mirror of https://github.com/ARMmbed/mbed-os.git
Squashed 'littlefs/' changes from 9843402..454b588
454b588 Updated SPEC.md and DESIGN.md based on recent changes f3578e3 Removed clamping to block size in ctz linked-list 83d4c61 Updated copyright 539409e Refactored deduplicate/deorphan step to single deorphan step 2936514 Added atomic move using dirty tag in entry type ac9766e Added self-hosting fuzz test using littlefs-fuse 9db1a86 Added specification document git-subtree-dir: littlefs git-subtree-split: 454b588f73032f9621c264fba280ab7b3a216402pull/6179/head
parent
6e99fa9319
commit
3c3b0329d4
30
.travis.yml
30
.travis.yml
|
|
@ -16,3 +16,33 @@ script:
|
|||
- CFLAGS="-DLFS_READ_SIZE=512 -DLFS_PROG_SIZE=512" make test
|
||||
- CFLAGS="-DLFS_BLOCK_COUNT=1023" make test
|
||||
- CFLAGS="-DLFS_LOOKAHEAD=2047" make test
|
||||
|
||||
# self-host with littlefs-fuse for fuzz test
|
||||
- make -C littlefs-fuse
|
||||
|
||||
- littlefs-fuse/lfs --format /dev/loop0
|
||||
- littlefs-fuse/lfs /dev/loop0 mount
|
||||
|
||||
- ls mount
|
||||
- mkdir mount/littlefs
|
||||
- cp -r $(git ls-tree --name-only HEAD) mount/littlefs
|
||||
- cd mount/littlefs
|
||||
- ls
|
||||
- make -B test_dirs
|
||||
|
||||
before_install:
|
||||
- fusermount -V
|
||||
- gcc --version
|
||||
|
||||
install:
|
||||
- sudo apt-get install libfuse-dev
|
||||
- git clone --depth 1 https://github.com/geky/littlefs-fuse
|
||||
|
||||
before_script:
|
||||
- rm -rf littlefs-fuse/littlefs/*
|
||||
- cp -r $(git ls-tree --name-only HEAD) littlefs-fuse/littlefs
|
||||
|
||||
- mkdir mount
|
||||
- sudo chmod a+rw /dev/loop0
|
||||
- dd if=/dev/zero bs=512 count=2048 of=disk
|
||||
- losetup /dev/loop0 disk
|
||||
|
|
|
|||
250
DESIGN.md
250
DESIGN.md
|
|
@ -200,7 +200,7 @@ Now we could just leave files here, copying the entire file on write
|
|||
provides the synchronization without the duplicated memory requirements
|
||||
of the metadata blocks. However, we can do a bit better.
|
||||
|
||||
## CTZ linked-lists
|
||||
## CTZ skip-lists
|
||||
|
||||
There are many different data structures for representing the actual
|
||||
files in filesystems. Of these, the littlefs uses a rather unique [COW](https://upload.wikimedia.org/wikipedia/commons/0/0c/Cow_female_black_white.jpg)
|
||||
|
|
@ -246,19 +246,19 @@ runtime to just _read_ a file? That's awful. Keep in mind reading files are
|
|||
usually the most common filesystem operation.
|
||||
|
||||
To avoid this problem, the littlefs uses a multilayered linked-list. For
|
||||
every block that is divisible by a power of two, the block contains an
|
||||
additional pointer that points back by that power of two. Another way of
|
||||
thinking about this design is that there are actually many linked-lists
|
||||
threaded together, with each linked-lists skipping an increasing number
|
||||
of blocks. If you're familiar with data-structures, you may have also
|
||||
recognized that this is a deterministic skip-list.
|
||||
every nth block where n is divisible by 2^x, the block contains a pointer
|
||||
to block n-2^x. So each block contains anywhere from 1 to log2(n) pointers
|
||||
that skip to various sections of the preceding list. If you're familiar with
|
||||
data-structures, you may have recognized that this is a type of deterministic
|
||||
skip-list.
|
||||
|
||||
To find the power of two factors efficiently, we can use the instruction
|
||||
[count trailing zeros (CTZ)](https://en.wikipedia.org/wiki/Count_trailing_zeros),
|
||||
which is where this linked-list's name comes from.
|
||||
The name comes from the use of the
|
||||
[count trailing zeros (CTZ)](https://en.wikipedia.org/wiki/Count_trailing_zeros)
|
||||
instruction, which allows us to calculate the power-of-two factors efficiently.
|
||||
For a given block n, the block contains ctz(n)+1 pointers.
|
||||
|
||||
```
|
||||
Exhibit C: A backwards CTZ linked-list
|
||||
Exhibit C: A backwards CTZ skip-list
|
||||
.--------. .--------. .--------. .--------. .--------. .--------.
|
||||
| data 0 |<-| data 1 |<-| data 2 |<-| data 3 |<-| data 4 |<-| data 5 |
|
||||
| |<-| |--| |<-| |--| | | |
|
||||
|
|
@ -266,6 +266,9 @@ Exhibit C: A backwards CTZ linked-list
|
|||
'--------' '--------' '--------' '--------' '--------' '--------'
|
||||
```
|
||||
|
||||
The additional pointers allow us to navigate the data-structure on disk
|
||||
much more efficiently than in a single linked-list.
|
||||
|
||||
Taking exhibit C for example, here is the path from data block 5 to data
|
||||
block 1. You can see how data block 3 was completely skipped:
|
||||
```
|
||||
|
|
@ -285,15 +288,57 @@ The path to data block 0 is even more quick, requiring only two jumps:
|
|||
'--------' '--------' '--------' '--------' '--------' '--------'
|
||||
```
|
||||
|
||||
The CTZ linked-list has quite a few interesting properties. All of the pointers
|
||||
in the block can be found by just knowing the index in the list of the current
|
||||
block, and, with a bit of math, the amortized overhead for the linked-list is
|
||||
only two pointers per block. Most importantly, the CTZ linked-list has a
|
||||
worst case lookup runtime of O(logn), which brings the runtime of reading a
|
||||
file down to O(n logn). Given that the constant runtime is divided by the
|
||||
amount of data we can store in a block, this is pretty reasonable.
|
||||
We can find the runtime complexity by looking at the path to any block from
|
||||
the block containing the most pointers. Every step along the path divides
|
||||
the search space for the block in half. This gives us a runtime of O(log n).
|
||||
To get to the block with the most pointers, we can perform the same steps
|
||||
backwards, which keeps the asymptotic runtime at O(log n). The interesting
|
||||
part about this data structure is that this optimal path occurs naturally
|
||||
if we greedily choose the pointer that covers the most distance without passing
|
||||
our target block.
|
||||
|
||||
Here is what it might look like to update a file stored with a CTZ linked-list:
|
||||
So now we have a representation of files that can be appended trivially with
|
||||
a runtime of O(1), and can be read with a worst case runtime of O(n logn).
|
||||
Given that the the runtime is also divided by the amount of data we can store
|
||||
in a block, this is pretty reasonable.
|
||||
|
||||
Unfortunately, the CTZ skip-list comes with a few questions that aren't
|
||||
straightforward to answer. What is the overhead? How do we handle more
|
||||
pointers than we can store in a block?
|
||||
|
||||
One way to find the overhead per block is to look at the data structure as
|
||||
multiple layers of linked-lists. Each linked-list skips twice as many blocks
|
||||
as the previous linked-list. Or another way of looking at it is that each
|
||||
linked-list uses half as much storage per block as the previous linked-list.
|
||||
As we approach infinity, the number of pointers per block forms a geometric
|
||||
series. Solving this geometric series gives us an average of only 2 pointers
|
||||
per block.
|
||||
|
||||
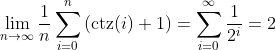
|
||||
|
||||
Finding the maximum number of pointers in a block is a bit more complicated,
|
||||
but since our file size is limited by the integer width we use to store the
|
||||
size, we can solve for it. Setting the overhead of the maximum pointers equal
|
||||
to the block size we get the following equation. Note that a smaller block size
|
||||
results in more pointers, and a larger word width results in larger pointers.
|
||||
|
||||
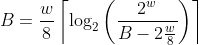
|
||||
|
||||
where:
|
||||
B = block size in bytes
|
||||
w = word width in bits
|
||||
|
||||
Solving the equation for B gives us the minimum block size for various word
|
||||
widths:
|
||||
32 bit CTZ skip-list = minimum block size of 104 bytes
|
||||
64 bit CTZ skip-list = minimum block size of 448 bytes
|
||||
|
||||
Since littlefs uses a 32 bit word size, we are limited to a minimum block
|
||||
size of 104 bytes. This is a perfectly reasonable minimum block size, with most
|
||||
block sizes starting around 512 bytes. So we can avoid the additional logic
|
||||
needed to avoid overflowing our block's capacity in the CTZ skip-list.
|
||||
|
||||
Here is what it might look like to update a file stored with a CTZ skip-list:
|
||||
```
|
||||
block 1 block 2
|
||||
.---------.---------.
