|
||||
related:
|
||||
- /influxdb/clustered/install/licensing/
|
||||
- /influxdb/clustered/admin/upgrade/
|
||||
---
|
||||
|
||||
Install and manage your InfluxDB Clustered license to authorize the use of
|
||||
the InfluxDB Clustered software.
|
||||
|
||||
- [Install your InfluxDB license](#install-your-influxdb-license)
|
||||
- [Recover from a license misconfiguration](#recover-from-a-license-misconfiguration)
|
||||
- [Renew your license](#renew-your-license)
|
||||
- [License enforcement](#license-enforcement)
|
||||
- [A valid license is required](#a-valid-license-is-required)
|
||||
- [Periodic license checks](#periodic-license-checks)
|
||||
- [License grace periods](#license-grace-periods)
|
||||
- [License expiry logs](#license-expiry-logs)
|
||||
- [Query brownout](#query-brownout)
|
||||
|
||||
{{% note %}}
|
||||
#### License enforcement is currently an opt-in feature
|
||||
|
||||
In currently available versions of InfluxDB Clustered, license enforcement is an
|
||||
opt-in feature that allows InfluxData to introduce license enforcement to
|
||||
customers, and allows customers to deactivate the feature if issues arise.
|
||||
In the future, all releases of InfluxDB Clustered will require customers to
|
||||
configure an active license before they can use the product.
|
||||
|
||||
To opt into license enforcement, include the `useLicensedBinaries` feature flag
|
||||
in your `AppInstance` resource _([See the example below](#enable-feature-flag))_.
|
||||
To deactivate license enforcement, remove the `useLicensedBinaries` feature flag.
|
||||
{{% /note %}}
|
||||
|
||||
## Install your InfluxDB license
|
||||
|
||||
{{% note %}}
|
||||
If setting up an InfluxDB Clustered deployment for the first time, first
|
||||
[set up the prerequisites](/influxdb/clustered/install/licensing/) and
|
||||
[configure your cluster](/influxdb/clustered/install/configure-cluster/).
|
||||
After your InfluxDB namespace is created and prepared, you will be able to
|
||||
install your license.
|
||||
{{% /note %}}
|
||||
|
||||
1. If you haven't already,
|
||||
[request an InfluxDB Clustered license](https://influxdata.com/contact-sales).
|
||||
2. InfluxData provides you with a `license.yml` file that encapsulates your
|
||||
license token as a custom Kubernetes resource.
|
||||
3. Use `kubectl` to apply and create the `License` resource in your InfluxDB
|
||||
namespace:
|
||||
|
||||
<!--pytest.mark.skip-->
|
||||
|
||||
```sh
|
||||
kubectl apply --filename license.yml --namespace influxdb
|
||||
```
|
||||
|
||||
4. <span id="enable-feature-flag"></span>
|
||||
Update your `AppInstance` resource to include the `useLicensedBinaries` feature flag.
|
||||
Add the `useLicensedBinaries` entry to the `.spec.package.spec.featureFlags`
|
||||
property--for example:
|
||||
|
||||
```yml
|
||||
apiVersion: kubecfg.dev/v1alpha1
|
||||
kind: AppInstance
|
||||
# ...
|
||||
spec:
|
||||
package:
|
||||
spec:
|
||||
featureFlags:
|
||||
- useLicensedBinaries
|
||||
```
|
||||
|
||||
InfluxDB Clustered detects the `License` resource and extracts the credentials
|
||||
into a secret required by InfluxDB Clustered Kubernetes pods.
|
||||
Pods validate the license secret both at startup and periodically (roughly once
|
||||
per hour) while running.
|
||||
|
||||
## Recover from a license misconfiguration
|
||||
|
||||
If you deploy a licensed release of InfluxDB Clustered with an invalid or
|
||||
expired license, many of the pods in your cluster will crash on startup and will
|
||||
likely enter a `CrashLoopBackoff` state without ever running or becoming healthy.