|
||||
|
|
@ -367,7 +412,7 @@ v
|
|||
## Block allocation
|
||||
|
||||
So those two ideas provide the grounds for the filesystem. The metadata pairs
|
||||
give us directories, and the CTZ linked-lists give us files. But this leaves
|
||||
give us directories, and the CTZ skip-lists give us files. But this leaves
|
||||
one big [elephant](https://upload.wikimedia.org/wikipedia/commons/3/37/African_Bush_Elephant.jpg)
|
||||
of a question. How do we get those blocks in the first place?
|
||||
|
||||
|
|
@ -653,9 +698,17 @@ deorphan step that simply iterates through every directory in the linked-list
|
|||
and checks it against every directory entry in the filesystem to see if it
|
||||
has a parent. The deorphan step occurs on the first block allocation after
|
||||
boot, so orphans should never cause the littlefs to run out of storage
|
||||
prematurely.
|
||||
prematurely. Note that the deorphan step never needs to run in a readonly
|
||||
filesystem.
|
||||
|
||||
And for my final trick, moving a directory:
|
||||
## The move problem
|
||||
|
||||
Now we have a real problem. How do we move things between directories while
|
||||
remaining power resilient? Even looking at the problem from a high level,
|
||||
it seems impossible. We can update directory blocks atomically, but atomically
|
||||
updating two independent directory blocks is not an atomic operation.
|
||||
|
||||
Here's the steps the filesystem may go through to move a directory:
|
||||
```
|
||||
.--------.
|
||||
|root dir|-.
|
||||
|
|
@ -716,18 +769,135 @@ v
|
|||
'--------'
|
||||
```
|
||||
|
||||
Note that once again we don't care about the ordering of directories in the
|
||||
linked-list, so we can simply leave directories in their old positions. This
|
||||
does make the diagrams a bit hard to draw, but the littlefs doesn't really
|
||||
care.
|
||||
We can leave any orphans up to the deorphan step to collect, but that doesn't
|
||||
help the case where dir A has both dir B and the root dir as parents if we
|
||||
lose power inconveniently.
|
||||
|
||||
It's also worth noting that once again we have an operation that isn't actually
|
||||
atomic. After we add directory A to directory B, we could lose power, leaving
|
||||
directory A as a part of both the root directory and directory B. However,
|
||||
there isn't anything inherent to the littlefs that prevents a directory from
|
||||
having multiple parents, so in this case, we just allow that to happen. Extra
|
||||
care is taken to only remove a directory from the linked-list if there are
|
||||
no parents left in the filesystem.
|
||||
Initially, you might think this is fine. Dir A _might_ end up with two parents,
|
||||
but the filesystem will still work as intended. But then this raises the
|
||||
question of what do we do when the dir A wears out? For other directory blocks
|
||||
we can update the parent pointer, but for a dir with two parents we would need
|
||||
work out how to update both parents. And the check for multiple parents would
|
||||
need to be carried out for every directory, even if the directory has never
|
||||
been moved.
|
||||
|
||||
It also presents a bad user-experience, since the condition of ending up with
|
||||
two parents is rare, it's unlikely user-level code will be prepared. Just think
|
||||
about how a user would recover from a multi-parented directory. They can't just
|
||||
remove one directory, since remove would report the directory as "not empty".
|
||||
|
||||
Other atomic filesystems simple COW the entire directory tree. But this
|
||||
introduces a significant bit of complexity, which leads to code size, along
|
||||
with a surprisingly expensive runtime cost during what most users assume is
|
||||
a single pointer update.
|
||||
|
||||
Another option is to update the directory block we're moving from to point
|
||||
to the destination with a sort of predicate that we have moved if the
|
||||
destination exists. Unfortunately, the omnipresent concern of wear could
|
||||
cause any of these directory entries to change blocks, and changing the
|
||||
entry size before a move introduces complications if it spills out of
|
||||
the current directory block.
|
||||
|
||||
So how do we go about moving a directory atomically?
|
||||
|
||||
We rely on the improbableness of power loss.
|
||||
|
||||
Power loss during a move is certainly possible, but it's actually relatively
|
||||
rare. Unless a device is writing to a filesystem constantly, it's unlikely that
|
||||
a power loss will occur during filesystem activity. We still need to handle
|
||||
the condition, but runtime during a power loss takes a back seat to the runtime
|
||||
during normal operations.
|
||||
|
||||
So what littlefs does is unelegantly simple. When littlefs moves a file, it
|
||||
marks the file as "moving". This is stored as a single bit in the directory
|
||||
entry and doesn't take up much space. Then littlefs moves the directory,
|
||||
finishing with the complete remove of the "moving" directory entry.
|
||||
|
||||
```
|
||||
.--------.
|
||||
|root dir|-.
|
||||
| pair 0 | |
|
||||
.--------| |-'
|
||||
| '--------'
|
||||
| .-' '-.
|
||||
| v v
|
||||
| .--------. .--------.
|
||||
'->| dir A |->| dir B |
|
||||
| pair 0 | | pair 0 |
|
||||
| | | |
|
||||
'--------' '--------'
|
||||
|
||||
| update root directory to mark directory A as moving
|
||||
v
|
||||
|
||||
.----------.
|
||||
|root dir |-.
|
||||
| pair 0 | |
|
||||
.-------| moving A!|-'
|
||||
| '----------'
|
||||
| .-' '-.
|
||||
| v v
|
||||
| .--------. .--------.
|
||||
'->| dir A |->| dir B |
|
||||
| pair 0 | | pair 0 |
|
||||
| | | |
|
||||
'--------' '--------'
|
||||
|
||||
| update directory B to point to directory A
|
||||
v
|
||||
|
||||
.----------.
|
||||
|root dir |-.
|
||||
| pair 0 | |
|
||||
.-------| moving A!|-'
|
||||
| '----------'
|
||||
| .-----' '-.
|
||||
| | v
|
||||
| | .--------.
|
||||
| | .->| dir B |
|
||||
| | | | pair 0 |
|
||||
| | | | |
|
||||
| | | '--------'
|
||||
| | .-------'
|
||||
| v v |
|
||||
| .--------. |
|
||||
'->| dir A |-'
|
||||
| pair 0 |
|
||||
| |
|
||||
'--------'
|
||||
|
||||
| update root to no longer contain directory A
|
||||
v
|
||||
.--------.
|
||||
|root dir|-.
|
||||
| pair 0 | |
|
||||
.----| |-'
|
||||
| '--------'
|
||||
| |
|
||||
| v
|
||||
| .--------.
|
||||
| .->| dir B |
|
||||
| | | pair 0 |
|
||||
| '--| |-.
|
||||
| '--------' |
|
||||
| | |
|
||||
| v |
|
||||
| .--------. |
|
||||
'--->| dir A |-'
|
||||
| pair 0 |
|
||||
| |
|
||||
'--------'
|
||||
```
|
||||
|
||||
Now, if we run into a directory entry that has been marked as "moved", one
|
||||
of two things is possible. Either the directory entry exists elsewhere in the
|
||||
filesystem, or it doesn't. This is a O(n) operation, but only occurs in the
|
||||
unlikely case we lost power during a move.
|
||||
|
||||
And we can easily fix the "moved" directory entry. Since we're already scanning
|
||||
the filesystem during the deorphan step, we can also check for moved entries.
|
||||
If we find one, we either remove the "moved" marking or remove the whole entry
|
||||
if it exists elsewhere in the filesystem.
|
||||
|
||||
## Wear awareness
|
||||
|
||||
|
|
@ -955,18 +1125,18 @@ So, to summarize:
|
|||
|
||||
1. The littlefs is composed of directory blocks
|
||||
2. Each directory is a linked-list of metadata pairs
|
||||
3. These metadata pairs can be updated atomically by alternative which
|
||||
3. These metadata pairs can be updated atomically by alternating which
|
||||
metadata block is active
|
||||
4. Directory blocks contain either references to other directories or files
|
||||
5. Files are represented by copy-on-write CTZ linked-lists
|
||||
6. The CTZ linked-lists support appending in O(1) and reading in O(n logn)
|
||||
7. Blocks are allocated by scanning the filesystem for used blocks in a
|
||||
5. Files are represented by copy-on-write CTZ skip-lists which support O(1)
|
||||
append and O(n logn) reading
|
||||
6. Blocks are allocated by scanning the filesystem for used blocks in a
|
||||
fixed-size lookahead region is that stored in a bit-vector
|
||||
8. To facilitate scanning the filesystem, all directories are part of a
|
||||
7. To facilitate scanning the filesystem, all directories are part of a
|
||||
linked-list that is threaded through the entire filesystem
|
||||
9. If a block develops an error, the littlefs allocates a new block, and
|
||||
8. If a block develops an error, the littlefs allocates a new block, and
|
||||
moves the data and references of the old block to the new.
|
||||
10. Any case where an atomic operation is not possible, it is taken care of
|
||||
9. Any case where an atomic operation is not possible, mistakes are resolved
|
||||
by a deorphan step that occurs on the first allocation after boot
|
||||
|
||||
That's the little filesystem. Thanks for reading!
|
||||
|
|
|
|||
2
Makefile
2
Makefile
|
|
@ -32,7 +32,7 @@ size: $(OBJ)
|
|||
|
||||
.SUFFIXES:
|
||||
test: test_format test_dirs test_files test_seek test_parallel \
|
||||
test_alloc test_paths test_orphan test_corrupt
|
||||
test_alloc test_paths test_orphan test_move test_corrupt
|
||||
test_%: tests/test_%.sh
|
||||
./$<
|
||||
|
||||
|
|
|
|||
|
|
@ -131,7 +131,8 @@ the littlefs was developed with the goal of learning more about filesystem
|
|||
design by tackling the relative unsolved problem of managing a robust
|
||||
filesystem resilient to power loss on devices with limited RAM and ROM.
|
||||
More detail on the solutions and tradeoffs incorporated into this filesystem
|
||||
can be found in [DESIGN.md](DESIGN.md).
|
||||
can be found in [DESIGN.md](DESIGN.md). The specification for the layout
|
||||
of the filesystem on disk can be found in [SPEC.md](SPEC.md).
|
||||
|
||||
## Testing
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,370 @@
|
|||
## The little filesystem technical specification
|
||||
|
||||
This is the technical specification of the little filesystem. This document
|
||||
covers the technical details of how the littlefs is stored on disk for
|
||||
introspection and tooling development. This document assumes you are
|
||||
familiar with the design of the littlefs, for more info on how littlefs
|
||||
works check out [DESIGN.md](DESIGN.md).
|
||||
|
||||
```
|
||||
| | | .---._____
|
||||
.-----. | |
|
||||
--|o |---| littlefs |
|
||||
--| |---| |
|
||||
'-----' '----------'
|
||||
| | |
|
||||
```
|
||||
|
||||
## Some important details
|
||||
|
||||
- The littlefs is a block-based filesystem. This is, the disk is divided into
|
||||
an array of evenly sized blocks that are used as the logical unit of storage
|
||||
in littlefs. Block pointers are stored in 32 bits.
|
||||
|
||||
- There is no explicit free-list stored on disk, the littlefs only knows what
|
||||
is in use in the filesystem.
|
||||
|
||||
- The littlefs uses the value of 0xffffffff to represent a null block-pointer.
|
||||
|
||||
- All values in littlefs are stored in little-endian byte order.
|
||||
|
||||
## Directories / Metadata pairs
|
||||
|
||||
Metadata pairs form the backbone of the littlefs and provide a system for
|
||||
atomic updates. Even the superblock is stored in a metadata pair.
|
||||
|
||||
As their name suggests, a metadata pair is stored in two blocks, with one block
|
||||
acting as a redundant backup in case the other is corrupted. These two blocks
|
||||
could be anywhere in the disk and may not be next to each other, so any
|
||||
pointers to directory pairs need to be stored as two block pointers.
|
||||
|
||||
Here's the layout of metadata blocks on disk:
|
||||
|
||||
| offset | size | description |
|
||||
|--------|---------------|----------------|
|
||||
| 0x00 | 32 bits | revision count |
|
||||
| 0x04 | 32 bits | dir size |
|
||||
| 0x08 | 64 bits | tail pointer |
|
||||
| 0x10 | size-16 bytes | dir entries |
|
||||
| 0x00+s | 32 bits | crc |
|
||||
|
||||
**Revision count** - Incremented every update, only the uncorrupted
|
||||
metadata-block with the most recent revision count contains the valid metadata.
|
||||
Comparison between revision counts must use sequence comparison since the
|
||||
revision counts may overflow.
|
||||
|
||||
**Dir size** - Size in bytes of the contents in the current metadata block,
|
||||
including the metadata-pair metadata. Additionally, the highest bit of the
|
||||
dir size may be set to indicate that the directory's contents continue on the
|
||||
next metadata-pair pointed to by the tail pointer.
|
||||
|
||||
**Tail pointer** - Pointer to the next metadata-pair in the filesystem.
|
||||
A null pair-pointer (0xffffffff, 0xffffffff) indicates the end of the list.
|
||||
If the highest bit in the dir size is set, this points to the next
|
||||
metadata-pair in the current directory, otherwise it points to an arbitrary
|
||||
metadata-pair. Starting with the superblock, the tail-pointers form a
|
||||
linked-list containing all metadata-pairs in the filesystem.
|
||||
|
||||
**CRC** - 32 bit CRC used to detect corruption from power-lost, from block
|
||||
end-of-life, or just from noise on the storage bus. The CRC is appended to
|
||||
the end of each metadata-block. The littlefs uses the standard CRC-32, which
|
||||
uses a polynomial of 0x04c11db7, initialized with 0xffffffff.
|
||||
|
||||
Here's an example of a simple directory stored on disk:
|
||||
```
|
||||
(32 bits) revision count = 10 (0x0000000a)
|
||||
(32 bits) dir size = 154 bytes, end of dir (0x0000009a)
|
||||
(64 bits) tail pointer = 37, 36 (0x00000025, 0x00000024)
|
||||
(32 bits) crc = 0xc86e3106
|
||||
|
||||
00000000: 0a 00 00 00 9a 00 00 00 25 00 00 00 24 00 00 00 ........%...$...
|
||||
00000010: 22 08 00 03 05 00 00 00 04 00 00 00 74 65 61 22 "...........tea"
|
||||
00000020: 08 00 06 07 00 00 00 06 00 00 00 63 6f 66 66 65 ...........coffe
|
||||
00000030: 65 22 08 00 04 09 00 00 00 08 00 00 00 73 6f 64 e"...........sod
|
||||
00000040: 61 22 08 00 05 1d 00 00 00 1c 00 00 00 6d 69 6c a"...........mil
|
||||
00000050: 6b 31 22 08 00 05 1f 00 00 00 1e 00 00 00 6d 69 k1"...........mi
|
||||
00000060: 6c 6b 32 22 08 00 05 21 00 00 00 20 00 00 00 6d lk2"...!... ...m
|
||||
00000070: 69 6c 6b 33 22 08 00 05 23 00 00 00 22 00 00 00 ilk3"...#..."...
|
||||
00000080: 6d 69 6c 6b 34 22 08 00 05 25 00 00 00 24 00 00 milk4"...%...$..
|
||||
00000090: 00 6d 69 6c 6b 35 06 31 6e c8 .milk5.1n.
|
||||
```
|
||||
|
||||
A note about the tail pointer linked-list: Normally, this linked-list is
|
||||
threaded through the entire filesystem. However, after power-loss this
|
||||
linked-list may become out of sync with the rest of the filesystem.
|
||||
- The linked-list may contain a directory that has actually been removed
|
||||
- The linked-list may contain a metadata pair that has not been updated after
|
||||
a block in the pair has gone bad.
|
||||
|
||||
The threaded linked-list must be checked for these errors before it can be
|
||||
used reliably. Fortunately, the threaded linked-list can simply be ignored
|
||||
if littlefs is mounted read-only.
|
||||
|
||||
## Entries
|
||||
|
||||
Each metadata block contains a series of entries that follow a standard
|
||||
layout. An entry contains the type of the entry, along with a section for
|
||||
entry-specific data, attributes, and a name.
|
||||
|
||||
Here's the layout of entries on disk:
|
||||
|
||||
| offset | size | description |
|
||||
|---------|------------------------|----------------------------|
|
||||
| 0x0 | 8 bits | entry type |
|
||||
| 0x1 | 8 bits | entry length |
|
||||
| 0x2 | 8 bits | attribute length |
|
||||
| 0x3 | 8 bits | name length |
|
||||
| 0x4 | entry length bytes | entry-specific data |
|
||||
| 0x4+e | attribute length bytes | system-specific attributes |
|
||||
| 0x4+e+a | name length bytes | entry name |
|
||||
|
||||
**Entry type** - Type of the entry, currently this is limited to the following:
|
||||
- 0x11 - file entry
|
||||
- 0x22 - directory entry
|
||||
- 0x2e - superblock entry
|
||||
|
||||
Additionally, the type is broken into two 4 bit nibbles, with the upper nibble
|
||||
specifying the type's data structure used when scanning the filesystem. The
|
||||
lower nibble clarifies the type further when multiple entries share the same
|
||||
data structure.
|
||||
|
||||
The highest bit is reserved for marking the entry as "moved". If an entry
|
||||
is marked as "moved", the entry may also exist somewhere else in the
|
||||
filesystem. If the entry exists elsewhere, this entry must be treated as
|
||||
though it does not exist.
|
||||
|
||||
**Entry length** - Length in bytes of the entry-specific data. This does
|
||||
not include the entry type size, attributes, or name. The full size in bytes
|
||||
of the entry is 4 + entry length + attribute length + name length.
|
||||
|
||||
**Attribute length** - Length of system-specific attributes in bytes. Since
|
||||
attributes are system specific, there is not much garuntee on the values in
|
||||
this section, and systems are expected to work even when it is empty. See the
|
||||
[attributes](#entry-attributes) section for more details.