|
||||
Because InfluxDB stores the license in a volume-mounted Kubernetes secret, invalid
|
||||
licenses affect old and new pods.
|
||||
|
||||
After you apply a valid `License` resource, new pods will begin to start up normally.
|
||||
|
||||
InfluxDB validates a license when you apply it.
|
||||
If the license is invalid when you try to apply it, the `license controller`
|
||||
won't add or update the required secret.
|
||||
|
||||
## Renew your license
|
||||
|
||||
Before your license expires, your InfluxData sales representative will
|
||||
contact you about license renewal.
|
||||
You may also contact your sales representative at any time.
|
||||
|
||||
---
|
||||
|
||||
## License enforcement
|
||||
|
||||
InfluxDB Clustered authorizes use of InfluxDB software through licenses issued
|
||||
by InfluxData. The following sections provide information about InfluxDB Clustered
|
||||
license enforcement.
|
||||
|
||||
### A valid license is required
|
||||
|
||||
_When you include the `useLicensedBinaries` feature flag_,
|
||||
Kubernetes pods running in your InfluxDB cluster must have a valid `License`
|
||||
resource to run. Licenses are issued by InfluxData. If there is no `License`
|
||||
resource installed in your cluster, one of two things may happen:
|
||||
|
||||
- Pods may become stuck in a `ContainerCreating` state if the cluster has
|
||||
never had a valid `License` resource installed.
|
||||
- If an expired or invalid license is installed in the cluster, pods will become
|
||||
stuck in a `CrashLoopBackoff` state.
|
||||
Pod containers will attempt to start, detect the invalid license condition,
|
||||
print an error message, and then exit with a non-zero exit code.
|
||||
|
||||
### Periodic license checks
|
||||
|
||||
During normal operation, pods in your InfluxDB cluster check for a valid license
|
||||
once per hour. You may see messages in your pod logs related to this behavior.
|
||||
|
||||
### License grace periods
|
||||
|
||||
When InfluxData issues a license, it is configured with two expiry dates.
|
||||
The first is the expiry date of the contractual license. The second is a hard
|
||||
expiry of the license credentials, after which pods in your cluster will begin
|
||||
crash-looping until a new, valid license is installed in the cluster.
|
||||
|
||||
The period of time between the contractual license expiry and the hard license
|
||||
expiry is considered the _grace period_. The standard grace period is 90 days,
|
||||
but this may be negotiated as needed with your InfluxData sales representative.
|
||||
|
||||
#### License expiry logs
|
||||
|
||||
The following table outlines license expiry logging behavior to show when the log
|
||||
messages begin, the level (`Warn` or `Error`), and the periodicity at which they
|
||||
repeat.
|
||||
|
||||
| Starts at | Log level | Log periodicity |
|
||||
| :-------------------- | :-------- | :-------------- |
|
||||
| 1 month before expiry | Warn | 1 msg per hour |
|
||||
| 1 week before expiry | Warn | 1 msg per 5 min |
|
||||
| At expiry | Error | 1 msg per 5 min |
|
||||
|
||||
#### Query brownout
|
||||
|
||||
Starting one month after your contractual license expiry, the InfluxDB
|
||||
[Querier](/influxdb/clustered/reference/internals/storage-engine/#querier)
|
||||
begins "browning out" requests. Brownouts return
|
||||
`FailedPrecondition` response codes to queries for a portion of every hour.
|
||||
|
||||
| Starts at | Brownout coverage |
|
||||
| :------------------- | :----------------- |
|
||||
| 7 days after expiry | 5 minutes per hour |
|
||||
| 1 month after expiry | 100% of queries |
|
||||
|
||||
**Brownouts only occur after the license has contractually expired**.
|
||||
Also, they **only impact query operations**--no other operations (writes,
|
||||
compaction, garbage collection, etc) are affected.
|
||||
|
|
@ -0,0 +1,354 @@
|
|||
---
|
||||
title: Scale your InfluxDB cluster
|
||||
description: >
|
||||
InfluxDB Clustered lets you scale individual components of your cluster both
|
||||
vertically and horizontally to match your specific workload.
|
||||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
name: Scale your cluster
|
||||
weight: 207
|
||||
influxdb/clustered/tags: [scale]
|
||||
related:
|
||||
- /influxdb/clustered/reference/internals/storage-engine/
|
||||
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#requests-and-limits, Kubernetes resource requests and limits
|
||||
---
|
||||
|
||||
InfluxDB Clustered lets you scale individual components of your cluster both
|
||||
vertically and horizontally to match your specific workload.
|
||||
Use the `AppInstance` resource defined in your `influxdb.yml` to manage
|
||||
resources available to each component.
|
||||
|
||||
- [Scaling strategies](#scaling-strategies)
|
||||
- [Vertical scaling](#vertical-scaling)
|
||||
- [Horizontal scaling](#horizontal-scaling)
|
||||
- [Scale components in your cluster](#scale-components-in-your-cluster)
|
||||
- [Horizontally scale a component](#horizontally-scale-a-component)
|
||||
- [Vertically scale a component](#vertically-scale-a-component)
|
||||
- [Apply your changes](#apply-your-changes)
|
||||
- [Scale your cluster as a whole](#scale-your-cluster-as-a-whole)
|
||||
- [Recommended scaling strategies per component](#recommended-scaling-strategies-per-component)
|
||||
- [Ingester](#ingester)
|
||||
- [Querier](#querier)
|
||||
- [Router](#router)
|
||||
- [Compactor](#compactor)
|
||||
- [Catalog](#catalog)
|
||||
- [Object store](#object-store)
|
||||
|
||||
## Scaling strategies
|
||||
|
||||
The following scaling strategies can be applied to components in your InfluxDB
|
||||
cluster.
|
||||
|
||||
### Vertical scaling
|
||||
|
||||
Vertical scaling (also known as "scaling up") involves increasing the resources
|
||||
(such as RAM or CPU) available to a process or system.
|
||||
Vertical scaling is typically used to handle resource-intensive tasks that
|
||||
require more processing power.
|
||||
|
||||
{{< html-diagram/scaling-strategy "vertical" >}}
|
||||
|
||||
### Horizontal scaling
|
||||
|
||||
Horizontal scaling (also known as "scaling out") involves increasing the number of
|
||||
nodes or processes available to perform a given task.
|
||||
Horizontal scaling is typically used to increase the amount of workload or
|
||||
throughput a system can manage, but also provides additional redundancy and failover.
|
||||
|
||||
{{< html-diagram/scaling-strategy "horizontal" >}}
|
||||
|
||||
## Scale components in your cluster
|
||||
|
||||
The following components of your InfluxDB cluster are scaled by modifying
|
||||
properties in your `AppInstance` resource:
|
||||
|
||||
- Ingester
|
||||
- Querier
|
||||
- Compactor
|
||||
- Router
|
||||
|
||||
{{% note %}}
|
||||
#### Scale your Catalog and Object store
|
||||
|
||||
Your InfluxDB [Catalog](/influxdb/clustered/reference/internals/storage-engine/#catalog)
|
||||
and [Object store](/influxdb/clustered/reference/internals/storage-engine/#object-store)
|
||||
are managed outside of your `AppInstance` resource. Scaling mechanisms for these
|
||||
components depend on the technology and underlying provider used for each.
|
||||
{{% /note %}}
|
||||
|
||||
Use the `spec.package.spec.resources` property in your `AppInstance` resource
|
||||
defined in your `influxdb.yml` to define system resource minimums and limits
|
||||
for each pod and the number of replicas per component.
|
||||
`requests` are the minimum that the Kubernetes scheduler should reserve for a pod.
|
||||
`limits` are the maximum that a pod should be allowed to use.