|
||||
|
||||
**Name length** - Length of the entry name. Entry names are stored as utf8,
|
||||
although most systems will probably only support ascii. Entry names can not
|
||||
contain '/' and can not be '.' or '..' as these are a part of the syntax of
|
||||
filesystem paths.
|
||||
|
||||
Here's an example of a simple entry stored on disk:
|
||||
```
|
||||
(8 bits) entry type = file (0x11)
|
||||
(8 bits) entry length = 8 bytes (0x08)
|
||||
(8 bits) attribute length = 0 bytes (0x00)
|
||||
(8 bits) name length = 12 bytes (0x0c)
|
||||
(8 bytes) entry data = 05 00 00 00 20 00 00 00
|
||||
(12 bytes) entry name = smallavacado
|
||||
|
||||
00000000: 11 08 00 0c 05 00 00 00 20 00 00 00 73 6d 61 6c ........ ...smal
|
||||
00000010: 6c 61 76 61 63 61 64 6f lavacado
|
||||
```
|
||||
|
||||
## Superblock
|
||||
|
||||
The superblock is the anchor for the littlefs. The superblock is stored as
|
||||
a metadata pair containing a single superblock entry. It is through the
|
||||
superblock that littlefs can access the rest of the filesystem.
|
||||
|
||||
The superblock can always be found in blocks 0 and 1, however fetching the
|
||||
superblock requires knowing the block size. The block size can be guessed by
|
||||
searching the beginning of disk for the string "littlefs", although currently
|
||||
the filesystems relies on the user providing the correct block size.
|
||||
|
||||
The superblock is the most valuable block in the filesystem. It is updated
|
||||
very rarely, only during format or when the root directory must be moved. It
|
||||
is encouraged to always write out both superblock pairs even though it is not
|
||||
required.
|
||||
|
||||
Here's the layout of the superblock entry:
|
||||
|
||||
| offset | size | description |
|
||||
|--------|------------------------|----------------------------------------|
|
||||
| 0x00 | 8 bits | entry type (0x2e for superblock entry) |
|
||||
| 0x01 | 8 bits | entry length (20 bytes) |
|
||||
| 0x02 | 8 bits | attribute length |
|
||||
| 0x03 | 8 bits | name length (8 bytes) |
|
||||
| 0x04 | 64 bits | root directory |
|
||||
| 0x0c | 32 bits | block size |
|
||||
| 0x10 | 32 bits | block count |
|
||||
| 0x14 | 32 bits | version |
|
||||
| 0x18 | attribute length bytes | system-specific attributes |
|
||||
| 0x18+a | 8 bytes | magic string ("littlefs") |
|
||||
|
||||
**Root directory** - Pointer to the root directory's metadata pair.
|
||||
|
||||
**Block size** - Size of the logical block size used by the filesystem.
|
||||
|
||||
**Block count** - Number of blocks in the filesystem.
|
||||
|
||||
**Version** - The littlefs version encoded as a 32 bit value. The upper 16 bits
|
||||
encodes the major version, which is incremented when a breaking-change is
|
||||
introduced in the filesystem specification. The lower 16 bits encodes the
|
||||
minor version, which is incremented when a backwards-compatible change is
|
||||
introduced. Non-standard Attribute changes do not change the version. This
|
||||
specification describes version 1.1 (0x00010001), which is the first version
|
||||
of littlefs.
|
||||
|
||||
**Magic string** - The magic string "littlefs" takes the place of an entry
|
||||
name.
|
||||
|
||||
Here's an example of a complete superblock:
|
||||
```
|
||||
(32 bits) revision count = 3 (0x00000003)
|
||||
(32 bits) dir size = 52 bytes, end of dir (0x00000034)
|
||||
(64 bits) tail pointer = 3, 2 (0x00000003, 0x00000002)
|
||||
(8 bits) entry type = superblock (0x2e)
|
||||
(8 bits) entry length = 20 bytes (0x14)
|
||||
(8 bits) attribute length = 0 bytes (0x00)
|
||||
(8 bits) name length = 8 bytes (0x08)
|
||||
(64 bits) root directory = 3, 2 (0x00000003, 0x00000002)
|
||||
(32 bits) block size = 512 bytes (0x00000200)
|
||||
(32 bits) block count = 1024 blocks (0x00000400)
|
||||
(32 bits) version = 1.1 (0x00010001)
|
||||
(8 bytes) magic string = littlefs
|
||||
(32 bits) crc = 0xc50b74fa
|
||||
|
||||
00000000: 03 00 00 00 34 00 00 00 03 00 00 00 02 00 00 00 ....4...........
|
||||
00000010: 2e 14 00 08 03 00 00 00 02 00 00 00 00 02 00 00 ................
|
||||
00000020: 00 04 00 00 01 00 01 00 6c 69 74 74 6c 65 66 73 ........littlefs
|
||||
00000030: fa 74 0b c5 .t..
|
||||
```
|
||||
|
||||
## Directory entries
|
||||
|
||||
Directories are stored in entries with a pointer to the first metadata pair
|
||||
in the directory. Keep in mind that a directory may be composed of multiple
|
||||
metadata pairs connected by the tail pointer when the highest bit in the dir
|
||||
size is set.
|
||||
|
||||
Here's the layout of a directory entry:
|
||||
|
||||
| offset | size | description |
|
||||
|--------|------------------------|-----------------------------------------|
|
||||
| 0x0 | 8 bits | entry type (0x22 for directory entries) |
|
||||
| 0x1 | 8 bits | entry length (8 bytes) |
|
||||
| 0x2 | 8 bits | attribute length |
|
||||
| 0x3 | 8 bits | name length |
|
||||
| 0x4 | 64 bits | directory pointer |
|
||||
| 0xc | attribute length bytes | system-specific attributes |
|
||||
| 0xc+a | name length bytes | directory name |
|
||||
|
||||
**Directory pointer** - Pointer to the first metadata pair in the directory.
|
||||
|
||||
Here's an example of a directory entry:
|
||||
```
|
||||
(8 bits) entry type = directory (0x22)
|
||||
(8 bits) entry length = 8 bytes (0x08)
|
||||
(8 bits) attribute length = 0 bytes (0x00)
|
||||
(8 bits) name length = 3 bytes (0x03)
|
||||
(64 bits) directory pointer = 5, 4 (0x00000005, 0x00000004)
|
||||
(3 bytes) name = tea
|
||||
|
||||
00000000: 22 08 00 03 05 00 00 00 04 00 00 00 74 65 61 "...........tea
|
||||
```
|
||||
|
||||
## File entries
|
||||
|
||||
Files are stored in entries with a pointer to the head of the file and the
|
||||
size of the file. This is enough information to determine the state of the
|
||||
CTZ skip-list that is being referenced.
|
||||
|
||||
How files are actually stored on disk is a bit complicated. The full
|
||||
explanation of CTZ skip-lists can be found in [DESIGN.md](DESIGN.md#ctz-skip-lists).
|
||||
|
||||
A terribly quick summary: For every nth block where n is divisible by 2^x,
|
||||
the block contains a pointer to block n-2^x. These pointers are stored in
|
||||
increasing order of x in each block of the file preceding the data in the
|
||||
block.
|
||||
|
||||
The maximum number of pointers in a block is bounded by the maximum file size
|
||||
divided by the block size. With 32 bits for file size, this results in a
|
||||
minimum block size of 104 bytes.
|
||||
|
||||
Here's the layout of a file entry:
|
||||
|
||||
| offset | size | description |
|
||||
|--------|------------------------|------------------------------------|
|
||||
| 0x0 | 8 bits | entry type (0x11 for file entries) |
|
||||
| 0x1 | 8 bits | entry length (8 bytes) |
|
||||
| 0x2 | 8 bits | attribute length |
|
||||
| 0x3 | 8 bits | name length |
|
||||
| 0x4 | 32 bits | file head |
|
||||
| 0x8 | 32 bits | file size |
|
||||
| 0xc | attribute length bytes | system-specific attributes |
|
||||
| 0xc+a | name length bytes | directory name |
|
||||
|
||||
**File head** - Pointer to the block that is the head of the file's CTZ
|
||||
skip-list.
|
||||
|
||||
**File size** - Size of file in bytes.
|
||||
|
||||
Here's an example of a file entry:
|
||||
```
|
||||
(8 bits) entry type = file (0x11)
|
||||
(8 bits) entry length = 8 bytes (0x08)
|
||||
(8 bits) attribute length = 0 bytes (0x00)
|
||||
(8 bits) name length = 12 bytes (0x03)
|
||||
(32 bits) file head = 543 (0x0000021f)
|
||||
(32 bits) file size = 256 KB (0x00040000)
|
||||
(12 bytes) name = largeavacado
|
||||
|
||||
00000000: 11 08 00 0c 1f 02 00 00 00 00 04 00 6c 61 72 67 ............larg
|
||||
00000010: 65 61 76 61 63 61 64 6f eavacado
|
||||
```
|
||||
|
||||
## Entry attributes
|
||||
|
||||
Each dir entry can have up to 256 bytes of system-specific attributes. Since
|
||||
these attributes are system-specific, they may not be portable between
|
||||
different systems. For this reason, all attributes must be optional. A minimal
|
||||
littlefs driver must be able to get away with supporting no attributes at all.
|
||||
|
||||
For some level of portability, littlefs has a simple scheme for attributes.
|
||||
Each attribute is prefixes with an 8-bit type that indicates what the attribute
|
||||
is. The length of attributes may also be determined from this type. Attributes
|
||||
in an entry should be sorted based on portability, since attribute parsing
|
||||
will end when it hits the first attribute it does not understand.
|
||||
|
||||
Each system should choose a 4-bit value to prefix all attribute types with to
|
||||
avoid conflicts with other systems. Additionally, littlefs drivers that support
|
||||
attributes should provide a "ignore attributes" flag to users in case attribute
|
||||
conflicts do occur.
|
||||
|
||||
Attribute types prefixes with 0x0 and 0xf are currently reserved for future
|
||||
standard attributes. Standard attributes will be added to this document in
|
||||
that case.
|
||||
|
||||
Here's an example of non-standard time attribute:
|
||||
```
|
||||
(8 bits) attribute type = time (0xc1)
|
||||
(72 bits) time in seconds = 1506286115 (0x0059c81a23)
|
||||
|
||||
00000000: c1 23 1a c8 59 00 .#..Y.
|
||||
```
|
||||
|
||||
Here's an example of non-standard permissions attribute:
|
||||
```
|
||||
(8 bits) attribute type = permissions (0xc2)
|
||||
(16 bits) permission bits = rw-rw-r-- (0x01b4)
|
||||
|
||||
00000000: c2 b4 01 ...
|
||||
```
|
||||
|
||||
Here's what a dir entry may look like with these attributes:
|
||||
```
|
||||
(8 bits) entry type = file (0x11)
|
||||
(8 bits) entry length = 8 bytes (0x08)
|
||||
(8 bits) attribute length = 9 bytes (0x09)
|
||||
(8 bits) name length = 12 bytes (0x0c)
|
||||
(8 bytes) entry data = 05 00 00 00 20 00 00 00
|
||||
(8 bits) attribute type = time (0xc1)
|
||||
(72 bits) time in seconds = 1506286115 (0x0059c81a23)
|
||||
(8 bits) attribute type = permissions (0xc2)
|
||||
(16 bits) permission bits = rw-rw-r-- (0x01b4)
|
||||
(12 bytes) entry name = smallavacado
|
||||
|
||||
00000000: 11 08 09 0c 05 00 00 00 20 00 00 00 c1 23 1a c8 ........ ....#..
|
||||
00000010: 59 00 c2 b4 01 73 6d 61 6c 6c 61 76 61 63 61 64 Y....smallavacad
|
||||
00000020: 6f o
|
||||
```
|
||||
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* Block device emulated on standard files
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#include "emubd/lfs_emubd.h"
|
||||
|
||||
|
|
|
|||
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* Block device emulated on standard files
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#ifndef LFS_EMUBD_H
|
||||
#define LFS_EMUBD_H
|
||||
|
|
|
|||
345
lfs.c
345
lfs.c
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* The little filesystem
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#include "lfs.h"
|
||||
#include "lfs_util.h"
|
||||
|
|
@ -253,6 +264,7 @@ int lfs_traverse(lfs_t *lfs, int (*cb)(void*, lfs_block_t), void *data);
|
|||
static int lfs_pred(lfs_t *lfs, const lfs_block_t dir[2], lfs_dir_t *pdir);
|
||||
static int lfs_parent(lfs_t *lfs, const lfs_block_t dir[2],
|
||||
lfs_dir_t *parent, lfs_entry_t *entry);
|
||||
static int lfs_moved(lfs_t *lfs, const void *e);
|
||||
static int lfs_relocate(lfs_t *lfs,
|
||||
const lfs_block_t oldpair[2], const lfs_block_t newpair[2]);
|
||||
int lfs_deorphan(lfs_t *lfs);
|
||||
|
|
@ -274,14 +286,6 @@ static int lfs_alloc_lookahead(void *p, lfs_block_t block) {
|
|||
}
|
||||
|
||||
static int lfs_alloc(lfs_t *lfs, lfs_block_t *block) {
|
||||
// deorphan if we haven't yet, only needed once after poweron
|
||||
if (!lfs->deorphaned) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
|
||||
while (true) {
|
||||
while (true) {
|
||||
// check if we have looked at all blocks since last ack
|
||||
|
|
@ -438,7 +442,10 @@ struct lfs_region {
|
|||
|
||||
static int lfs_dir_commit(lfs_t *lfs, lfs_dir_t *dir,
|
||||
const struct lfs_region *regions, int count) {
|
||||
// increment revision count
|
||||
dir->d.rev += 1;
|
||||
|
||||
// keep pairs in order such that pair[0] is most recent
|
||||
lfs_pairswap(dir->pair);
|
||||
for (int i = 0; i < count; i++) {
|
||||
dir->d.size += regions[i].newlen - regions[i].oldlen;
|
||||
|
|
@ -627,8 +634,8 @@ static int lfs_dir_remove(lfs_t *lfs, lfs_dir_t *dir, lfs_entry_t *entry) {
|
|||
|
||||
if (!(pdir.d.size & 0x80000000)) {
|
||||
return lfs_dir_commit(lfs, dir, (struct lfs_region[]){
|
||||
{entry->off, lfs_entry_size(entry), NULL, 0},
|
||||
}, 1);
|
||||
{entry->off, lfs_entry_size(entry), NULL, 0},
|
||||
}, 1);
|
||||
} else {
|
||||
pdir.d.size &= dir->d.size | 0x7fffffff;
|
||||
pdir.d.tail[0] = dir->d.tail[0];
|
||||
|
|
@ -636,9 +643,26 @@ static int lfs_dir_remove(lfs_t *lfs, lfs_dir_t *dir, lfs_entry_t *entry) {
|
|||
return lfs_dir_commit(lfs, &pdir, NULL, 0);
|
||||
}
|
||||
} else {
|
||||
return lfs_dir_commit(lfs, dir, (struct lfs_region[]){
|
||||
{entry->off, lfs_entry_size(entry), NULL, 0},
|
||||
}, 1);
|
||||
int err = lfs_dir_commit(lfs, dir, (struct lfs_region[]){
|
||||
{entry->off, lfs_entry_size(entry), NULL, 0},
|
||||
}, 1);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// shift over any files that are affected
|
||||
for (lfs_file_t *f = lfs->files; f; f = f->next) {
|
||||
if (lfs_paircmp(f->pair, dir->pair) == 0) {
|
||||
if (f->poff == entry->off) {
|
||||
f->pair[0] = 0xffffffff;
|
||||
f->pair[1] = 0xffffffff;
|
||||
} else if (f->poff > entry->off) {
|
||||
f->poff -= lfs_entry_size(entry);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -722,8 +746,8 @@ static int lfs_dir_find(lfs_t *lfs, lfs_dir_t *dir,
|
|||
return err;
|
||||
}
|
||||
|
||||
if ((entry->d.type != LFS_TYPE_REG &&
|
||||
entry->d.type != LFS_TYPE_DIR) ||
|
||||
if (((0x7f & entry->d.type) != LFS_TYPE_REG &&
|
||||
(0x7f & entry->d.type) != LFS_TYPE_DIR) ||
|
||||
entry->d.nlen != pathlen) {
|
||||
continue;
|
||||
}
|
||||
|
|
@ -741,6 +765,16 @@ static int lfs_dir_find(lfs_t *lfs, lfs_dir_t *dir,
|
|||
}
|
||||
}
|
||||
|
||||
// check that entry has not been moved
|
||||
if (entry->d.type & 0x80) {
|
||||
int moved = lfs_moved(lfs, &entry->d.u);
|
||||
if (moved < 0 || moved) {
|
||||
return (moved < 0) ? moved : LFS_ERR_NOENT;
|
||||
}
|
||||
|
||||
entry->d.type &= ~0x80;
|
||||
}
|
||||
|
||||
pathname += pathlen;
|
||||
pathname += strspn(pathname, "/");
|
||||
if (pathname[0] == '\0') {
|
||||
|
|
@ -764,6 +798,14 @@ static int lfs_dir_find(lfs_t *lfs, lfs_dir_t *dir,
|
|||
|
||||
/// Top level directory operations ///
|
||||
int lfs_mkdir(lfs_t *lfs, const char *path) {
|
||||
// deorphan if we haven't yet, needed at most once after poweron
|
||||
if (!lfs->deorphaned) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
|
||||
// fetch parent directory
|
||||
lfs_dir_t cwd;
|
||||
int err = lfs_dir_fetch(lfs, &cwd, lfs->root);
|
||||
|
|
@ -880,10 +922,26 @@ int lfs_dir_read(lfs_t *lfs, lfs_dir_t *dir, struct lfs_info *info) {
|
|||
return (err == LFS_ERR_NOENT) ? 0 : err;
|
||||
}
|
||||
|
||||
if (entry.d.type == LFS_TYPE_REG ||
|
||||
entry.d.type == LFS_TYPE_DIR) {
|
||||
break;
|
||||
if ((0x7f & entry.d.type) != LFS_TYPE_REG &&
|
||||
(0x7f & entry.d.type) != LFS_TYPE_DIR) {
|
||||
continue;
|
||||
}
|