|
||||
|
||||
Your `AppInstance` resource can include the following properties to define
|
||||
resource minimums and limits per pod and replicas per component:
|
||||
|
||||
- `spec.package.spec.resources`
|
||||
- `ingester`
|
||||
- `requests`
|
||||
- `cpu`: Minimum CPU resource units to assign to ingesters
|
||||
- `memory`: Minimum memory resource units to assign to ingesters
|
||||
- `replicas`: Number of ingester replicas to provision
|
||||
- `limits`
|
||||
- `cpu`: Maximum CPU resource units to assign to ingesters
|
||||
- `memory`: Maximum memory resource units to assign to ingesters
|
||||
- `compactor`
|
||||
- `requests`
|
||||
- `cpu`: Minimum CPU resource units to assign to compactors
|
||||
- `memory`: Minimum memory resource units to assign to compactors
|
||||
- `replicas`: Number of compactor replicas to provision
|
||||
- `limits`
|
||||
- `cpu`: Maximum CPU resource units to assign to compactors
|
||||
- `memory`: Maximum memory resource units to assign to compactors
|
||||
- `querier`
|
||||
- `requests`
|
||||
- `cpu`: Minimum CPU resource units to assign to queriers
|
||||
- `memory`: Minimum memory resource units to assign to queriers
|
||||
- `replicas`: Number of querier replicas to provision
|
||||
- `limits`
|
||||
- `cpu`: Maximum CPU resource units to assign to queriers
|
||||
- `memory`: Maximum memory resource units to assign to queriers
|
||||
- `router`
|
||||
- `requests`
|
||||
- `cpu`: Minimum CPU resource units to assign to routers
|
||||
- `memory`: Minimum memory resource units to assign to routers
|
||||
- `replicas`: Number of router replicas to provision
|
||||
- `limits`
|
||||
- `cpu`: Maximum CPU Resource units to assign to routers
|
||||
- `memory`: Maximum memory resource units to assign to routers
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "View example `AppInstance` with resource requests and limits" %}}
|
||||
|
||||
{{% code-placeholders "(INGESTER|COMPACTOR|QUERIER|ROUTER)_(CPU_(MAX|MIN)|MEMORY_(MAX|MIN)|REPLICAS)" %}}
|
||||
|
||||
```yml
|
||||
apiVersion: kubecfg.dev/v1alpha1
|
||||
kind: AppInstance
|
||||
# ...
|
||||
spec:
|
||||
package:
|
||||
spec:
|
||||
# The following settings tune the various pods for their cpu/memory/replicas
|
||||
# based on workload needs. Only uncomment the specific resources you want
|
||||
# to change. Anything left commented will use the package default.
|
||||
resources:
|
||||
ingester:
|
||||
requests:
|
||||
cpu: INGESTER_CPU_MIN
|
||||
memory: INGESTER_MEMORY_MIN
|
||||
replicas: INGESTER_REPLICAS # Default is 3
|
||||
limits:
|
||||
cpu: INGESTER_CPU_MAX
|
||||
memory: INGESTER_MEMORY_MAX
|
||||
compactor:
|
||||
requests:
|
||||
cpu: COMPACTOR_CPU_MIN
|
||||
memory: COMPACTOR_MEMORY_MIN
|
||||
replicas: COMPACTOR_REPLICAS # Default is 1
|
||||
limits:
|
||||
cpu: COMPACTOR_CPU_MAX
|
||||
memory: COMPACTOR_MEMORY_MAX
|
||||
querier:
|
||||
requests:
|
||||
cpu: QUERIER_CPU_MIN
|
||||
memory: QUERIER_MEMORY_MIN
|
||||
replicas: QUERIER_REPLICAS # Default is 1
|
||||
limits:
|
||||
cpu: QUERIER_CPU_MAX
|
||||
memory: QUERIER_MEMORY_MAX
|
||||
router:
|
||||
requests:
|
||||
cpu: ROUTER_CPU_MIN
|
||||
memory: ROUTER_MEMORY_MIN
|
||||
replicas: ROUTER_REPLICAS # Default is 1
|
||||
limits:
|
||||
cpu: ROUTER_CPU_MAX
|
||||
memory: ROUTER_MEMORY_MAX
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
{{% /expand %}}
|
||||
{{< /expand-wrapper >}}
|
||||
|
||||
{{% note %}}
|
||||
Applying resource limits to pods is optional, but provides better resource
|
||||
isolation and protects against pods using more resources than intended. For
|
||||
information, see [Kubernetes resource requests and limits](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#requests-and-limits).