||||
|
||||
// check that entry has not been moved
|
||||
if (entry.d.type & 0x80) {
|
||||
int moved = lfs_moved(lfs, &entry.d.u);
|
||||
if (moved < 0) {
|
||||
return moved;
|
||||
}
|
||||
|
||||
if (moved) {
|
||||
continue;
|
||||
}
|
||||
|
||||
entry.d.type &= ~0x80;
|
||||
}
|
||||
|
||||
break;
|
||||
}
|
||||
|
||||
info->type = entry.d.type;
|
||||
|
|
@ -947,12 +1005,11 @@ int lfs_dir_rewind(lfs_t *lfs, lfs_dir_t *dir) {
|
|||
/// File index list operations ///
|
||||
static int lfs_index(lfs_t *lfs, lfs_off_t *off) {
|
||||
lfs_off_t i = 0;
|
||||
lfs_size_t words = lfs->cfg->block_size / 4;
|
||||
|
||||
while (*off >= lfs->cfg->block_size) {
|
||||
i += 1;
|
||||
*off -= lfs->cfg->block_size;
|
||||
*off += 4*lfs_min(lfs_ctz(i)+1, words-1);
|
||||
*off += 4*(lfs_ctz(i) + 1);
|
||||
}
|
||||
|
||||
return i;
|
||||
|
|
@ -970,12 +1027,11 @@ static int lfs_index_find(lfs_t *lfs,
|
|||
|
||||
lfs_off_t current = lfs_index(lfs, &(lfs_off_t){size-1});
|
||||
lfs_off_t target = lfs_index(lfs, &pos);
|
||||
lfs_size_t words = lfs->cfg->block_size / 4;
|
||||
|
||||
while (current > target) {
|
||||
lfs_size_t skip = lfs_min(
|
||||
lfs_npw2(current-target+1) - 1,
|
||||
lfs_min(lfs_ctz(current)+1, words-1) - 1);
|
||||
lfs_ctz(current));
|
||||
|
||||
int err = lfs_cache_read(lfs, rcache, pcache, head, 4*skip, &head, 4);
|
||||
if (err) {
|
||||
|
|
@ -1044,8 +1100,7 @@ static int lfs_index_extend(lfs_t *lfs,
|
|||
|
||||
// append block
|
||||
index += 1;
|
||||
lfs_size_t words = lfs->cfg->block_size / 4;
|
||||
lfs_size_t skips = lfs_min(lfs_ctz(index)+1, words-1);
|
||||
lfs_size_t skips = lfs_ctz(index) + 1;
|
||||
|
||||
for (lfs_off_t i = 0; i < skips; i++) {
|
||||
int err = lfs_cache_prog(lfs, pcache, rcache,
|
||||
|
|
@ -1113,6 +1168,14 @@ static int lfs_index_traverse(lfs_t *lfs,
|
|||
/// Top level file operations ///
|
||||
int lfs_file_open(lfs_t *lfs, lfs_file_t *file,
|
||||
const char *path, int flags) {
|
||||
// deorphan if we haven't yet, needed at most once after poweron
|
||||
if ((flags & 3) != LFS_O_RDONLY && !lfs->deorphaned) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
|
||||
// allocate entry for file if it doesn't exist
|
||||
lfs_dir_t cwd;
|
||||
int err = lfs_dir_fetch(lfs, &cwd, lfs->root);
|
||||
|
|
@ -1598,6 +1661,14 @@ int lfs_stat(lfs_t *lfs, const char *path, struct lfs_info *info) {
|
|||
}
|
||||
|
||||
int lfs_remove(lfs_t *lfs, const char *path) {
|
||||
// deorphan if we haven't yet, needed at most once after poweron
|
||||
if (!lfs->deorphaned) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
|
||||
lfs_dir_t cwd;
|
||||
int err = lfs_dir_fetch(lfs, &cwd, lfs->root);
|
||||
if (err) {
|
||||
|
|
@ -1629,22 +1700,18 @@ int lfs_remove(lfs_t *lfs, const char *path) {
|
|||
return err;
|
||||
}
|
||||
|
||||
// shift over any files that are affected
|
||||
for (lfs_file_t *f = lfs->files; f; f = f->next) {
|
||||
if (lfs_paircmp(f->pair, cwd.pair) == 0) {
|
||||
if (f->poff == entry.off) {
|
||||
f->pair[0] = 0xffffffff;
|
||||
f->pair[1] = 0xffffffff;
|
||||
} else if (f->poff > entry.off) {
|
||||
f->poff -= lfs_entry_size(&entry);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// if we were a directory, just run a deorphan step, this should
|
||||
// collect us, although is expensive
|
||||
// if we were a directory, find pred, replace tail
|
||||
if (entry.d.type == LFS_TYPE_DIR) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
int res = lfs_pred(lfs, dir.pair, &cwd);
|
||||
if (res < 0) {
|
||||
return res;
|
||||
}
|
||||
|
||||
assert(res); // must have pred
|
||||
cwd.d.tail[0] = dir.d.tail[0];
|
||||
cwd.d.tail[1] = dir.d.tail[1];
|
||||
|
||||
int err = lfs_dir_commit(lfs, &cwd, NULL, 0);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
|
@ -1654,6 +1721,14 @@ int lfs_remove(lfs_t *lfs, const char *path) {
|
|||
}
|
||||
|
||||
int lfs_rename(lfs_t *lfs, const char *oldpath, const char *newpath) {
|
||||
// deorphan if we haven't yet, needed at most once after poweron
|
||||
if (!lfs->deorphaned) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
|
||||
// find old entry
|
||||
lfs_dir_t oldcwd;
|
||||
int err = lfs_dir_fetch(lfs, &oldcwd, lfs->root);
|
||||
|
|
@ -1679,7 +1754,9 @@ int lfs_rename(lfs_t *lfs, const char *oldpath, const char *newpath) {
|
|||
if (err && (err != LFS_ERR_NOENT || strchr(newpath, '/') != NULL)) {
|
||||
return err;
|
||||
}
|
||||
|
||||
bool prevexists = (err != LFS_ERR_NOENT);
|
||||
bool samepair = (lfs_paircmp(oldcwd.pair, newcwd.pair) == 0);
|
||||
|
||||
// must have same type
|
||||
if (prevexists && preventry.d.type != oldentry.d.type) {
|
||||
|
|
@ -1699,9 +1776,22 @@ int lfs_rename(lfs_t *lfs, const char *oldpath, const char *newpath) {
|
|||
}
|
||||
}
|
||||
|
||||
// mark as moving
|
||||
oldentry.d.type |= 0x80;
|
||||
err = lfs_dir_update(lfs, &oldcwd, &oldentry, NULL);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// update pair if newcwd == oldcwd
|
||||
if (samepair) {
|
||||
newcwd = oldcwd;
|
||||
}
|
||||
|
||||
// move to new location
|
||||
lfs_entry_t newentry = preventry;
|
||||
newentry.d = oldentry.d;
|
||||
newentry.d.type &= ~0x80;
|
||||
newentry.d.nlen = strlen(newpath);
|
||||
|
||||
if (prevexists) {
|
||||
|
|
@ -1716,39 +1806,29 @@ int lfs_rename(lfs_t *lfs, const char *oldpath, const char *newpath) {
|
|||
}
|
||||
}
|
||||
|
||||
// fetch again in case newcwd == oldcwd
|
||||
err = lfs_dir_fetch(lfs, &oldcwd, oldcwd.pair);
|
||||
if (err) {
|
||||
return err;
|
||||
// update pair if newcwd == oldcwd
|
||||
if (samepair) {
|
||||
oldcwd = newcwd;
|
||||
}
|
||||
|
||||
err = lfs_dir_find(lfs, &oldcwd, &oldentry, &oldpath);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// remove from old location
|
||||
// remove old entry
|
||||
err = lfs_dir_remove(lfs, &oldcwd, &oldentry);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// shift over any files that are affected
|
||||
for (lfs_file_t *f = lfs->files; f; f = f->next) {
|
||||
if (lfs_paircmp(f->pair, oldcwd.pair) == 0) {
|
||||
if (f->poff == oldentry.off) {
|
||||
f->pair[0] = 0xffffffff;
|
||||
f->pair[1] = 0xffffffff;
|
||||
} else if (f->poff > oldentry.off) {
|
||||
f->poff -= lfs_entry_size(&oldentry);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// if we were a directory, just run a deorphan step, this should
|
||||
// collect us, although is expensive
|
||||
// if we were a directory, find pred, replace tail
|
||||
if (prevexists && preventry.d.type == LFS_TYPE_DIR) {
|
||||
int err = lfs_deorphan(lfs);
|
||||
int res = lfs_pred(lfs, dir.pair, &newcwd);
|
||||
if (res < 0) {
|
||||
return res;
|
||||
}
|
||||
|
||||
assert(res); // must have pred
|
||||
newcwd.d.tail[0] = dir.d.tail[0];
|
||||
newcwd.d.tail[1] = dir.d.tail[1];
|
||||
|
||||
int err = lfs_dir_commit(lfs, &newcwd, NULL, 0);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
|
@ -1797,6 +1877,10 @@ static int lfs_init(lfs_t *lfs, const struct lfs_config *cfg) {
|
|||
}
|
||||
}
|
||||
|
||||
// check that the block size is large enough to fit ctz pointers
|
||||
assert(4*lfs_npw2(0xffffffff / (lfs->cfg->block_size-2*4))
|
||||