|
||||
{{% /note %}}
|
||||
|
||||
##### Related Kubernetes documentation
|
||||
|
||||
- [CPU resource units](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu)
|
||||
- [Memory resource units](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-memory)
|
||||
|
||||
### Horizontally scale a component
|
||||
|
||||
To horizontally scale a component in your InfluxDB cluster, increase or decrease
|
||||
the number of replicas for the component in the `spec.package.spec.resources`
|
||||
property in your `AppInstance` resource and [apply the change](#apply-your-changes).
|
||||
|
||||
{{% warn %}}
|
||||
#### Only use the AppInstance to scale component replicas
|
||||
|
||||
Only use the `AppInstance` resource to scale component replicas.
|
||||
Manually scaling replicas may cause errors.
|
||||
{{% /warn %}}
|
||||
|
||||
For example--to horizontally scale your
|
||||
[Ingester](/influxdb/clustered/reference/internals/storage-engine/#ingester):
|
||||
|
||||
```yaml
|
||||
apiVersion: kubecfg.dev/v1alpha1
|
||||
kind: AppInstance
|
||||
# ...
|
||||
spec:
|
||||
package:
|
||||
spec:
|
||||
resources:
|
||||
ingester:
|
||||
requests:
|
||||
# ...
|
||||
replicas: 6
|
||||
```
|
||||
|
||||
### Vertically scale a component
|
||||
|
||||
To vertically scale a component in your InfluxDB cluster, increase or decrease
|
||||
the CPU and memory resource units to assign to component pods in the
|
||||
`spec.package.spec.resources` property in your `AppInstance` resource and
|
||||
[apply the change](#apply-your-changes).
|
||||
|
||||
```yaml
|
||||
apiVersion: kubecfg.dev/v1alpha1
|
||||
kind: AppInstance
|
||||
# ...
|
||||
spec:
|
||||
package:
|
||||
spec:
|
||||
resources:
|
||||
ingester:
|
||||
requests:
|
||||
cpu: "500m"
|
||||
memory: "512MiB"
|
||||
# ...
|
||||
limits:
|
||||
cpu: "1000m"
|
||||
memory: "1024MiB"
|
||||
```
|
||||
|
||||
### Apply your changes
|
||||
|
||||
After modifying the `AppInstance` resource, use `kubectl apply` to apply the
|
||||
configuration changes to your cluster and scale the updated components.
|
||||
|
||||
```sh
|
||||
kubectl apply \
|
||||
--filename myinfluxdb.yml \
|
||||
--namespace influxdb
|
||||
```
|
||||
|
||||
## Scale your cluster as a whole
|
||||
|
||||
Scaling your entire InfluxDB Cluster is done by scaling your Kubernetes cluster
|
||||
and is managed outside of InfluxDB. The process of scaling your entire Kubernetes
|
||||
cluster depends on your underlying Kubernetes provider. You can also use
|
||||
[Kubernetes autoscaling](https://kubernetes.io/docs/concepts/cluster-administration/cluster-autoscaling/)
|
||||
to automatically scale your cluster as needed.
|
||||
|
||||
## Recommended scaling strategies per component
|
||||
|
||||
- [Router](#router)
|
||||
- [Ingester](#ingester)
|
||||
- [Querier](#querier)
|
||||
- [Compactor](#compactor)
|
||||
- [Catalog](#catalog)
|
||||
- [Object store](#object-store)
|
||||
|
||||
### Router
|
||||
|
||||
The Router can be scaled both [vertically](#vertical-scaling) and
|
||||
[horizontally](#horizontal-scaling).