<= lfs->cfg->block_size);
|
||||
|
||||
// setup default state
|
||||
lfs->root[0] = 0xffffffff;
|
||||
lfs->root[1] = 0xffffffff;
|
||||
|
|
@ -1917,16 +2001,22 @@ int lfs_mount(lfs_t *lfs, const struct lfs_config *cfg) {
|
|||
lfs_dir_t dir;
|
||||
lfs_superblock_t superblock;
|
||||
err = lfs_dir_fetch(lfs, &dir, (const lfs_block_t[2]){0, 1});
|
||||
if (err && err != LFS_ERR_CORRUPT) {
|
||||
return err;
|
||||
}
|
||||
|
||||
if (!err) {
|
||||
err = lfs_bd_read(lfs, dir.pair[0], sizeof(dir.d),
|
||||
int err = lfs_bd_read(lfs, dir.pair[0], sizeof(dir.d),
|
||||
&superblock.d, sizeof(superblock.d));
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
lfs->root[0] = superblock.d.root[0];
|
||||
lfs->root[1] = superblock.d.root[1];
|
||||
}
|
||||
|
||||
if (err == LFS_ERR_CORRUPT ||
|
||||
memcmp(superblock.d.magic, "littlefs", 8) != 0) {
|
||||
if (err || memcmp(superblock.d.magic, "littlefs", 8) != 0) {
|
||||
LFS_ERROR("Invalid superblock at %d %d", dir.pair[0], dir.pair[1]);
|
||||
return LFS_ERR_CORRUPT;
|
||||
}
|
||||
|
|
@ -1938,7 +2028,7 @@ int lfs_mount(lfs_t *lfs, const struct lfs_config *cfg) {
|
|||
return LFS_ERR_INVAL;
|
||||
}
|
||||
|
||||
return err;
|
||||
return 0;
|
||||
}
|
||||
|
||||
int lfs_unmount(lfs_t *lfs) {
|
||||
|
|
@ -1979,7 +2069,7 @@ int lfs_traverse(lfs_t *lfs, int (*cb)(void*, lfs_block_t), void *data) {
|
|||
}
|
||||
|
||||
dir.off += lfs_entry_size(&entry);
|
||||
if ((0xf & entry.d.type) == (0xf & LFS_TYPE_REG)) {
|
||||
if ((0x70 & entry.d.type) == (0x70 & LFS_TYPE_REG)) {
|
||||
int err = lfs_index_traverse(lfs, &lfs->rcache, NULL,
|
||||
entry.d.u.file.head, entry.d.u.file.size, cb, data);
|
||||
if (err) {
|
||||
|
|
@ -2069,7 +2159,7 @@ static int lfs_parent(lfs_t *lfs, const lfs_block_t dir[2],
|
|||
break;
|
||||
}
|
||||
|
||||
if (((0xf & entry->d.type) == (0xf & LFS_TYPE_DIR)) &&
|
||||
if (((0x70 & entry->d.type) == (0x70 & LFS_TYPE_DIR)) &&
|
||||
lfs_paircmp(entry->d.u.dir, dir) == 0) {
|
||||
return true;
|
||||
}
|
||||
|
|
@ -2079,6 +2169,46 @@ static int lfs_parent(lfs_t *lfs, const lfs_block_t dir[2],
|
|||
return false;
|
||||
}
|
||||
|
||||
static int lfs_moved(lfs_t *lfs, const void *e) {
|
||||
if (lfs_pairisnull(lfs->root)) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
// skip superblock
|
||||
lfs_dir_t cwd;
|
||||
int err = lfs_dir_fetch(lfs, &cwd, (const lfs_block_t[2]){0, 1});
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// iterate over all directory directory entries
|
||||
lfs_entry_t entry;
|
||||
while (!lfs_pairisnull(cwd.d.tail)) {
|
||||
int err = lfs_dir_fetch(lfs, &cwd, cwd.d.tail);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
while (true) {
|
||||
int err = lfs_dir_next(lfs, &cwd, &entry);
|
||||
if (err && err != LFS_ERR_NOENT) {
|
||||
return err;
|
||||
}
|
||||
|
||||
if (err == LFS_ERR_NOENT) {
|
||||
break;
|
||||
}
|
||||
|
||||
if (!(0x80 & entry.d.type) &&
|
||||
memcmp(&entry.d.u, e, sizeof(entry.d.u)) == 0) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
static int lfs_relocate(lfs_t *lfs,
|
||||
const lfs_block_t oldpair[2], const lfs_block_t newpair[2]) {
|
||||
// find parent
|
||||
|
|
@ -2119,7 +2249,7 @@ static int lfs_relocate(lfs_t *lfs,
|
|||
if (res) {
|
||||
// just replace bad pair, no desync can occur
|
||||
parent.d.tail[0] = newpair[0];
|
||||
parent.d.tail[0] = newpair[0];
|
||||
parent.d.tail[1] = newpair[1];
|
||||
|
||||
return lfs_dir_commit(lfs, &parent, NULL, 0);
|
||||
}
|
||||
|
|
@ -2130,27 +2260,22 @@ static int lfs_relocate(lfs_t *lfs,
|
|||
|
||||
int lfs_deorphan(lfs_t *lfs) {
|
||||
lfs->deorphaned = true;
|
||||
|
||||
if (lfs_pairisnull(lfs->root)) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
lfs_dir_t pdir;
|
||||
lfs_dir_t cdir;
|
||||
lfs_dir_t pdir = {.d.size = 0x80000000};
|
||||
lfs_dir_t cwd = {.d.tail[0] = 0, .d.tail[1] = 1};
|
||||
|
||||
// skip superblock
|
||||
int err = lfs_dir_fetch(lfs, &pdir, (const lfs_block_t[2]){0, 1});
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// iterate over all directories
|
||||
while (!lfs_pairisnull(pdir.d.tail)) {
|
||||
int err = lfs_dir_fetch(lfs, &cdir, pdir.d.tail);
|
||||
// iterate over all directory directory entries
|
||||
while (!lfs_pairisnull(cwd.d.tail)) {
|
||||
int err = lfs_dir_fetch(lfs, &cwd, cwd.d.tail);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
|
||||
// only check head blocks
|
||||
// check head blocks for orphans
|
||||
if (!(0x80000000 & pdir.d.size)) {
|
||||
// check if we have a parent
|
||||
lfs_dir_t parent;
|
||||
|
|
@ -2162,10 +2287,11 @@ int lfs_deorphan(lfs_t *lfs) {
|
|||
|
||||
if (!res) {
|
||||
// we are an orphan
|
||||
LFS_DEBUG("Orphan %d %d", pdir.d.tail[0], pdir.d.tail[1]);
|
||||
LFS_DEBUG("Found orphan %d %d",
|
||||
pdir.d.tail[0], pdir.d.tail[1]);
|
||||
|
||||
pdir.d.tail[0] = cdir.d.tail[0];
|
||||
pdir.d.tail[1] = cdir.d.tail[1];
|
||||
pdir.d.tail[0] = cwd.d.tail[0];
|
||||
pdir.d.tail[1] = cwd.d.tail[1];
|
||||
|
||||
err = lfs_dir_commit(lfs, &pdir, NULL, 0);
|
||||
if (err) {
|
||||
|
|
@ -2177,7 +2303,8 @@ int lfs_deorphan(lfs_t *lfs) {
|
|||
|
||||
if (!lfs_pairsync(entry.d.u.dir, pdir.d.tail)) {
|
||||
// we have desynced
|
||||
LFS_DEBUG("Desync %d %d", entry.d.u.dir[0], entry.d.u.dir[1]);
|
||||
LFS_DEBUG("Found desync %d %d",
|
||||
entry.d.u.dir[0], entry.d.u.dir[1]);
|
||||
|
||||
pdir.d.tail[0] = entry.d.u.dir[0];
|
||||
pdir.d.tail[1] = entry.d.u.dir[1];
|
||||
|
|
@ -2191,7 +2318,45 @@ int lfs_deorphan(lfs_t *lfs) {
|
|||
}
|
||||
}
|
||||
|
||||
memcpy(&pdir, &cdir, sizeof(pdir));
|
||||
// check entries for moves
|
||||
lfs_entry_t entry;
|
||||
while (true) {
|
||||
int err = lfs_dir_next(lfs, &cwd, &entry);
|
||||
if (err && err != LFS_ERR_NOENT) {
|
||||
return err;
|
||||
}
|
||||
|
||||
if (err == LFS_ERR_NOENT) {
|
||||
break;
|
||||
}
|
||||
|
||||
// found moved entry
|
||||
if (entry.d.type & 0x80) {
|
||||
int moved = lfs_moved(lfs, &entry.d.u);
|
||||
if (moved < 0) {
|
||||
return moved;
|
||||
}
|
||||
|
||||
if (moved) {
|
||||
LFS_DEBUG("Found move %d %d",
|
||||
entry.d.u.dir[0], entry.d.u.dir[1]);
|
||||
int err = lfs_dir_remove(lfs, &cwd, &entry);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
} else {
|
||||
LFS_DEBUG("Found partial move %d %d",
|
||||
entry.d.u.dir[0], entry.d.u.dir[1]);
|
||||
entry.d.type &= ~0x80;
|
||||
int err = lfs_dir_update(lfs, &cwd, &entry, NULL);
|
||||
if (err) {
|
||||
return err;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
memcpy(&pdir, &cwd, sizeof(pdir));
|
||||
}
|
||||
|
||||
return 0;
|
||||
|
|
|
|||
20
lfs.h
20
lfs.h
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* The little filesystem
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#ifndef LFS_H
|
||||
#define LFS_H
|
||||
|
|
@ -46,7 +57,7 @@ enum lfs_error {
|
|||
enum lfs_type {
|
||||
LFS_TYPE_REG = 0x11,
|
||||
LFS_TYPE_DIR = 0x22,
|
||||
LFS_TYPE_SUPERBLOCK = 0xe2,
|
||||
LFS_TYPE_SUPERBLOCK = 0x2e,
|
||||
};
|
||||
|
||||
// File open flags
|
||||
|
|
@ -434,5 +445,8 @@ int lfs_traverse(lfs_t *lfs, int (*cb)(void*, lfs_block_t), void *data);
|
|||
// Returns a negative error code on failure.
|
||||
int lfs_deorphan(lfs_t *lfs);
|
||||
|
||||
// TODO doc
|
||||
int lfs_deduplicate(lfs_t *lfs);
|
||||
|
||||
|
||||
#endif
|
||||
|
|
|
|||
15
lfs_util.c
15
lfs_util.c
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* lfs util functions
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#include "lfs_util.h"
|
||||
|
||||
|
|
|
|||
22
lfs_util.h
22
lfs_util.h
|
|
@ -1,8 +1,19 @@
|
|||
/*
|
||||
* lfs utility functions
|
||||
*
|
||||
* Copyright (c) 2017 Christopher Haster
|
||||
* Distributed under the Apache 2.0 license
|
||||
* Copyright (c) 2017 ARM Limited
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
#ifndef LFS_UTIL_H
|
||||
#define LFS_UTIL_H
|
||||
|
|
@ -12,7 +23,8 @@
|
|||
#include <stdio.h>
|
||||
|
||||
|
||||
// Builtin functions
|
||||
// Builtin functions, these may be replaced by more
|
||||
// efficient implementations in the system
|
||||
static inline uint32_t lfs_max(uint32_t a, uint32_t b) {
|
||||
return (a > b) ? a : b;
|
||||
}
|
||||
|
|
@ -33,10 +45,12 @@ static inline int lfs_scmp(uint32_t a, uint32_t b) {
|
|||
return (int)(unsigned)(a - b);
|
||||
}
|
||||
|
||||
// CRC-32 with polynomial = 0x04c11db7
|
||||
void lfs_crc(uint32_t *crc, const void *buffer, size_t size);
|
||||
|
||||
|
||||
// Logging functions
|
||||
// Logging functions, these may be replaced by system-specific
|
||||
// logging functions
|
||||
#define LFS_DEBUG(fmt, ...) printf("lfs debug: " fmt "\n", __VA_ARGS__)
|
||||
#define LFS_WARN(fmt, ...) printf("lfs warn: " fmt "\n", __VA_ARGS__)
|
||||
#define LFS_ERROR(fmt, ...) printf("lfs error: " fmt "\n", __VA_ARGS__)
|
||||
|
|
|
|||
|
|
@ -27,8 +27,8 @@ void test_assert(const char *file, unsigned line,
|
|||
}}
|
||||
|
||||
if (v != e) {{
|
||||
printf("\033[31m%s:%u: assert %s failed, expected %jd\033[0m\n",
|
||||
file, line, s, e);
|
||||
fprintf(stderr, "\033[31m%s:%u: assert %s failed with %jd, "
|
||||
"expected %jd\033[0m\n", file, line, s, v, e);
|
||||
exit(-2);
|
||||
}}
|
||||
}}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,236 @@
|
|||
#!/bin/bash
|
||||
set -eu
|
||||
|
||||
echo "=== Move tests ==="
|
||||
rm -rf blocks
|
||||
tests/test.py << TEST
|
||||
lfs_format(&lfs, &cfg) => 0;
|
||||
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_mkdir(&lfs, "a") => 0;
|
||||
lfs_mkdir(&lfs, "b") => 0;
|
||||
lfs_mkdir(&lfs, "c") => 0;
|
||||
lfs_mkdir(&lfs, "d") => 0;
|
||||
|
||||
lfs_mkdir(&lfs, "a/hi") => 0;
|
||||
lfs_mkdir(&lfs, "a/hi/hola") => 0;
|
||||
lfs_mkdir(&lfs, "a/hi/bonjour") => 0;
|
||||
lfs_mkdir(&lfs, "a/hi/ohayo") => 0;
|
||||
|
||||
lfs_file_open(&lfs, &file[0], "a/hello", LFS_O_CREAT | LFS_O_WRONLY) => 0;
|
||||
lfs_file_write(&lfs, &file[0], "hola\n", 5) => 5;
|
||||
lfs_file_write(&lfs, &file[0], "bonjour\n", 8) => 8;
|
||||
lfs_file_write(&lfs, &file[0], "ohayo\n", 6) => 6;
|
||||
lfs_file_close(&lfs, &file[0]) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move file ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "a/hello", "b/hello") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "a") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hi") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "b") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hello") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move file corrupt source ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "b/hello", "c/hello") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
rm -v blocks/7
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "b") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "c") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hello") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move file corrupt source and dest ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "c/hello", "d/hello") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
rm -v blocks/8
|
||||
rm -v blocks/a
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "c") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hello") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "d") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move dir ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "a/hi", "b/hi") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "a") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "b") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hi") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move dir corrupt source ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "b/hi", "c/hi") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
rm -v blocks/7
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "b") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "c") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hello") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hi") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move dir corrupt source and dest ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_rename(&lfs, "c/hi", "d/hi") => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
rm -v blocks/9
|
||||
rm -v blocks/a
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "c") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hello") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hi") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
lfs_dir_open(&lfs, &dir[0], "d") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
echo "--- Move check ---"
|
||||
tests/test.py << TEST
|
||||
lfs_mount(&lfs, &cfg) => 0;
|
||||
|
||||
lfs_dir_open(&lfs, &dir[0], "a/hi") => LFS_ERR_NOENT;
|
||||
lfs_dir_open(&lfs, &dir[0], "b/hi") => LFS_ERR_NOENT;
|
||||
lfs_dir_open(&lfs, &dir[0], "d/hi") => LFS_ERR_NOENT;
|
||||
|
||||
lfs_dir_open(&lfs, &dir[0], "c/hi") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, ".") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "..") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "hola") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "bonjour") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 1;
|
||||
strcmp(info.name, "ohayo") => 0;
|
||||
lfs_dir_read(&lfs, &dir[0], &info) => 0;
|
||||
lfs_dir_close(&lfs, &dir[0]) => 0;
|
||||
|
||||
lfs_dir_open(&lfs, &dir[0], "a/hello") => LFS_ERR_NOENT;
|
||||
lfs_dir_open(&lfs, &dir[0], "b/hello") => LFS_ERR_NOENT;
|
||||
lfs_dir_open(&lfs, &dir[0], "d/hello") => LFS_ERR_NOENT;
|
||||
|
||||
lfs_file_open(&lfs, &file[0], "c/hello", LFS_O_RDONLY) => 0;
|
||||
lfs_file_read(&lfs, &file[0], buffer, 5) => 5;
|
||||
memcmp(buffer, "hola\n", 5) => 0;
|
||||
lfs_file_read(&lfs, &file[0], buffer, 8) => 8;
|
||||
memcmp(buffer, "bonjour\n", 8) => 0;
|
||||
lfs_file_read(&lfs, &file[0], buffer, 6) => 6;
|
||||
memcmp(buffer, "ohayo\n", 6) => 0;
|
||||
lfs_file_close(&lfs, &file[0]) => 0;
|
||||
|
||||
lfs_unmount(&lfs) => 0;
|
||||
TEST
|
||||
|
||||
|
||||
echo "--- Results ---"
|
||||
tests/stats.py
|
||||
Loading…
Reference in New Issue