|
||||
Horizontal scaling increases write throughput and is typically the most
|
||||
effective scaling strategy for the Router.
|
||||
Vertical scaling (specifically increased CPU) improves the Router's ability to
|
||||
parse incoming line protocol with lower latency.
|
||||
|
||||
### Ingester
|
||||
|
||||
The Ingester can be scaled both [vertically](#vertical-scaling) and
|
||||
[horizontally](#horizontal-scaling).
|
||||
Vertical scaling increases write throughput and is typically the most effective
|
||||
scaling strategy for the Ingester.
|
||||
|
||||
#### Ingester storage volume
|
||||
|
||||
Ingesters use an attached storage volume to store the
|
||||
[Write-Ahead Log (WAL)](/influxdb/clustered/reference/glossary/#wal-write-ahead-log).
|
||||
With more storage available, Ingesters can keep bigger WAL buffers, which
|
||||
improves query performance and reduces pressure on the Compactor.
|
||||
Storage speed also helps with query performance.
|
||||
|
||||
Configure the storage volume attached to Ingester pods in the
|
||||
`spec.package.spec.ingesterStorage` property of your `AppInstance` resource.
|
||||
|
||||
{{< expand-wrapper >}}
|
||||
{{% expand "View example Ingester storage configuration" %}}
|
||||
|
||||
{{% code-placeholders "STORAGE_(CLASS|SIZE)" %}}
|
||||
|
||||
```yml
|
||||
apiVersion: kubecfg.dev/v1alpha1
|
||||
kind: AppInstance
|
||||
# ...
|
||||
spec:
|
||||
package:
|
||||
spec:
|
||||
# ...
|
||||
ingesterStorage:
|
||||
# (Optional) Set the storage class. This will differ based on the K8s
|
||||
#environment and desired storage characteristics.
|
||||
# If not set, the default storage class is used.
|
||||
storageClassName: STORAGE_CLASS
|
||||
# Set the storage size (minimum 2Gi recommended)
|
||||
storage: STORAGE_SIZE
|
||||
```
|
||||
|
||||
{{% /code-placeholders %}}
|
||||
|
||||
{{% /expand %}}
|
||||
{{< /expand-wrapper >}}
|
||||
|
||||
### Querier
|
||||
|
||||
The Querier can be scaled both [vertically](#vertical-scaling) and
|
||||
[horizontally](#horizontal-scaling).
|
||||
Horizontal scaling increases query throughput to handle more concurrent queries.
|
||||
Vertical scaling improves the Querier’s ability to process computationally
|
||||
intensive queries.
|
||||
|
||||
### Compactor
|
||||
|
||||
The Compactor can be scaled both [vertically](#vertical-scaling) and
|
||||
[horizontally](#horizontal-scaling).
|
||||
Because compaction is a compute-heavy process, vertical scaling (especially
|
||||
increasing the available CPU) is the most effective scaling strategy for the
|
||||
Compactor. Horizontal scaling increases compaction throughput, but not as
|
||||
efficiently as vertical scaling.
|
||||
|
||||
### Catalog
|
||||
|
||||
Scaling strategies available for the Catalog depend on the PostgreSQL-compatible
|
||||
database used to run the catalog. All support [vertical scaling](#vertical-scaling).
|
||||
Most support [horizontal scaling](#horizontal-scaling) for redundancy and failover.
|
||||
|
||||
### Object store
|
||||
|
||||
Scaling strategies available for the Object store depend on the underlying
|
||||
object storage services used to run the object store. Most support
|
||||
[horizontal scaling](#horizontal-scaling) for redundancy, failover, and
|
||||
increased capacity.
|
||||
|
|
@ -8,7 +8,7 @@ description: >
|
|||
menu:
|
||||
influxdb_clustered:
|
||||
parent: Administer InfluxDB Clustered
|
||||
weight: 101
|
||||
weight: 103
|
||||
influxdb/clustered/tags: [tables]
|
||||
---
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue